Replication
The design of replication is such that some message needs to be replicated to another service which is expressed via the syntax within the document or a record definition.
replication<$service:$replicationMethod> $statusVariable = $expression;
This signals that the given expression should be replicated to the intended service on the given method. It is the responsibility of the service to define how replication is made idempotent as replication ought to happen every time the expression changes (with some operational knobs to limit and regulate replication, of course). This feature requires careful design such that the third party service is kept in sync. However, an element that will not be discussed is the operational side around changing either $service or $replicationMethod. Those will be considered out of scope for now.
As an example service, consider a search service to provide cross-document indexing. This service implementation can pull information from $expression along with the space and key name to define an idempotent key. That is, whenever the $expression changes, we will need recompute the idempotent key.
idempotentKey = deriveIK($expressionValue, $space, $key)
This key is then used against the service to ensure retries don't recreate new entries as we expect failures to happen for a multitude of reasons. The service then has two primary async interfaces to implement: PUT($idempotentKey, $expressionValue) and DELETE($idempotentKey). A tricky element at hand is handling idempotent key change, and the way to handle it is to issue a delete against the old $oldIdempotentKey prior to putting a new $newIdempotentKey
As such, this requires a persistent state machine which will embed within the document to keep track of the state. We will call this RxReplicationStatus.
Deriving the state machine
We have to model the state machine such that:
- the key may change at any time
- the value may change at any time
- we expect and respect the other service may be unreliable (non-zero failure rates) and non-performant (high latency)
- we only want one operation outstanding at any time for any single replication task
- failures may happen within and across hosts (i.e. a request is issued, machine failures, another request starts on another machine)
So, we start by defining an intention (or plan) of what needs to happen based on the current state. The operations at hand are PUT and DELETE, so part of the state machine is going to be (1) a copy of the key that is being interacted with remotely and (2) the hash of the compute expression. We are going to use a simple poll() model such that we can write a function to poll the state machine.
public void poll(...) {
// inspect the state of the world to create a new intention
// compare that intention to the the current action taking place
}
This is sufficient to create an intention as we will compute (newKey and newHash) to compare against the existing key and hash.
| key | hash | intention |
|---|---|---|
| null | - | PUT |
| != null && newKey == null | - | DELETE |
| == newKey | != newHash | PUT |
| != newKey | - | DELETE |
| == newKey | == newHash | NOTHING |
This intention is a goal, but due to high latency we need to model what is happening concurrently as either (1) nothing is happening against the remote service, (2) a PUT is inflight, (3) a DELETE is inflight. Thus, we model what is currently happening via a finite state machine.
| state | description | suspect remote key is alive | serialized as |
|---|---|---|---|
| Nothing | Nothing is happening at the moment | key != null | Nothing |
| PutRequested | A PUT has been requested | true | PutRequested |
| PutInflight | A PUT is executing at this moment on the current machine | true | PutRequested |
| PutFailed | A PUT attempted execution but failed | true | PutRequested |
| DeleteRequested | A DELETE has been requested | true | DeleteRequested |
| DeleteInflight | A DELETE is executed at this moment on the current machine | true | DeleteRequested |
| DeleteFailed | A DELETE attempted execution but failed | true | DeleteRequested |
Each state has a serialized state which requires modelling disaster recovery since the transient network operation will be lost during a machine failure. It is unknown if the network operation completed, so we need to try again on the new machine. This will require bringing $time as part of the state machine such that we can ensure the PUT and DELETE time out for a retry. At this point, the state machine has (1) state, (2) key, (3) hash, (4) time.
There is also a need for a transient boolean executeRequest to convert PutRequested to PutInflight and DeleteRequested to DeleteInflight. This boolean is responsible for executing the intended network call and allows us to implement the timeout. The service then must define a timeout such that a stale PutRequested can be converted to PutInflight This does require a new state machine operation called committed which we examine here.
public void poll(){
//..
if(state==State.PutRequested){
if(!executeRequest&&time+TIMEOUT<now()){
executeRequest=true;
}
}
}
public void commited() {
// ..
if(state==State.PutRequested && executeRequest) {
executeRequest = false;
state = State.PutInflight();
put(...);
}
}
This committed() phase is executed once the document's state is durable. Breaking up the PutRequested and PutInflight allows for the intention against the remote service to be durably persisted to allow recovery. We must do this so leaks don't happen.
The emergent state machine of what is happening right now is:
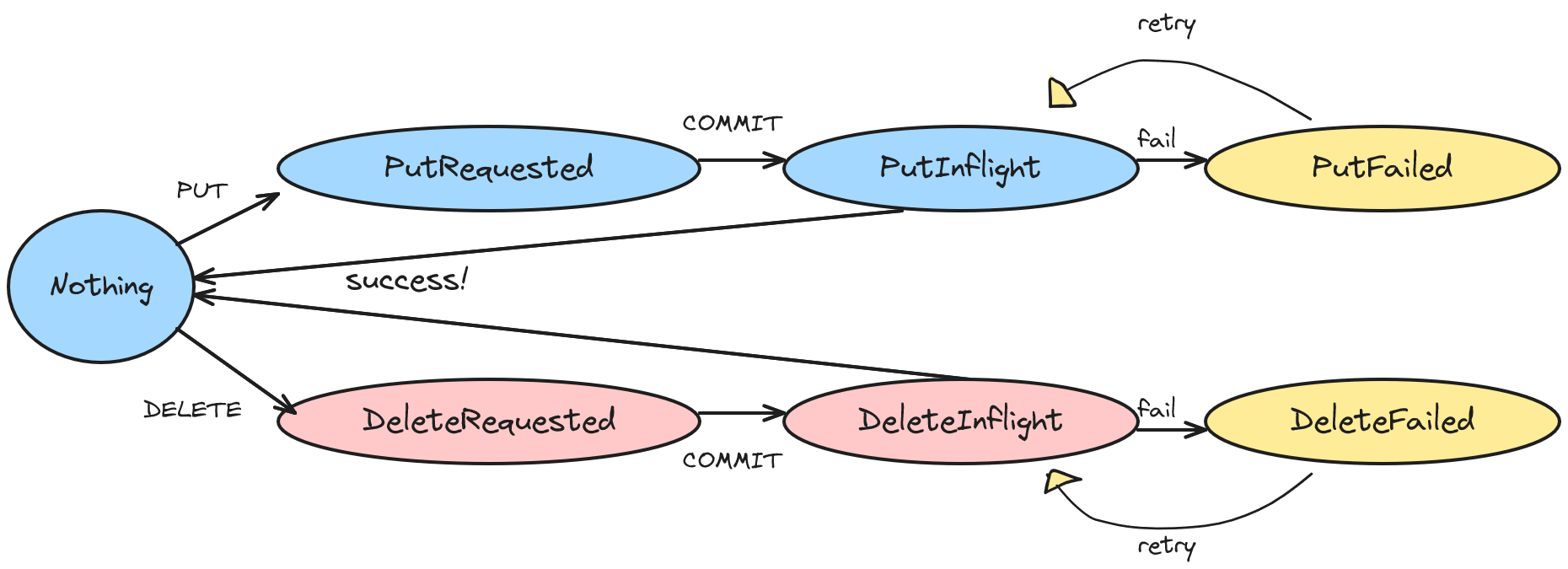
Finally, the goal is to cross the intention with the state.
| state | intention | behavior |
|---|---|---|
| Nothing | PUT | transition to PutRequested and capture the key, hash, time |
| PutRequested | PUT | do nothing |
| PutInflight | PUT | do nothing |
| PutFailed | PUT | do nothing, if key == newKey, capture hash and the new value |
| DeleteRequested | PUT | do nothing |
| DeleteInflight | PUT | do nothing |
| Nothing | DELETE | transition to DeleteRequested and capture the key, time |
| PutRequested | DELETE | do nothing |
| PutInflight | DELETE | do nothing |
| PutFailed | DELETE | do nothing |
| DeleteRequested | DELETE | do nothing |
| DeleteInflight | DELETE | do nothing |
| DeleteFailed | DELETE | do nothing |
Handling PutFailed and DeletedFailed
In both instances, these are bad but DeletedFailed is potentially catastrophic.
Ultimately, we are going to embrace a philosophy of infinite retry with a relaxed exponential backoff curve. That is, we want a reasonable and aggressive expontential backoff for the first few seconds, then it gets slower and slower faster and faster to reach a terminal window of 30 minutes to an hour.
Since the time between attempts during a failure may be intense, we ask if we can short-circuit the process when the $expression changes. If the key is stable, then we augment the above table to pull a new value during PutFailed.
Scenarios handling
Key Changed
When a key changes, a delete will be issued which when successful will transition to Nothing. The Nothing state will trigger a PUT.
Value Changes
When the value changes, this will be detected and trigger a new PUT
Poor Service Reliability
Infinite retry and expontential backoff will provide eventual synchronization assuming no poison pills. The platform will monitor for poison pills.
Poor Service Latency
Rapid changes will change only the intention while the remote service is working. The state machine ensures only one action happens against the remote service.
Machine failure
If a machine failures, then the document will be resumed on a new machine. The timeout value is used to create a period of time to not touch the remote service. As such, the old machine, if it comes back to life then there is a problem. However, future data service will require Raft thus ensuring the committed() signal is never generated on an old machine for old documents.