Maximizing Availability and Durability
Purpose
Adama currently suffers from single host failures and potential windows (5 to 10 minutes) of data loss due to the design. Single host failures will result in documents being unavailable until operator intervention (12+ hours at the moment). This document outlines applying the established literature https://raft.github.io/raft.pdf to the Adama Platform.
Design Goals
The primary goal is to introduce replication to the data model used by Adama such that single host failures within a partition (1) do not impact availability, (2) allow near instant recovery from host failure (under 30 seconds), and (3) cause zero data loss.
Furthermore, we will assume that we wish to be able to split and join partitions to handle chaotic traffic; this speaks to partition design being rainbow striped such that a machine may be part of many partitions and data is bound to partitions rather than machines.
Non Goals
Partition management is a non-goal and we will assume a static config that is polled. This allows us to start with a generated one-time config at cluster stand-up. By using polling to determine membership, this allows operators to change the config and be adjusted live. This allows us to skip how partitions are managed for now.
50,000 foot view
The essential design is that we are going to preserve the monolithic design of Adama such that data is colocated on the existing adama compute node. The macro change is the introduction of partitions which form a durable state machine via RaFT. We rainbow stripe the partitions across machines as this allows heat to dissipate when heat induces a failure instead of a cascading fall over.
Each partition forms a sub-mesh within the fleet, so care must be taken to minimize the number of meshes a host is a member of; since this falls under partition management, we will ignore this and make the mesh construction lazy.
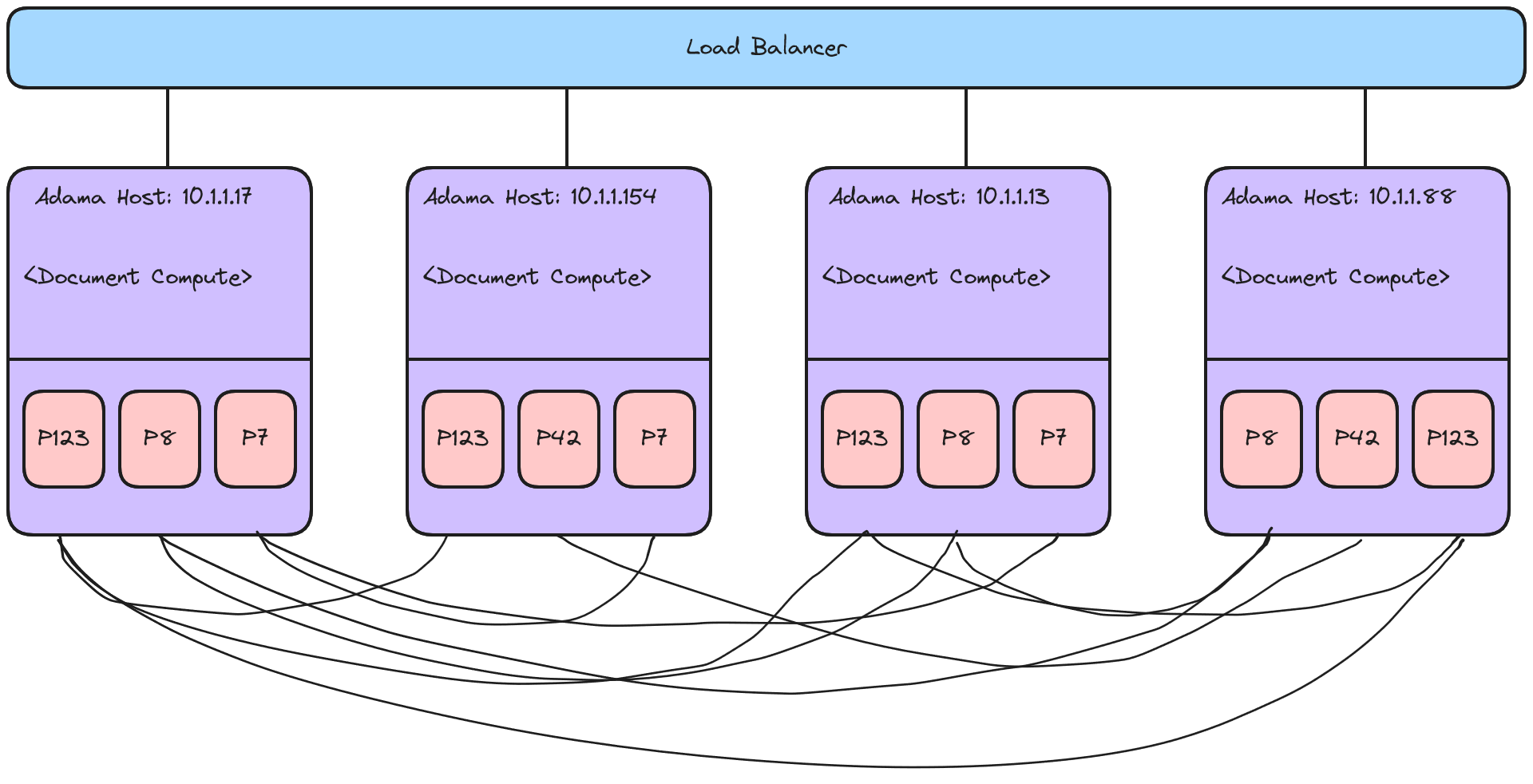
Diving into this requires addressing these questions: (1) What is the data model of each partition, (2) What novel aspects and implementation details are beyond the existing literature, (3) How will hosts react to leadership failures in both the load balancer and non-leaders, and (4) Preventing zombie leadership behavior.
Details
Data model with anti-entropy
We are going to exploit the co-location of Adama's compute with storage to infer that the storage burden per host is going to be substantially less than traditional storage engines and databases. The proof is simply noting that Adama's primary bottleneck is memory which is six orders of magnitude less than storage (32 GB vs 2 TB). If the average document size is 4KB, then this means 8.4 million documents will reside on a host at maximum. If each document key and metadata is bound by 512 bytes, then the maximum size of an index is 4GB.
Gossiping the entire index is not acceptable as it would take 32 seconds at 1 gbps. Instead, we utilize 64 partitions to segment the 4GB into 64 MB chunks. This allows us to smear the workload over time, but it doesn't reduce the total workload.
We reduce the workload by introducing a merkle tree per partition. Each partition at maximum would have 131K documents in it, so if we use 256 buckets then 512 documents are in a bucket. If each document has 512B of gossip metadata, then each bucket gossip results in 262KB of data exchange assuming no compression. At 1gbps, this means gossip of a single bucket would take 1 ms. Instead of a traditional hash tree, we can simply send all 256 buckets and their hashes for a rough cost of 8KB. The purpose of the merkle tree is that when nothing bad has happened, then repair is effectively free. And, should a repair be interrupted, the merkle tree allows resumption.
Gossip and the buckets allows the machine to determine when a document's log is either not present or behind. When a host detects a document is behind, it will pick a random peer and pull committed entries for the documents detected using the local sequencer to the peer's sequencer.
The burden of repair can then be studied operationally. For example, when a new host is introduced to the fleet then we can use the rainbow striped partitions to bring a partition online one at a time at 262KB overhead to detect new work. Since this is a new host, the entire partition needs to be rehydrated. If the average document size preserves 1,000 deltas and each delta is roughly the square-root of the document then we can guess the work load for a bucket is 32 MB at most. A full recovery of a bucket will take be roughly 250ms, and the recovery is tolerant of partial failures. Full partition recovery will take 16 seconds. Full machine recovery will take 17 minutes (32MB * 8.4 million) due to the logs, but here is where we can observe an interesting gotcha.
If each machine permits only 1 TB for log storage, then that permits only 32K (@ 32 MB/document) documents instead of 8.3M documents.
FUCK...
Thus, each partition would have 512 documents in it. And the merkle tree would have 2 documents in a bucket. This makes everything better, but the open question now is how does the overhead balance out.... hrmm
Novel aspects and implementation details
The big departure from traditional RAfT designs is breaking out the leadership write to healthy members (followers that are caught up) versus repairing a sick member (followers not up to speed) via anti-entropy. The primary reason to do this is simplifying the repair mechanism when leader writes start to fail and enable peers to contribute to recovery, and the repair mechicniams can leverage multiple machines easily.
Therefore, the role of RAfT is reduced to simply a durability buffer which ensures a consistent write to the gossip'd data structure. This means that when everything is going well, the write is spread to the follows perfectly and committed. When a leader detects a failure, it will revert and issue a catastrophic failure to the document. We want to minimize catastrophic failures