Overview
Adama is many things, and it is hard to nail down one precise thing. However, Adama is a fundamental rethink of how to build infrastructure that brings people together. The aspiration is that Adama is simple, becomes well understood, and changes the world. This is why Adama is 100% open source.
Since "What is Adama" is hard to pin down, you can gain insights by reading Adama as a ?. Adama has a history in board games which you can read more about, and you can learn more from the requirements that drove Adama's engineering.
You can also jump in today with the CLI by following the tutorial.
Concepts of Adama, the platform
This diagram relates the critical components at 10,000 foot altitude.
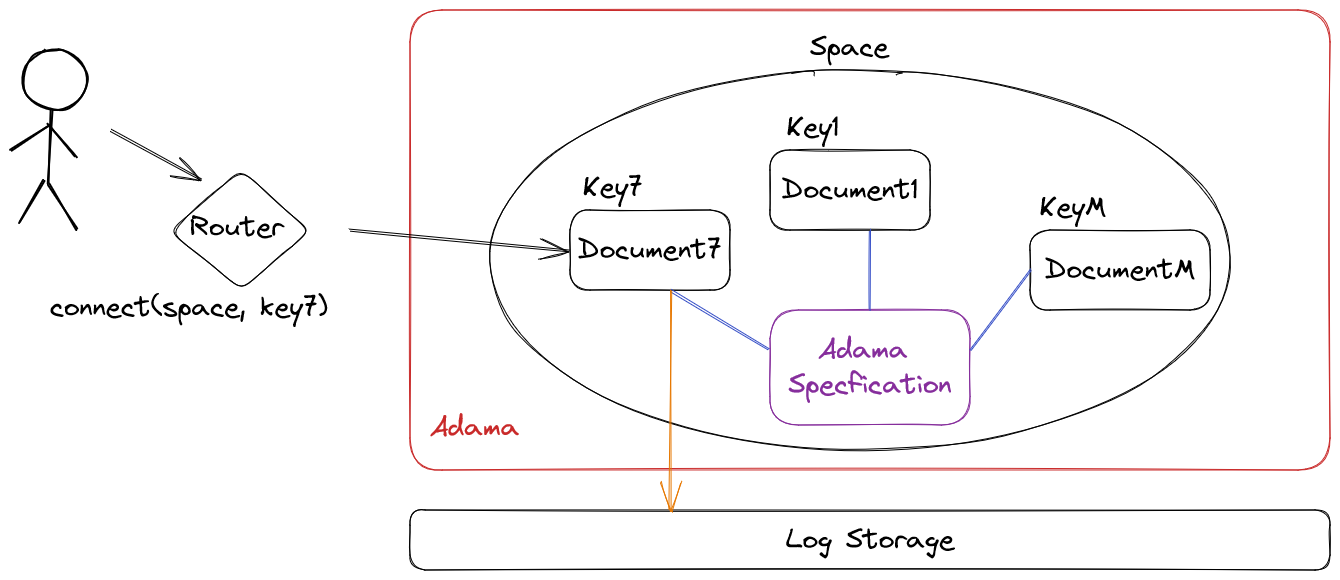
Authentication
Users have to present an identity token to talk to Adama. The common case is the identity token is a JWT token signed by Adama or your private key. There are special tokens prefixed by "anonymous:" (for example, "anonymous:AgentSmith") to allow random internet visitors into a document.
For more information, see the authorization guide.
Router and the API space
The router's primary function is to locate documents and proxy connections between the user and the document, and Adama acts as a document store that can handle an infinite number of documents. Each document is identified by a key and a space.
The main API allows users to connect to documents and then send those documents messages. See the API reference for details about the API.
Spaces
A space is collection of documents and the configuration, behavior, and mechanics of the space are all determined by an Adama specification via the Adama language. The Adama language allows developers to expressively organize data with objects and tables, leverage full ACID transactions to mutate documents, expose computations via reactive formulas with integrated SQL, protect data with privacy logic, coordinate people with workflows, limit client data with viewer dependent queries, leverage temporal distubances, expose web-fetchable resources, and more!
Each space is identified by a globally unique name. Space names must have a length greater than 3 and less than 128, have valid characters are lower-case alphanumeric or hyphens, and double hyphens (--) are not allowed.
Documents
An Adama document is a giant JSON document with a change history. The Adama language allows developers to change the document (among other things) and those changes are bundled together into a transaction and written to a log.
Each document is identified by a key that is unique within the owning space. Document keys must have a length greater than 0 and less than 512; valid characters are A-Z, a-z, 0-9, underscore (_), hyphen (-i), or period (.).
Log storage
Document changes are recorded using JSON merge as the patch operation. Any changes made to the documents are stored as patches in the log storage, which ensures that the system remains consistent and reliable. The log storage also plays a crucial role in determining the overall performance of the system, making it an essential component of Adama.
Requirements driving Adama (the birth of Board Game Infrastructure)
Since answering "What is Adama" is hard, let's start with the requirements that drove Adama in the first place as that provides essential clues to why exists.
This all started after seeing TVs placed within tables to play games (like here , here , or here). These table are pretty neat, so I thought I would build one myself. Low and behold, I decided to focus on the software aspect to build a digital version of battlestar galatica (BSG).
The core thesis of having the TV be the board is that this enables easier setup and teardown, rule enforcement, rule automation, rich media integration, no lost pieces, and more. Furthermore, by lowering the setup cost, it enables a quick play through to teach the rules and tutorials can be used to speed up the players' understanding of the game.
Since there is private state within BSG, I would need to bring people into the TV with their device. Fortunately, everyone these days has a smart phone, so the TV would need to be a server. We must contend with networking to deal with multiple devices owned by different people of varying degrees of capabilities.
Requirement #1: We need to deal with networking up-front.
As an ideal, players should be able to continue play during a network outage. Power outages can be handled with a battery. We must allow players to be able to host locally without any cloud nonsense.
Requirement #2: Games should be hostable locally.
Sadly, home networking is a bit of a mess and outage are relatively a rare event. For easier game play start, the cloud is a fantastic option for 99% of the time.
Requirement #3: Games should be hostable on the cloud.
The cloud opens up many possibilities, and people can play with multiple TVs distributed across various homes. This would allow couples to share a TV while playing on their phones with friends in another state. Online play opens more opportunities for more players to connect without the hassle of geography or existing relationships.
Requirement #4: Games should behave like a virtual room.
Connectivity to the cloud or local network can be spotty, or players can take exceptionally long time per turn; thus, players should be able to jump in/out easily.
Requirement #5: Players should receive notifications when it is their turn to take an action.
Some players are more social rather than competitive, so mistakes are common and easy enough to do in person with a physical board.
Requirement #6: Undo/rewind are important for social-driven players
Since some games have minimum player requirements, it may be interesting to include a bot to learn the game mechanics. Furthermore, games are best when balanced fairly well, and there should not be any exceptionally obvious advantages of initial choices.
Requirement #7: Games should support A.I. to play and seek balance.
At this point, the user requirements are leaning us towards some technical decisions. For instance, we need a client/server model due to the cloud, and we skip any kind of decentralized architecture because of privacy.
Requirement #8: We need privacy between players such that game integrity is maintained.
The client/server model requires a protocol, and the state complexity of some games can be staggering. The mental model however can become much simpler if we see the controllers and TVs as thin/dumb clients similar to a virtual PC or game streaming service. When you have a thin/dumb client, the server is responsible for everything. Here, the server picks up the role of dungeon master and then asks players questions directly.
Requirement #9: Streams vastly reduce the client complexity.
Unfortunately, the modern cloud doesn't play well with streams for a variety of reasons. See woe of websocket for more details. Specifically, the cloud works really well with request/response and databases. A process within the cloud may terminate for a variety of reasons: deployment, kernel upgrade, machine migration, capacity management, host failure, etc.
Requirement #10: The stream must be reliable over failures.
Host failures can be accounted for in a variety of ways (VMs that float around), but the developer situation is important too. As a developer play tests a game and pushes the boundary on all the rules, it is desirable to be able to upgrade/hot-reload the code. This ability to hot-reload requires the need to rewind state to avoid the quadratic state build-up.
Requirement #11: The stream must be reliable over code changes.
Some games adopt house rules, and the server side should be fairly easy to mod or change in a social setting. The client side should be a mostly dumb projection of the client.
Requirement #12: The entire infrastructure should be represented by a single file.
That's a lot, and Adama addresses all these challenges.
The Basics of Adama
Hello there! Welcome to the introduction of the Adama Platform book. In this chapter, we are going to explore the core idioms and language of what Adama is and how it helps you.
So, what is the Adama Platform? Well, we could kick this off with some buzzword bingo by saying that the Adama platform is an open-source reactive server-less privacy-first document-oriented compute-centric key-value store acting like a platform as a service, but that doesn't communicate much (or, does it?). However, we have to start somewhere, so let's tear down those buzzwords with more words.
Let's start with document orientated key-value store. Adama stores documents, and documents are identified via a key (hence the key-value). Documents are organized by a space (which is similar to the bucket concept used by S3 except with a more mathematical feel). Adama has variants of the four big CRUD operations, but there are notable differences which make the Adama platform unique. Deconstructing the CRUD operations is the best way to teardown the buzzword bingo.
Creating
The first notable aspect is that Adama documents are created on the server via a constructor. This constructor is defined with code that is bound to the space holding the document. Wait, what? This is where the compute-centric comes into play as each space has code as config. All documents within a space share the same Adama (the language) code, and the Adama code defines the document schema, logic for transformation, access control, and more. This is why the name space was chosen over bucket because buckets can only have fixed config while spaces have infinite potential.
For a clear example, the below code illustrates valid Adama code which we will tear down.
// static code runs without a document instance
@static {
// 1. a policy which is run to validate the given user can create the document
create {
return @who.isAdamaDeveloper();
}
}
// 2. the document schema has a creator and an integer named x
private principal creator;
public int x;
// 3. the constructor is a message named by the document
message ConsXYZ {
int x;
}
// 4. connect the constructor message to code
@construct (ConsXYZ c) {
creator = @who;
x = 100 + c.x;
}
Admittedly, this is a lot of ceremony to get a document that looks like:
{"x":123}
when constructed with a message like
{"x":23}
However, this document contains (1) an access control mechanism for who can create a document, (2) a document schema with privacy as a first class citizen, (3) a message interface for validating input structure, and (4) logic to construct the state of the document.
As a rule, documents can only be created once and race conditions go to first creator. It's worth noting that the document's state is different from the state used to construct it which enables developers to think in their domain rather than the document's schema. This is very similar to Alan Kay's original thinking around object-oriented programming and Carl Hewitt's actor model.
Reading
Once a document is created, documents can be read by connecting to the document. This requires further Adama code because there is a need to gate access to the document, and we append this code to the above code.
// 5. gate who can connect to the document
@connected {
return @who == creator;
}
This will allow people to connect or not. The reason we say connect instead of read or get is because we establish a long-lived stream between the client and the document which allows changes to flow from the document to all clients with minimal cost; this explains the reactive buzzword.
Updating
Updates to the document happen by sending messages to the document via channels; channels are basically procedures exposed to clients. For example, we can open a few channels to manipulate our document in various ways.
message Nothing {}
message Param { int z; }
channel square(Nothing n) {
x = x * x;
}
channel zero(Nothing n) {
x = 0;
}
channel add(Param p) {
x += p.z;
}
Messages will hit a document exactly once, run the associated logic, change the document state, and all connected clients will reactively receive a change to update their version of the document. Access control is possible per channel, but it is worth noting that only connected clients can send to a document (by default).
Deleting
Deleting happens from within the document via logic within a message handler.
channel kill(Nothing n) {
if (@who == creator) {
Document.destroy();
}
}
Or, there is an API "document/delete" which allows creation from the outside which will invoke the @delete event.
@delete {
return @who == creator;
}
The core motivation for this is that access control for deletion requires business logic. Since Adama documents can run code based on time passing, this also enables documents to self-destruct.
Buzzword Bingo Summary
With the CRUD operations laid bare, we can analyze the buzzword bingo aspects in a table:
| Buzzword | Translation |
|---|---|
| open-source | Yes, all the source for the platform is hosted on Github |
| reactive | The connection from client to server uses a stream such that updates flow to client as they happen |
| server-less | The servers are managed by the platform, and developers only have to think about keys and documents |
| privacy-first | The language has many privacy mechanisms that happen during document schema definition enforced during run-time. It's entirely possible for the document to hold state that is never readable by any human without hacking. |
| document-oriented | Adama maps keys to values, and those values are documents |
| key-value store | Adama use a NoSQL design mapping keys to values |
| platform as a service | Adama provides the trinity of compute, storage, and networking which is enough to build many products. Adama is designed to pair exceptionally well with a web browser. |
So, how does this help? What is Adama's value proposition?
This is the big question. At core, Adama takes the trinity of the cloud: compute, storage, and networking and bundles them into one offering. The value proposition is thusly multi-faceted depending on various markets:
- Jamstack developers are able to hook their application up directly to the Adama platform such that privacy, security, query, and transformation are provided out of the box.
- Game developers can leverage Adama platform to act as a serverless platform for both a game lobby and a game server (The history of Adama starts with board games).
- Any website can integrate Adama as a durable and reliable real-time service for chat, presence, web-rtc signalling, and more without managing servers.
Beyond making development easier, business operations is further aided by having a tunable history of changes to the document available which makes auditing changes easy as well as having a universal rewind.
Adama as a ?
When I worked at Amazon S3, there was a meme on many office walls of the form "S3 as a _____" with a long list of answers. S3 is heavily abused because it is simple, and this is a fantastic thing. Well, it's also frustrating as that abuse could often lead to late night pages. I am aspiring to keep Adama simple, but I've had a tough time answering "What is Adama". Instead, I'll provide a tsunami of answers in the form of "Adama as a ____".
Adama as board game infrastructure
Board games is where Adama was spawned from which is why the most myopic use-case for Adama is first. However, it's worth thinking about as it sets context for all the other scenarios. The motivating question was how to get control of all the state and logic of building a fantastic board game: Battlestar Galactica (BSG).
This started by taking control of all the game state with a domain specific language. By code-generating the state structures, the state could be easily transactionable such that snapshots and undo become possible features. With that as a foundation, a collaborative framework could be built such that document state could easily replicate to players. However, many games are competitive which requires privacy. The moment privacy became a concern for the domain specific language was a feature cascade as the language became mostly turing complete.
As the language to transform the document emerged, so to moved all the board game logic. Sitting in a private place is a complete back-end for BSG which I can't release (sad face).
Adama as a head-less Excel
The interesting thing is that privacy of state also begs the question of how to have private computations for individual viewers, and this injected reactivity into the language which was yet another productivity boon which made board games exceptionally easier to build.
The moment you have reactivity, you have the foundation that makes Excel powerful. Suddenly, computing is more accessible and Adama greatly simplifies the burden of building multiplayer experiences.
All you have to do is accept messages, change the document, and computational changes flow to users in a differentiable form.
Adama as serverless multiplayer game hosting
There is a spectrum of multiplayer experiences from board games to MMOs or FPS, and Adama can provide infrastructure for the metaverse where all games share common infrastructure. Game developers can focus on their game logic within Adama and build exceptional experiences using any game engine.
Adama as a low-code collaboration storage and networking engine
A trivial consequence of bringing people together around board games is that normal applications benefit from the investments. Whether an application requires conflict-free replicated data types or operational transforms, Adama provides a medium for applications to share state via a document abstraction. All the burdens of networking, synchronization, and reliable communication are simplified as Adama steps in as a message broker and document store.
Beyond sharing state, computations allow that state to become much more than dead bytes.
Adama as a real-time data store
Adama can be used to build publisher/subscriber systems, presence, live-anything, games. Adama leverages a socket-first approach because reality is real-time, and goal of having games on Adama means gamer demands will drive the platform towards excellence.
Adama as a SMB application provider
With Adama providing both state and compute along with a fundamentally simpler networking idiom, entire applications can be built with just Adama as the back-end. The beauty of these apps is that they don't require complex setups nor configuration. Simply point a UI at a document, and boom you have an app which you can host on the Adama Platform or on-site with your own machines.
It's worth noting that a document within Adama can be massive (as large as the Java heap) because state is persisted via change deltas, and this can scale up to many businesses for their entire lifetime.
Adama as a multi-tenant SMB platform
Since a single document can be used to power an entire application, Adama allows businesses to spawn off clients within their own documents. As most tenants fit within a single machine, they get fantastic properties around data and privacy regulations since the model is easily isolated from other businesses across different geopolitical boundaries.
Adama as a garbage collecting storage proxy
Blobs of data can be attached to an Adama document, and these blobs are called assets (which can be thought of as attachments). These blobs are stored within Amazon S3. As documents change over time with assets coming and going, Adama presents a unique opportunity to precisely control storage by garbage collecting assets against what is stored in the Adama document's history.
Adama as a web hosting provider
Since Adama has a web-server built-into it (for websockets and assets), it was low-hanging fruit to connect HTTP to an Adama document. This is a work in progress, but the vertical integration of the Adama platform will include many of key features required to host both static sites and then provide dynamic services.
Adama as a web hook listener
Since Adama supports HTTP verbs routed to documents, various services can talk to Adama like twilio, discord, or slack. Any webhook provider can feed data into an Adama document.
Adama as a massively scalable "real-time" data-base
As a future possibility, Adama can support a large number of writers (~1K) with infinite readers having personalized views. This is possible due to the fact that Adama documents are tiny databases which emit change logs, and change logs can be shipped across regions naturally. The moment you have a replication topology built from change logs, you can achieve infinite read scale.
Adama as a cron-service
Each Adama document has a state machine loop which can be leveraged to sleep for periods of time, do stuff, and then go back to sleep with a timer to wake up again.
Adama as a workflow coordinator
Adama can reach out to people and await a result. This essential feature for board games allows coordination between customers and staff for something like order fulfillment. A small restaurant could be backed by a single Adama document such that customers place orders, staff are then alerted about the order, and document can block until the staff acknowledge the order.
Adama as a personalized queue
The state machine loop is fundamentally a queue which can be leveraged to do stuff over time such that a mainline path is unblocked. Instead of a massive queue for an entire enterprise, the queue is per document such that precision and insight is available.
Adama as a durable application gateway
Adama can call other services in a reliable manner and durable manner. Beyond allowing Adama to broker a request to another back-end, it can make multiple requests to multiple back-ends without worry of partial failure. This means that Adama prevents torn-writes as Adama has a state machine and a queue to broker the idempotent requests.
Adama as an edge compute serverless function
Adama provides arbitrary almost-turing-complete capabilities, and as such can be used to host both stateful and stateless functions which do things. With massive scale potential, documents can be replicated close to users such that the associated behaviors can be executed very quickly.
Adama as a privacy-aware CDN
Adama providing HTTP, assets as arbitrary blobs of data, and massive scalable potential enables Adama to act as a privacy aware CDN such that resources are not blindly cached at the edge for any passerby lucky enough to get a URL. Instead, the CDN can execute privacy logic close to users such that assets are vended securely.
Adama as a "bit much"
At this point, Adama is looking up from a capabilities perspective. Clearly, there has been a tremendous amount of scope creep, but many of these aspects are consequential of having a turing complete language and sane data model.
Tuturial: Zero to Hero
Let's get hands on with Adama!
The key steps are going to be
- Installing the CLI tool which is the primary way to interact with the Adama platform. This tutorial will help you understand the dependencies and validate that the tool is appropriately setup.
- Initializing your developer account will get you on-boarded to production Adama fleet. This tutorial will walk you through account creation.
- Kick starting an app will get you started with a template for a web app. This tutorial will create a space and seed your local developer environment.
- Add a table will walk through creating a table, adding data into the table, reading data from the table. This tutorial will walk you through the basics of data flow.
- TODO
Installing the tool
First thing you need to do is install Java. Either use your distribution's version of Java 17+, or please refer to Oracle's website for how to install Java 17. You can check that you ready when the command:
java -version
shows something like
openjdk version "17.0.7" 2023-04-18
OpenJDK Runtime Environment (build 17.0.7+7-Ubuntu-0ubuntu122.04.2)
OpenJDK 64-Bit Server VM (build 17.0.7+7-Ubuntu-0ubuntu122.04.2, mixed mode, sharing)
That's all you need for Adama to work. Once Java is working, you can download the latest jar using wget download directly from production (note: it requires a reasonable connection speed or it will timeout)
wget https://aws-us-east-2.adama-platform.com/adama.jar
or (if you lack wget)
curl -fSLO https://aws-us-east-2.adama-platform.com/adama.jar
Then, you can run the jar to validate it runs. The help is discoverable such that you can probe the tool via
java -jar adama.jar
The next step is to initialize your developer account.
Initializing your developer account
java -jar adama.jar init
Please note the notice about early access!
This will then prompt you with a blurb of text that outlines that providing your email will be implicit acceptance to Adama's terms, conditions, and privacy policy. You should read them!
Once we have your email, we will send you a verification email with a code. Please copy and paste that code into the terminal, and your account will be setup.
Oh, and if you want to revoke other machines, then this is a great time to do it by inputting Y when asked to revoke. This ability to revoke is a security feature if you lose a laptop or work from an insecure machine and want to secure your account.
This tool will drop a file (.adama) within your home directory to act as your default config. You can, of course, override this with the --config parameter.
For now, let's move on towards kick starting a web application...
Kickstart a web app
The fastest way to get started with Adama is to kick start an application from a template. Run the jar via
java -jar adama.jar kickstart
It is going to ask for a template, then type webapp and hit enter. Once you give the tool a template, it is going to ask for a space name. This space name is an organizational concept for documents stored within Adama, and you can learn more via core concepts of Adama.
The space name you use should be globally unique, so enter a name like mywebapp42 or a-space-for-me123; please use a good name if you plan on sharing this project with others. Once you hit enter, it is going to create the space and create a directory using the chosen space name. That's it!
Now, let's dive into the generated code.
cd mywebapp42
find
Will produce a nice list of files which we will walk through now.
| file | description |
|---|---|
| backend/* | as you group, you'll want to organize your adama specification by breaking it up into multiple files |
| backend.adama | the main file to start with and has been populated with code from the template; this fill will be responsible for including other files via @import top level definition |
| frontend/*.rx.html | this will contain the RxHTML files used to build the web experience |
| local.verse.json | configuration for the local devbox |
| README.me | A place to put notes, and this has been seeded from the tool. Please read it! |
With the directory organization available, run the devbox:
java -jar ../adama.jar devbox
Now navigate your browser to http://localhost:8080, and you'll have a local sandbox for changing the *.rx.html and *.adama files. Note, changes to the *.adama files are reflected instantly while changes to the *.rx.html files require a full screen refresh (F5) in the browser.
With the basic shell, let's build a product
Add a table
Before we add a table, register your email and password to login. Registration will create an identity unique to the document, and you can read more about authentication! Once you have registered, we can now connect to the document. Since the webapp demo doesn't have a forgot password feature, please don't lose that password!
So, now, let's add a table. However, this is putting the cart before the horse and we need a mission! We are going to create a contact support tool which allows users to register for and ask questions about their service. Since we already have the user's email, we primarily need to record a message and some kind of response from the service provider when it is provided. We first create record to collect.
record SupportTicket {
public int id;
public int user_id;
public string request;
public int responder_id;
public bool responded;
public string response;
}
With the SupportTicket in hand, we create a table to hold the records.
table<SupportTicket> _tickets;
The underscore (_) is not needed, but it has emerged as a useful convention because tables are always private. With the table, we now create a message for a user to create a ticket.
message CreateTicket {
string request;
}
And then we create a channel to accept the message from the user to write into the table.
We write this using two different approaches and then compare and contrast.
First, we simply ingest an anonymous message with the data at hand.
This requires finding the user's id by looking up within the template's _users table by the principal against the sender of the message (denoted by @who)
channel create_ticket_uhmmm(CreateTicket ct) {
if( (iterate _users where_as x: x.who == @who)[0] as user) {
_tickets <- {user_id:user.id, request:ct.request};
}
}
While this works, this has the disadvantage that adding a new field to the record and message now requires updating create_ticket_1. Instead, we want to simply ingest the data immediately and then patch it.
channel create_ticket(CreateTicket ct) {
if( (iterate _users where_as x: x.who == @who)[0] as user) {
_tickets <- ct as ticket_id;
if( (iterate _tickets where id == ticket_id)[0] as ticket) {
ticket.user_id = user.id;
} else {
// impossible! but... in case
abort;
}
}
}
This has the advantage that a field added to both the SupportTicket and CreateTicket types will flow because the ingestion <- operator is an effective merge of the right hand side into the left hand side.
We can test this by simply exposing all the tickets via a formula;
public formula tickets = iterate _tickets;
Once you save this (and there are no errors in the devbox), you can go to [http://localhost:8080/], sign in, and then click the little wifi icon in the bottom right. This will bring up the debugger where you can use the form to inject data directly into the backend by calling a channel. Have fun playing with the debugger.
Let's update the /product page by editing the frontend/initial.rx.html file and changing the /product page to
<page uri="/product">
This is the product!
<connection use-domain name="product">
<ul rx:iterate="others">
<li><lookup path="email" /></li>
</ul>
<table>
<tbody rx:iterate="tickets">
<tr><td><lookup path="request" /></td></tr>
</tbody>
</table>
</connection>
</page>
This will iterate over the tickets and show the request in a table's column. We can use the debugger to populate this column as we are viewing the page!
(Warning, at this point, this is specification work that hasn't been tested.)
We can add a form to execute create_ticket,
<page uri="/product">
This is the product!
<connection use-domain name="product">
<ul rx:iterate="others">
<li><lookup path="email" /></li>
</ul>
<table>
<tbody rx:iterate="tickets">
<tr><td><lookup path="request" /></td></tr>
</tbody>
</table>
<form rx:action="send:create_ticket">
<input name="request"> <br />
<button type="submit">Create Ticket</button>
</form>
</connection>
</page>
At this point, we now have Read (via data binding) and Write (via forms) and all manner of applications are possible. Check out the reference for RxHTML
Tutorial
Let's get hands on with Adama!
The key steps are going to be
- Installing the CLI tool which is the primary way to interact with the Adama platform. This tutorial will help you understand the dependencies and validate that the tool is appropriately setup.
- Initializing your developer account will get you on-boarded to production Adama fleet. This tutorial will walk you through account creation.
- Creating a space will get you started with a template space and start making an experience. This tutorial will show the essential operations to create, deploy, and use a space.
- Bringing users into your documents will explain how to invent users on your existing infrastructure or enable social login for your space. This tutorial will explain how to bring people in to use your Adama documents.
- Using the JavaScript client will walk you through how to use your new space with the JavaScript client. This tutorial will explain how to use the JavaScript API to build applications with Adama.
Installing the tool
First thing you need to do is install Java. Either use your distribution's version of Java 17+, or please refer to Oracle's website for how to install Java 17. You can check that you ready when the command:
java -version
shows something like
openjdk version "17.0.7" 2023-04-18
OpenJDK Runtime Environment (build 17.0.7+7-Ubuntu-0ubuntu122.04.2)
OpenJDK 64-Bit Server VM (build 17.0.7+7-Ubuntu-0ubuntu122.04.2, mixed mode, sharing)
That's all you need for Adama to work. Once Java is working, you can download the latest jar using wget download directly from github.
wget https://aws-us-east-2.adama-platform.com/adama.jar
java -jar adama.jar
or (if you lack wget)
curl -fSLO https://aws-us-east-2.adama-platform.com/adama.jar
java -jar adama.jar
to get help on how to use the jar. The next step is to initialize your developer account.
Initializing your developer account
java -jar adama.jar init
Please note the notice about early access!
This will then prompt you with a blurb of text that outlines that providing your email will be implicit acceptance to Adama's terms, conditions, and privacy policy. You should read them!
Once we have your email, we will send you a verification email with a code. Please copy and paste that code into the terminal, and your account will be setup.
Oh, and if you want to revoke other machines, then this is a great time to do it by inputting Y when asked to revoke.
This tool will drop a file (.adama) within your home directory to act as your default config. You can, of course, override this with the --config parameter.
For now, let's move on towards creating a space...
Creating a space
Fundamentally, a space is a namespace/container for Adama documents which share a common document script.
Spaces are global resources, so you may need to be a bit clever with how you name them as conflicts between other developers can happen. This is the rough spot of the tutorial since I can't tell you exactly what to type as you will have to invent a name. However, I can provide an example of creating a space.
java -jar adama.jar space create --space chat001
And, if you don't see a bloody mess of an error message, then your space is created! Huzzah!
You can poke around the space sub command as well. For instance, you can investigate your options by invoking the help on the space sub command via
java -jar adama.jar space help
And one option available to you is to list all your spaces via
java -jar adama.jar space list
For me, using my freshly made account to test this tooling and your experience, produced a list of JSON object containing
{
"space" : "chat001",
"role" : "owner",
"created" : "2022-02-09",
"enabled" : true,
"storage-bytes" : 0
}
This object reveals the name of the space, role of the person doing the listing, date when the space was created, whether or not the space is currently enabled, and finally the total storage used by the space.
The space is now created in an empty state, so let's create some people to leverage it.
Bringing existing users into Adama
The Adama Platform use JWT tokens to authenticate people via their devices, and all Adama developers can use their credentials to talk to the Adama Platform and their documents. It would be an exceptionally limited (yet mephistophelian) requirement for all users to be an Adama developer, so the Adama Platform allows developers to manage public keys. This is done by the developer creating an authority:
java -jar adama.jar authority create
This will return a document like
{
"authority" : "Z2YISR3YMJN29XZ2"
}
The Z2YISR3YMJN29XZ2 is a unique key for developers to use to identify their users. If you accidentally clear your terminal or lose that id, then you can list your authorities via:
java -jar adama.jar authority list
With the name of the authority in hand, we will use the tool to create a keystore
java -jar adama.jar authority create-local \
--authority Z2YISR3YMJN29XZ2 \
--keystore my.keystore.json \
--priv first.private.key.json
This will create two files within your working directory:
- my.keystore.json is a collection of public keys used by Adama to validate a private
- first.private.key.json is a private key used by your software to sign your users' id. This requires safe-keeping!
This keystore and private key were created entirely locally on your machine (for exceptional security), and now you upload only the keystore with:
java -jar adama.jar authority set \
--authority Z2YISR3YMJN29XZ2 \
--keystore my.keystore.json
This will allow the users signed by that private key into Adama. Consuming the private key will require some crypto libraries in some infrastructure that you manage, but we can get started by using the Adama tooling to create an identity today!
java -jar adama.jar authority sign \
--key first.private.key.json \
--agent user001
which will dump out a JWT token with the agent 'user001' as the subject:
eyJhbFUzNiJ9.eyJdWIiTjI5WFoyIn0.TQZbOkE9abE24_8w
This is the string that you use as the identity parameter with the Client API. For now, let's create a second token.
java -jar adama.jar authority sign \
--key first.private.key.json \
--agent user002
We will use the corresponding tokens for user001 and user002 to chat with each other by configuring the space.
Writing and deploying Adama code to a space
With the space created, we can now deploy some code to it! Create a file called chat.adama
The first thing we need to do is some ceremony around who can create documents.
@static {
// only allow users from the authority we just created
create {
return @who.fromAuthority("Z2YISR3YMJN29XZ2");
}
// Here "Inventing" is the act of creating the
// document on demand with connect with no need
// for a create(...) call
invent {
return @who.fromAuthority("Z2YISR3YMJN29XZ2");
}
}
Please note that when you copy-pasta this, the Z2YISR3YMJN29XZ2 will need to be replaced with the authority used to generate your initial users from the prior step.
Now, empty documents can be created with the above policy work. Unfortunately, there is no data and no one can connect. Let's enable connections
// let anyone into the document
@connected {
return @who.fromAuthority("Z2YISR3YMJN29XZ2");
}
Now, people within the developer's authority can connect to the sadly empty document. So, let's add some data.
// `who said `what `when
record Line {
public principal who;
public string what;
public long when;
}
// a table will privately store messages
table<Line> _chat;
// since we want all connected parties to
// see everything, just reactively expose it
public formula chat = iterate _chat;
The document has structure, so let's enable users to populate the chat.
// what users will say stored in a message
message Say {
string what;
}
// the "channel" enables someone to send a message
// bound to some code
channel say(Say what) {
// ingest the line into the chat
_chat <- {who:@who, what:what.what, when: Time.now()};
// since you are paying for the chat, let's cap the
// size to 50 total messages.
(iterate _chat order by when desc offset 50).delete();
}
At this point, the backend for chat is done and we can upload it via:
java -jar adama.jar spaces deploy --space chat001 --file chat.adama
With the space uploaded, you can now build a UI with only HTML.
Using the JavaScript client
The stage is set! Let's use some vanilla.js to craft a new browser experience with Adama powering the back-end. Note, this example is derived from the chat example available from github..
<!DOCTYPE html>
<html>
<head>
<title>Adama Vanilla.JS Chat</title>
<script src="https://aws-us-east-2.adama-platform.com/libadama.js"></script>
</head>
<body>
<div id="status"></div>
<table border="0">
<tr>
<td colspan="2" id="setup">
<fieldset>
<legend>Inputs: Space, Key, and Identities</legend>
<label for="space">Space (valid characters are a-z, 0-9, - and _)</label>
<input type="text" id="space" name="space" value="chat000" size="100"/>
<br />
<label for="key">Key (valid characters are a-z, 0-9, -, ., and _)</label>
<input type="text" id="key" name="key" value="room-as-key" size="100"/>
<br />
<label for="identity-user-1">User 1</label>
<input type="text" id="identity-user-1" name="identity-user-1" size="100"/>
<br />
<label for="identity-user-2">User 2</label>
<input type="text" id="identity-user-2" name="identity-user-2" size="100"/>
<br />
<button id="connect">Connect both users</button>
</fieldset>
</td>
</tr>
<tr>
<td>
<fieldset>
<legend>Chat Log (User 1)</legend>
<div id="chat-output-1"></div>
<label for="speak-user-1">User 1 Says What</label>
<input type="text" id="speak-user-1" size="25"/>
<br />
<button id="send-1">Speak</button>
</fieldset>
</td>
<td>
<fieldset>
<legend>Chat Log (User 2)</legend>
<div id="chat-output-2"></div>
<label for="speak-user-2">User 2 Says What</label>
<input type="text" id="speak-user-2" size="25"/>
<br />
<button id="send-2">Speak</button>
</fieldset>
</td>
</tr>
</table>
</body>
<script>
// INSERT CODE BELOW HERE
</script>
</html>
For your own personal sake, it would be useful to replace chat000 with whatever name you choose for a space. This mess of old-school HTML is a skeleton to demonstrate the basics, so let's connect to Adama.
// connect to Adama
var connection = new Adama.Connection(Adama.Production);
connection.start();
// wait until we are connected
document.getElementById("status").innerHTML = "Connecting to production...";
connection.wait_connected().then(function() {
document.getElementById("status").innerHTML = "Connected!!!";
});
Before we can make the connect button work, we will create a handler for dealing with document deltas. At core, the below code bridges how data from Adama flows into the DOM.
// write chat changes to the DOM
function makeBoundTree(outputId) {
var tree = new AdamaTree();
tree.subscribe({chat: function(chat) {
var lines = [];
lines.push("<table border=\"1\"><thead><tr><th>Who</th><th>Said</th></tr></thead><tbody>");
for (var k = 0; k < chat.length; k++) {
lines.push("<tr><td>" + chat[k].who.agent + "</td><td>" + chat[k].what + "</td></tr>");
}
lines.push("</tbody></table>");
document.getElementById(outputId).innerHTML = lines.join("");
}});
return {
next: function(payload) {
if ('delta' in payload) {
var delta = payload.delta;
if ('data' in delta) {
tree.update(delta.data);
}
}
},
complete: function() {
document.getElementById(outputId).innerHTML = "chat completed";
},
failure: function(reason) {
document.getElementById(outputId).innerHTML = "Failed: " + reason;
}
};
}
// log send errors to console.log
function failureToConsoleLog(prefix) {
return {
success: function() {},
failure: function(reason) {
console.log(prefix + reason);
}
};
}
The above code will simply manifest changes of the following chat formula from chat.adama into the DOM.
public formula chat = iterate _chat;
It does this by creating a tree which will absorb data differentials and rebuild the chat lines. Now we make the connect button work!
document.getElementById("connect").onclick = function() {
// fetch the input values
var space = document.getElementById('space').value;
var key = document.getElementById('key').value;
var identity1 = document.getElementById('identity-user-1').value;
var identity2 = document.getElementById('identity-user-2').value;
// create the connections to the document and bind them to the DOM
var connection1 = connection.ConnectionCreate(
identity1, space, key, {}, makeBoundTree('chat-output-1'));
var connection2 = connection.ConnectionCreate(
identity2, space, key, {}, makeBoundTree('chat-output-2'));
// hook up the buttons to send messages to the say channel per user
document.getElementById("send-1").onclick = function() {
connection1.send("say",
{what:document.getElementById("speak-user-1").value}, failureToConsoleLog("user-1 send:"));
}
document.getElementById("send-2").onclick = function() {
connection2.send("say",
{what:document.getElementById("speak-user-2").value}, failureToConsoleLog("user-2 send:"));
}
// remove the setup html
document.getElementById("setup").innerHTML = "";
}
This will connect each user's identity to appropriate window and make the buttons work. Here, we can observe that reactivity is no longer a client concern. Instead, we have very simple JavaScript with data bound to a tree.
At this point, the tutorial is over which is sad. However, there are examples to inspect. Given the early release nature of this, questions and feedback are welcomed!
The best place for help is to join the discord channel!
Language Tour
Since the central way of interacting with documents held within a space is via the Adama language, let's take a tour.
This document is a lightweight tour of the core features and ideas that make Adama a somewhat novel data-centric programming language. It is important to remember that Adama is not a general purpose language. It’s for board games (and maybe more... much more).
Defining State Layout
We start by defining global fields with default values. Laying out and structuring data is arguably the most important activity in building software, so it must be simple and convenient for developers to define their data. Here, we will define a document with just a name and score field:
public string name = "You";
private int score = 100;
This fairly minimal Adama code defines a document. The backend data for this script is a document represented via the following JSON:
{"name":"You", "score":100}
However, a human viewer (such as yourself or myself) of the document will only see:
{"name":"You"}
This is because the score field is defined with the private modifier. By modifying a field with private, only the code within the document can operate on the score field. This is useful, for example, to define secrets in a game. A key function in board games is the need for secrets (i.e. the contents of your hand) or an unrevealed state of objects such as the ordering of cards within a deck.
The following diagram visualizes the Adama environment and architecture:
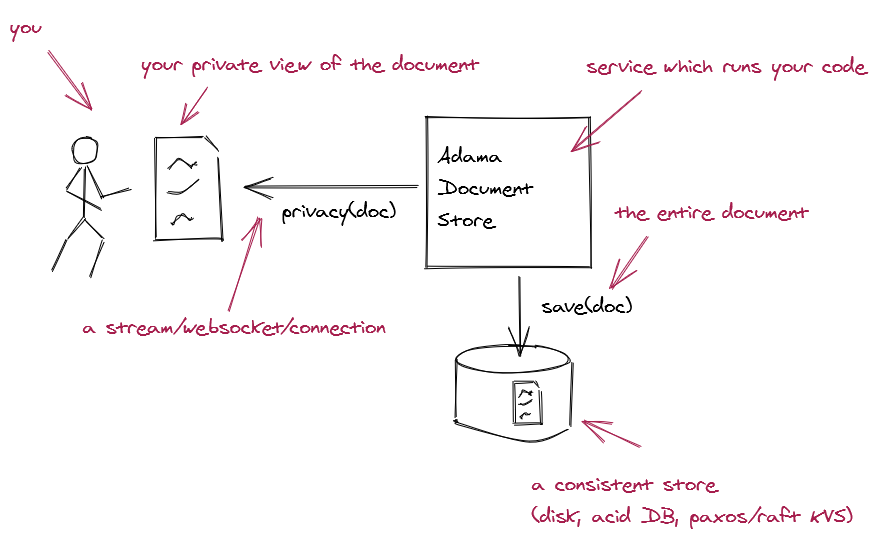
Here is a brief overview of the Adama working environment:
- People connect (via a client) to the Adama Platform with a persistent connection.
- Adama will then send to you a private and personalized version of the document.
- People send messages to the document, and Adama will run code on the message to validate and change the document.
- Adama will send updates while respecting the privacy based on directives (e.g., the private modifier sets the score variable as private in the above example).
Adama is not only a data-centric programming language, but a privacy-focused language such that secrets between players (i.e. individual hands) and the universe (i.e. decks) are not disclosed. This environment is essential for games requiring secrets so that other gamers do not gain an unfair advantage from "hacking" environment variables.
Organizing the Chaos Induced by Globals
Having a giant pool of global fields will lead to chaos and copypasta, so we introduce records as a way combining fields around an entity.
record Card {
public int suit;
public int rank;
}
public Card a;
public Card b;
A record is a structure that defines one or more named typed fields under a single type name. In the above example, the structure Card is the combination of suit and rank integer fields. These structures can then be used to create instances within the document of that type. The above code backend would have the following JSON:
{
"a":{"suit":0, "rank":0},
"b":{"suit":0, "rank":0}
}
The above example is great for cleaning up patterns within the global document, but this is insufficient for non-trivial games. The next step is to introduce a collection of records. Adama provides the notion of a table, and the above record can be used to create a table named deck.
table<Card> deck;
But this begs the question: how do records flow into the deck? Adama uses events that can be associated with developer code which is evaluated when events trigger. This code can then manipulate the document.
One example of an event is the creation of the document. The event is created via a constructor (using the @construct identifier). This constructor can be used with an "ingestion" operator (<-) and some C style for loops. The following Adama code builds a table of Card records based on the JSON document structure:
@construct {
for (int s = 0; s < 4; s++) {
for (int r = 0; r < 13; r++) {
deck <- {suit:s, rank:r};
}
}
}
The above code will construct the state of the document representing a typical deck of cards containing 52 cards, 4 suits and 13 cards per suit. Tables are always private in Adama, so viewers of the document will not see table structures. However, the data contained within the table will be viewable. Queries against the table expose selected data to people such as players. As an example, the following code will let everyone know the size of the deck:
public formula deck_size = deck.size();
The above formula variable represents Adama's reactive programming language. As the deck undergoes changes during gameplay, the formula variables depending on that deck will be recomputed and updates will be sent to viewers such as players in the game. For efficiency, this is done once message processing stops.
Because Adama continually updates the state of document, the connection from your device to the Adama Document Store uses a socket. The socket provides a way for the server to know the state of the client, and then minimize the compute overhead on the server. This enables small data changes to manifest in small compute changes that translate to less network usage. Less network usage translates to less client device compute overhead, and this manifests into less battery consumption for the end-user. Board games can last for hours when they leverage Adama's reduction in battery power consumption.
A table is an exceptionally powerful tool, and Adama uses language integrated query (LINQ) to query data. Using the Card structure, the following example adds a client type to the Card record to indicate possession of the card:
record Card {
public int suit;
public int rank;
public principal owner;
}
The above Card record allows us to share how many cards are unassigned in the deck via a formula. The code to do this is below:
public formula deck_remaining = (iterate deck where owner == @no_one).size()
Here @no_one is a special default value for the client type which indicates that cards are unassigned. We can leverage a bubble to share a viewer's hand (if they are a player and not a random observer).
bubble hand = iterate deck where owner == @who;
The bubble is special type of formula which allows data to be computed based on who is viewing the document. This allows people to have a personalized view of the document such as being able to see their hand. As the deck and rows within the deck experience change, the formulas update automatically based on precise static analysis. These changes propagate to all viewers in a predictable way.
Messages from Devices to the Document
Changing the document is done via people sending messages to the document.
Adama acts as a message receiver of messages sent by the client. We can model a message similar to a record. For instance, we can design a message that says "I wish to draw $count cards" demonstrated below:
message Draw {
int count;
}
This message encodes the product intent, and we can associate code to that message via a channel.
channel draw_cards(Draw d) {
(iterate deck where owner == @no_one shuffle limit d.count).owner = @who;
}
This channel will allow messages of type Draw to flow from the client to the code outlined above. In this case, the code uses a LINQ query to find at most d.count available random cards to associate to the Draw message sender.
Messages alone create a nice theoretical framework, but they may not be practical for games. This messaging works great for things like chat, but it offloads a great deal of burden to both the message handler and the client. For instance, in a game, when can someone draw cards? Can they draw cards at any time? Or during a specific game phase?
Let the Server Take Control!
To control message flow, Adama uses an incomplete channel identifier. An incomplete channel is like a promise that indicates clients may provide a message of a specific type, but only when the document asks for it.
Adama uses a third party to broker the communication between players. That is, it determines who is asking players for messages. This is where the document's finite state machine comes into play. The document can be in exactly one state at any time, and states are represented via hashtags. For instance, #mylabel is a state machine label used to denote a potential state of the document.
We can associate code to a state machine label directly and set the document to that state via the transition keyword.
@construct { // this could also be a message sent after all players are ready
transition #round;
}
#round {
// code to run
}
In this example, the associated code attached to #round will run after the constructor has run and the document has been persisted. An important property of the state machine is that it defines an atomic boundary for both persisting to a durable store and when to share changes to the document.
Only the transition keyword can set the document's next state label to run. For instance, the following is an infinite state machine:
public int turn;
#round {
turn++;
transition #round;
}
The reason we took this detour is to have a third party be able to use the incomplete channel. For instance, the document somehow learns of two players within a game; these players' associated clients are stored within the document via:
private principal player1;
private principal player2;
Now, we can define an incomplete channel for the document to ask players for cards.
channel<Draw> how_many_cards;
This incomplete channel will accept messages only from code via a fetch method on the channel. We can leverage the state machine code to ask players for the number of cards they wish to draw using the following Adama code:
#round {
future<Draw> f1 = how_many_cards.fetch(player1);
Draw d1 = f1.await();
future<Draw> f2 = how_many_cards.fetch(player2);
Draw d2 = f2.await();
}
This is a productivity win with respect to board games because it inverts the control model away from the client towards the server as synchronous code. This is the key to enforce rules in a coherent way and keep control of the implicit state machine formed as rules compound in complexity.
Time to Reflect
This document took you on a tour of a few of the core ideas found within the Adama programming, and while this is not a comprehensive review it does address some of the novel aspects. The key is that you focus on the data at hand for a single game, and then outline all the ways the game state may change. The rules of the game can be written in a synchronous manner which mirrors how they are executed live with people.
How-to Guides
How to create a Tic Tac Toe Game using Adama Platform
written by David Asaolu
Building an efficient board game can be tedious if you're not using the programming language and resources best suited for creating such gaming applications. In this article, I'll guide you through building a Tic Tac Toe game with Adama, a programming language that allows you to create board games easily.
Adama is a reactive programming language that utilizes an event-driven architecture that enables us to build scalable and efficient applications. Adama started as a tool that provides a better way of representing states in an application, then gradually grew into a fully-fledged programming language. Adama uses a serverless infrastructure whereby a single file can contain an infinite space of documents acting like tiny computers with storage and networking.
Before we go further, let's learn why you should choose Adama when building your applications.
Why choose Adama?
In this section, you'll learn about some of the features provided by Adama that enable us to build efficient real-time applications.
Fast compilation and deployment
Programming in Adama is fast, and compilation and deployment happen immediately after initiating the actions. Adama is a language designed to achieve more functionalities with less effort, cost, and time.
In Adama, the validator runs in a single digit millisecond for a moderately large code base.
Backward compatibility
Adama is an innovative language that can run early versions of the program in newer environments without errors. Programs written in the older versions of Adama can run efficiently without issues.
Excellent tool for creating efficient applications
Being a reactive programming language, Adama handles events asynchronously; this enables your program to process real-time updates efficiently and accommodate many users at a time. Adama started as a tool for representing states conveniently before becoming a programming language. Adama aims to make application development easy and even provide more capabilities that will enable you to build affordable and reliable applications.
How to start building with Adama
Here, I will guide you through setting up Adama and how you can start creating efficient applications with Adama. Before building with Adama, you need to install Java on your computer. Head over to Oracle's website and install Java 17.
Once you have completed the installation process, run the code below in your terminal to confirm if the installation was successful.
java -version
It should return something similar to the code below.
openjdk version "11.0.13" 2021-10-19
OpenJDK Runtime Environment (build 11.0.13+8-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.13+8-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
Next, download the latest Adama jar file from GitHub by running this code.
wget https://github.com/mathgladiator/adama-lang/releases/download/nightly/adama.jar
Create an Adama developer account by running the code below. Read through the information and supply your email address. Enter the verification code sent to your email in your terminal.
java -jar adama.jar init
Run the code below to create a space for your Adama document. Adama space is similar to buckets in AWS. It is the container for your Adama documents.
java -jar adama.jar space create --space <your_space_name>
Congratulations! You've just created a space for your Adama document. You can now start creating the backend for the Tic Tac Toe game.
Building the backend for your Tic Tac Toe game
In this section, we'll leverage the tools provided by Adama to build a Tic Tac Toe game. Tic Tac Toe is a game that consists of two users, one is X, and the other is O. The player that succeeds in placing three of its symbols horizontally, vertically, or diagonally is the winner.
Before writing Adama's code, we need to state the document's policy. The code snippet below allows anyone to create a document.
@static {
// This makes it possible for everyone to create a document.
create { return true; }
invent { return true; }
// As this will spawn on demand, let's clean up when the viewer goes away
delete_on_close = true;
}
Below the document's policy, declare the states of each square box - empty or contains the player X or O. From the code snippet below, we created an enum variable type that represents all the three possible states of the application.
// What is the state of a square
enum SquareState { Open, X, O }
Next, let's declare a public variable representing each player. In Adama, the client keyword is assigned to users and contains information related to the user; @no_one is its default value.
// The two players
public principal playerX;
public principal playerO;
// The current player
public principal current;
Create another set of variables containing the draws and win in the game.
// how many wins
public int wins_X;
public int wins_O;
// how many stalemates or player draws
public int stalemates;
Assign roles to each player. In Adama, there is a data type called bubble whose values change depending on the connected user viewing the document; this allows users to have a personalized view of the document.
// personalized data for the connected player:
// show the player their role, a signal if it is their turn, and their wins
bubble your_role = playerX == @who ? "X" : (playerO == @who ? "O" : "Observer");
bubble your_turn = current == @who;
bubble your_wins = playerX == @who ? wins_X : (playerO == @who ? wins_O : 0);
From the code snippet above, your_role assigns the current player viewing the document, "X" and the other "O". The your_turn variable is equal to whether the user viewing the document is the current player. The your_wins variable contains the number of times the current user wins the game.
Next, let's create a record containing every data in each square block. Record is a variable that groups variables related to an entity under a single variable.
// a record of the data in the square
record Square {
public int id;
public int x;
public int y;
public SquareState state;
}
Since we've been able to represent each box in the tic-tac-toe grid as records, create a table containing every box on the tic-tac-toe table.
// the collection of all square boxes
table<Square> _squares;
From the code snippet above, the table is the keyword for creating a table. The angle brackets accept the record type as a parameter and convert it to a table. _squares represent the name of the table.
Convert the table to a list and separate the board by using its rows.
// converts the table to a list using the iterate keyword
public formula board = iterate _squares;
// breaks the square into its rows
public formula row1 = iterate _squares where y == 0;
public formula row2 = iterate _squares where y == 1;
public formula row3 = iterate _squares where y == 2;
From the code snippet above, the formula identifier enables us to write an expression on the right side of the equal-to sign. Each row is differentiated using the variable y, which represents the y-axis of the table.
Add the code below to the document. The code snippet loops through the x and y variable from the Square record and saves the result into the _squares table.
@construct {
for (int y = 0; y < 3; y++) {
for (int x = 0; x < 3; x++) {
_squares <- { x:x, y:y, state: SquareState::Open };
}
}
wins_X = 0;
wins_O = 0;
stalemates = 0;
}
Note that the @construct event will be fired once after creating the document. Initially, the number of wins for the X, O players, and draws is 0.
Update the document by adding the code below. The code snippet assigns the current player an X or O. After giving both values to the players, the game starts. This event returns true indicating that the player is allowed in the game to either play or observe.
@connected {
if (playerX == @no_one) { //if no one has been assigned playerX
playerX = @who; //assign playerX to the current user
if (playerO != @no_one) { //if playerO has been assigned to a user
transition #initiate; //start the game
}
} else if (playerO == @no_one) { //if no one has been assigned playerO
playerO = @who; //assign playerO to the current user viewing the document
if (playerX != @no_one) { //if playerX has been assigned to a user
transition #initiate; //start the game
}
}
return true; //The user has been successfully connected
}
// the game is afoot
#initiate {
current = playerX; //playerX is the first person to play
transition #turn;
}
Create the turn state. The turn state checks for empty spaces in the square table; if there are none, the game records a stalemate, and the stalemates variable is increased by one before it ends.
#turn {
// find the open spaces
list<Square> open = iterate _squares where state == SquareState::Open;
if (open.size() == 0) {
stalemates++;
transition #end;
return;
}
}
Create a channel to enable players to move between each square box via its id.
// open a channel for players to select a move
message Play { int id; }
channel<Play> play;
Next, add a procedure that determines if there is a win. The code snippet below accepts the values in each square box and returns true if the vertical, horizontal, and diagonal spaces contain the same values of either X or O.
// test if the placed square produced a winning combination
procedure test_placed_for_victory(SquareState placed) -> bool {
for (int k = 0; k < 3; k++) {
// vertical lines
if ( (iterate _squares where x == k && state == placed).size() == 3) {
return true;
}
// horizontal lines
if ( (iterate _squares where y == k && state == placed).size() == 3) {
return true;
}
}
// diagonals
if ( (iterate _squares where y == x && state == placed).size() == 3 ||
(iterate _squares where y == 2 - x && state == placed).size() == 3 ) {
return true;
}
return false;
}
Update the turn state by copying the code below. The play channel created earlier allows the player to select an open space until one of the players wins or when there is no empty space.
#turn {
// find the open spaces
list<Square> open = iterate _squares where state == SquareState::Open;
if (open.size() == 0) {
stalemates++;
transition #end;
return;
}
// ask the current play to choose an open space
if (play.decide(current, @convert<Play>(open)).await() as pick) {
// assign the open space to the player
let placed = playerX == current ? SquareState::X : SquareState::O;;
(iterate _squares where id == pick.id).state = placed;
if (test_placed_for_victory(placed)) {
if (playerX == current) {
wins_X++;
} else {
wins_O++;
}
transition #end;
} else {
transition #turn;
}
current = playerX == current ? playerO : playerX;
}
}
Finally, create the end state and make all the square boxes empty and ready for another round of play.
#end {
(iterate _squares).state = SquareState::Open;
transition #turn;
}
Conclusion
In this article, you've learnt about the different features Adama provides, how you can start building with Adama, and how to build the backend of a Tic Tac Toe game using Adama.
Adama is a programming language that leverages the reactive property to enable us to build efficient and scalable real-time applications at a minimal cost. Adama provides a fun way of building applications. If you are looking forward to building an efficient real-time gaming application, Adama is an excellent choice.
Thank you for reading!
Examples - Get Playful
| example | description |
|---|---|
| tic-tac-toe | the classic game of Tic-Tac-Toe |
| reddit clone | A clone of reddit using AI for UX |
| chat | a simple chat |
| hearts | the classic card game of hearts |
| maxseq | maximum sequencer for coordination |
| pubsub | a durable publisher subscriber system |
| sms | a Twilio web hook responder |
| silly | a silly tour of features |
Tic Tac Toe
Back-end
@static {
// As this is going to be a live home-page sample, let anyone create
create { return true; }
invent { return true; }
// As this will spawn on demand, let's clean up when the viewer goes away
delete_on_close = true;
}
// What is the state of a square
enum SquareState { Open, X, O }
// who are the two players
public principal playerX;
public principal playerO;
// who is the current player
public principal current;
// how many wins per player
public int wins_X;
public int wins_O;
// how many stalemates
public int stalemates;
// personalized data for the connected player:
// show the player their role, a signal if it is their turn, and their wins
bubble your_role = playerX == @who ? "X" : (playerO == @who ? "O" : "Observer");
bubble your_turn = current == @who;
bubble your_wins = playerX == @who ? wins_X : (playerO == @who ? wins_O : 0);
// a record of the data in the square
record Square {
public int id;
public int x;
public int y;
public SquareState state;
}
// the collection of all squares
table<Square> _squares;
// show the board to all players
public formula board = iterate _squares;
// for visualization, we break the squares into rows
public formula row1 = iterate _squares where y == 0;
public formula row2 = iterate _squares where y == 1;
public formula row3 = iterate _squares where y == 2;
// when the document is created, initialize the squares and zero out the totals
@construct {
for (int y = 0; y < 3; y++) {
for (int x = 0; x < 3; x++) {
_squares <- { x:x, y:y, state: SquareState::Open };
}
}
wins_X = 0;
wins_O = 0;
stalemates = 0;
}
// when a player connects, assign them to either the X or O role. If there are more than two players, then they can observe.
@connected {
if (playerX == @no_one) {
playerX = @who;
if (playerO != @no_one) {
transition #initiate;
}
} else if (playerO == @no_one) {
playerO = @who;
if (playerX != @no_one) {
transition #initiate;
}
}
return true;
}
// open a channel for players to select a move
message Play { int id; }
channel<Play> play;
// the game is afoot
#initiate {
current = playerX;
transition #turn;
}
// test if the placed square produced a winning combination
procedure test_placed_for_victory(SquareState placed) -> bool {
for (int k = 0; k < 3; k++) {
// vertical lines
if ( (iterate _squares where x == k && state == placed).size() == 3) {
return true;
}
// horizontal lines
if ( (iterate _squares where y == k && state == placed).size() == 3) {
return true;
}
}
// diagonals
if ( (iterate _squares where y == x && state == placed).size() == 3 || (iterate _squares where y == 2 - x && state == placed).size() == 3 ) {
return true;
}
return false;
}
#turn {
// find the open spaces
list<Square> open = iterate _squares where state == SquareState::Open;
if (open.size() == 0) {
stalemates++;
transition #end;
return;
}
// ask the current play to choose an open space
if (play.decide(current, @convert<Play>(open)).await() as pick) {
// assign the open space to the player
let placed = playerX == current ? SquareState::X : SquareState::O;;
(iterate _squares where id == pick.id).state = placed;
if (test_placed_for_victory(placed)) {
if (playerX == current) {
wins_X++;
} else {
wins_O++;
}
transition #end;
} else {
transition #turn;
}
current = playerX == current ? playerO : playerX;
}
}
#end {
(iterate _squares).state = SquareState::Open;
transition #turn;
}
Front-end using RxHTML
<forest>
<template name="cell">
<div rx:switch="state">
<div rx:case="0">
<decide channel="play">
<button>Play here</button>
</decide>
</div>
<div rx:case="1">X</div>
<div rx:case="2">O</div>
</div>
</template>
<template name="game">
<table>
<tr>
<td>Role</td><td><lookup path="your_role" /></td>
<td>Wins</td><td><lookup path="your_wins" /></td>
</tr>
</table>
<div>
<test path="your_turn">
<div>
It is your turn!
</div>
</test>
</div>
<div class="[your_turn]text-indigo-600[#your_turn]text-gray-900[/your_turn]">
CHANGE
</div>
<table border="1">
<tr rx:iterate="row1">
<td>
<use name="cell" />
</td>
</tr>
<tr rx:iterate="row2">
<td>
<use name="cell" />
</td>
</tr>
<tr rx:iterate="row3">
<td>
<use name="cell" />
</td>
</tr>
</table>
</template>
<page uri="/#game">
<connection name="player1" identity="eyJhbGciOiJFUzI1NiJ9.eyJzdWIiOiJ1c2VyMDAxIiwiaXNzIjoiWUlTUjNZTUpSSzNHMlo2MkFWWVdCWUNITjI5WFoyIn0.oKZOXHJUFPyxMT7j6X4WQRLy4VVeGGOvZgqMS2hsU6W1lALW-teOdoHAj2t5K3oHDBj6zH_3NFt6fR6fthfyzA" space="tic-tac-toe" key="demo" random-key-suffix>
<use name="game" />
</connection>
<connection name="player2" identity="eyJhbGciOiJFUzI1NiJ9.eyJzdWIiOiJ1c2VyMDAyIiwiaXNzIjoiWUlTUjNZTUpSSzNHMlo2MkFWWVdCWUNITjI5WFoyIn0.uS2LyhmDh1gg35Zpa1yd-JKxxu4EjzggQlL9tc2zFxZYPD0SZykgtjvL0PeKH0X67ot84Xb6Hk9mmMpRqDyRMA" space="tic-tac-toe" key="demo" random-key-suffix>
<use name="game" />
</connection>
</page>
</forest>
Durable PubSub
@static {
// anyone can create
create { return true; }
}
@connected {
// let everyone connect; sure, what can go wrong
return true;
}
// we build a table of publishes with who published it and when they did so
record Publish {
public principal who;
public long when;
public string payload;
}
table<Publish> _publishes;
// since tables are private, we expose all publishes to all connected people
public formula publishes = iterate _publishes order by when asc;
// we wrap a payload inside a message
message PublishMessage {
string payload;
}
// and then open a channel to accept the publish from any connected client
channel publish(PublishMessage message) {
_publishes <- {who: @who, when: Time.now(), payload: message.payload };
// At this point, we encounter a key problem with maintaining a
// log of publishes. Namely, the log is potentially infinite, so
// we have to leverage some product intelligence to reduce it to
// a reasonably finite set which is important for the product.
// First, we age out publishes too old (sad face)
(iterate _publishes
where when < Time.now() - 60000).delete();
// Second, we hard cap the publishes biasing younger ones
(iterate _publishes
order by when desc
offset 100).delete();
}
Maximum Number
@static {
create { return true; }
}
@connected {
return true;
}
public int max_db_seq = 0;
message NotifyWrite {
int db_seq;
}
channel notify(NotifyWrite message) {
if (message.db_seq > max_db_seq) {
max_db_seq = message.db_seq;
}
}
Hearts
Many of the bugs have been fixed, this is from an old version.
@static {
// anyone can create
create { return true; }
invent { return true; }
}
// we define the suit of a card
enum Suit {
Clubs:1,
Hearts:2,
Spades:3,
Diamonds:4,
}
// the rank of a card
enum Rank {
Two:2,
Three:3,
Four:4,
Five:5,
Six:6,
Seven:7,
Eight:8,
Nine:9,
Ten:10,
Jack:11,
Queen:12,
King:13,
Ace:14,
}
// where can a card be
enum Place {
Deck:1,
Hand:2,
InPlay:3,
Taken:4
}
// model the card and its location and ownership
record Card {
public int id;
public Suit suit;
public Rank rank;
private principal owner;
private int ordering;
private Place place;
private auto points = suit == Suit::Hearts ? 1 : (suit == Suit::Spades && rank==Rank::Queen ? 13 : 0);
// define a policy as to who can see the card
policy p {
// if it is in hand on in the pot, then only the owner of the card can see it
// the rules of hearts have cards face down
if (place == Place::Hand || place == Place::Taken) {
return @who == owner;
}
// if it is in the pot or in play, then anyone can see it
if (place==Place::InPlay) {
return true;
}
// otherwise, it is in the deck and thus not visible
return false;
}
method reset() {
ordering = Random.genInt();
owner = @no_one;
place = Place::Hand;
}
require p;
}
// the entire deck of cards
table<Card> deck;
// show the player hand (and let the privacy policy filter out by person)
bubble hand = iterate deck where place == Place::Hand where owner == @who order by id asc;
// show all cards in the pot (this would be a different way of defining hand)
bubble my_take = iterate deck where place == Place::Taken && owner == @who;
// no real constructor
message Empty {}
principal owner;
record Player {
public int id;
public principal link;
public int points;
viewer_is<link> int play_order;
}
table<Player> players;
@connected {
if ((iterate players where link==@who).size() > 0) {
return true;
}
if (players.size() < 4) {
players <- {
link:@who,
play_order: players.size(),
points:0
};
if (players.size() == 4) {
transition #setup;
}
return true;
}
return false;
}
// everyone in the game
public auto people = iterate players order by play_order;
// the players by their ordering
public auto players_ordered = iterate players order by play_order;
// are we actually playing the game?
public bool playing = false;
// how setup the game state
#setup {
// build the deck
foreach (s in Suit::*) {
foreach (r in Rank::*) {
deck <- {rank:r, suit:s, place:Place::Deck};
}
}
// normalize the players from 0 to 3
int normativeOrder = 0;
(iterate players order by play_order asc).play_order = normativeOrder++;
// shuffle and distribute the cards
transition #shuffle_and_distribute;
}
enum PassingMode { Across:0, ToLeft:1, ToRight:2, None:3 }
public PassingMode passing_mode;
#shuffle_and_distribute {
// it may be useful to allow methods on a record, fuck
(iterate deck).reset();
// distribute cards to players
Player[] op = (iterate players order by play_order).toArray();
for (int k = 0; k < 4; k++) {
if (op[k] as player) {
(iterate deck where owner == @no_one order by ordering limit 13).owner = player.link;
}
}
transition #pass;
}
message CardDecision {
int id;
}
channel<CardDecision[]> pass_channel;
// this is wanky, need arrays at a top level that are finite to help...
principal player1;
principal player2;
principal player3;
principal player4;
principal current;
#pass {
if (passing_mode == PassingMode::None) {
transition #start_play;
return;
}
// this is wanky as fuck, and I don't like it. We have this fundamental problem of what if there are not enough players, then how does this fail...
// we should consider a @fatal keyword to signal that a game is just fucked
Player[] op = (iterate players order by play_order).toArray();
if (op[0] as player) {
player1 = player.link;
}
if (op[1] as player) {
player2 = player.link;
}
if (op[2] as player) {
player3 = player.link;
}
if (op[3] as player) {
player4 = player.link;
}
// what does an await on no_one mean, it means the whole thing is fucked
// we really need a future array since this has some awkward stuff
future<maybe<CardDecision[]>> pass1 = pass_channel.choose(player1, @convert<CardDecision>(iterate deck where owner==player1), 3);
future<maybe<CardDecision[]>> pass2 = pass_channel.choose(player2, @convert<CardDecision>(iterate deck where owner==player2), 3);
future<maybe<CardDecision[]>> pass3 = pass_channel.choose(player3, @convert<CardDecision>(iterate deck where owner==player3), 3);
future<maybe<CardDecision[]>> pass4 = pass_channel.choose(player4, @convert<CardDecision>(iterate deck where owner==player4), 3);
// the reason we do the futures above and then await them below like this is so all players can pass at the same time.
// the problem at hand is that the await will consume, so non-awaited futures will cause the client to sit dumbly... this can be fixed easily I think
// by having the make_future<> check the stream and pre-drain the queue and allow the await to short-circuit with the provide option
if (pass1.await() as decision1) {
if (pass2.await() as decision2) {
if (pass3.await() as decision3) {
if (pass4.await() as decision4) {
if (passing_mode == PassingMode::ToRight) {
foreach (dec in decision1) {
(iterate deck where id == dec.id).owner = player2;
}
foreach (dec in decision2) {
(iterate deck where id == dec.id).owner = player3;
}
foreach (dec in decision3) {
(iterate deck where id == dec.id).owner = player4;
}
foreach (dec in decision4) {
(iterate deck where id == dec.id).owner = player1;
}
} else if (passing_mode == PassingMode::ToLeft) {
foreach (dec in decision1) {
(iterate deck where id == dec.id).owner = player4;
}
foreach (dec in decision2) {
(iterate deck where id == dec.id).owner = player1;
}
foreach (dec in decision3) {
(iterate deck where id == dec.id).owner = player2;
}
foreach (dec in decision4) {
(iterate deck where id == dec.id).owner = player3;
}
} else if (passing_mode == PassingMode::Across) {
foreach (dec in decision1) {
(iterate deck where id == dec.id).owner = player3;
}
foreach (dec in decision2) {
(iterate deck where id == dec.id).owner = player4;
}
foreach (dec in decision3) {
(iterate deck where id == dec.id).owner = player1;
}
foreach (dec in decision4) {
(iterate deck where id == dec.id).owner = player2;
}
}
}}}}
transition #start_play;
}
public int played = 0;
public Suit suit_in_play;
public bool points_played = false;
public auto in_play = iterate deck where place == Place::InPlay order by rank desc;
#start_play {
// no cards hae been played
played = 0;
points_played = false;
// assign a player to current
current = player1;
if ( (iterate deck where rank == Rank::Two && suit == Suit::Clubs)[0] as two_clubs) {
current = two_clubs.owner;
} // otherwise, @fatal
transition #play;
}
channel<CardDecision> single_play;
// how to attribute this to a person
public principal last_winner;
#play {
list<Card> choices = iterate deck where owner == current && place == Place::Hand && rank == Rank::Two && suit == Suit::Clubs;
if (choices.size() == 0) {
choices = iterate deck where owner==current && place == Place::Hand && (
played == 0 && (points_played || points == 0) ||
played > 0 && suit_in_play == suit
);
}
if (choices.size() == 0) { // anything in hand
choices = iterate deck where owner==current && place == Place::Hand;
}
if (choices.size() == 0) {
transition #score;
return;
}
future<maybe<CardDecision>> playX = single_play.decide(current, @convert<CardDecision>(choices));
if (playX.await() as dec) {
if ((iterate deck where id == dec.id)[0] as cardPlayed) {
cardPlayed.place = Place::InPlay;
if (cardPlayed.points > 0) {
points_played = true;
}
if (played == 0) {
suit_in_play = cardPlayed.suit;
}
}
}
// if the number of cards played is less than 4, then next player; otherwise, decide winner of pot and award points
// TODO: need finite arrays and cyclic integers
if (current == player1) {
current = player2;
} else if (current == player2) {
current = player3;
} else if (current == player3) {
current = player4;
} else if (current == player4) {
current = player1;
}
if (played == 3) {
if ( (iterate deck where place == Place::InPlay && suit == suit_in_play order by rank desc limit 1)[0] as winner) {
(iterate deck where place == Place::InPlay).owner = winner.owner;
last_winner = winner.owner;
}
(iterate deck where place == Place::InPlay).place = Place::Taken;
played = 0;
current = last_winner;
if( (iterate deck where owner == current && place == Place::Hand).size() == 0) {
transition #score;
return;
}
} else {
played++;
}
transition #play;
}
public int points_awarded = 0;
#score {
// award points
foreach(p in iterate players) {
int local_points = 0;
foreach(c in iterate deck where owner == p.link && place == Place::Taken) {
local_points += c.points;
}
if (local_points == 26) {
foreach(p2 in iterate players where link != p.link) {
p2.points += 26;
points_awarded += 26;
}
} else {
p.points += local_points;
points_awarded += local_points;
}
}
passing_mode = passing_mode.next();
transition #shuffle_and_distribute;
}
Chat
@static {
// anyone can create
create { return true; }
invent { return true; }
maximum_history = 250;
}
// let anyone into the document
@connected {
return true;
}
// the lines of chat
record Line {
public principal who;
public string what;
public long when;
}
// the chat table
table<Line> _chat;
// how someone communicates to the document
message Say {
string what;
}
// the "channel" which enables someone to say something
channel say(Say what) {
// ingest the line into the chat
_chat <- {who:@who, what:what.what, when: Time.now()};
(iterate _chat order by when desc offset 50).delete();
}
// emit the data out
public formula chat = iterate _chat;
SMS Bot
Back-end (Draft)
This is as draft example
@static {
create {
return true;
}
}
public principal owner;
@connected {
return true;
}
@construct {
owner = @who;
}
record Entry {
public int id;
public dynamic parameters;
public map<string, string> headers;
public string from;
public string body;
}
table<Entry> _entries;
public formula entries = iterate _entries order by id desc;
message TwilioSMS {
string From;
string Body;
}
@web put /webhook (TwilioSMS sm) {
_entries <- {
from:sm.From,
body:sm.Body,
parameters:@parameters,
headers:@headers
};
return {
xml: "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<Response><Message>Thank you for the data. NOM. NOM.</Message></Response>"
};
}
A Silly Example to Show Off
// 1/6: Layout state with a schema
public principal owner;
public string name;
public string description;
public int viewers;
record AddOn {
public string name;
public string description;
}
// tables within documents!
table<AddOn> _addons;
// 2/6: create documents with constructors
@static {
// policy: who can create? anyone!
create { return true; }
}
message Arg {
string name;
string description;
}
@construct(Arg arg) {
owner = @who;
name = arg.name;
description = arg.description;
}
// 3/6: people connect with WebSocket
@connected {
viewers++;
return true;
}
@disconnected {
viewers--;
}
// 4/6: people manipulate document via messages
message AddAddOn {
string name;
string description;
}
channel create_new_add_on(AddAddOn arg) {
// tables can "ingest" data easily
_addons <- arg;
}
// 5/6: deletes are handled within document (for safety!)
message Nothing {
}
channel delete(Nothing arg) {
if (owner == @who) {
Document.destroy();
}
}
// 6/6: reactive formulas (just like a spreadsheet)
public formula addons = iterate _addons order by name asc;
public formula addons_size = addons.size();
public formula name_uppercase = name.upper();
Language Guide
Welcome to the Adama Language Guide.
Adama is a programming language designed to facilitate building online applications for both the web and mobile. It requires defining an Adama specification file; this Adama specification file defines both the structure and logic required to power interactive experiences.
The main challenge when building an Adama application is structuring the state within your document. You need to define the variables and tables that hold the state of your application and how those variables change over time. Adama also allows you to open channels for people to send messages to change the state of your application. For instance, users can submit forms, click buttons, or interact with other elements on your application to trigger events that change the state of the application.
Adama also enables the use of state machines to breathe life into your document. State machines help you define the different states that your application can be in and how it transitions from one state to another. This allows you to build complex applications with dynamic behavior, such as multi-step forms, wizards, and interactive workflows. By using Adama's state machine, you can define the rules that govern how your application behaves and responds to user actions, making your application more interactive and engaging for your users.
Unique to Adama
Adama is a cutting-edge programming language that curates syntax of several well-known languages, including C++, Java, and JavaScript, to provide a unique and powerful development experience. This tour of Adama's features is structured in order of their uniqueness, highlighting the most innovative aspects of the language first. By exploring these features, you will gain a deeper understanding of Adama's capabilities and how it differs from other languages.
- Document layout; learn the fundamental techniques for structuring your state within your application. This involves defining variables that hold the current state of your application.
- Static policies and document events; in order to understand how users connect to documents in Adama, it's essential to learn about access control and the various document events that trigger it. Through these events, you can control who has access to your application and what they can do with it. By mastering Adama's access control features, you can ensure that your application is secure and only accessible to authorized users. This is a critical component of building robust and reliable web and mobile applications, and understanding how it works is essential for any Adama developer.
- Privacy and bubbles; controlling information disclosure is a vital aspect of any modern project, and Adama takes a unique approach to achieving this through privacy rules and visibility modifiers. By mastering Adama's privacy rules and visibility modifiers, you can control the information that your application exposes to its users and external entities. This is a critical component of building secure and reliable web and mobile applications, and Adama's approach sets it apart. Through these features, you can ensure that your application's data and logic remain protected and that your users have the best possible experience.
- Reactive formulas; learn how to compute data reactively based on changes to other data within the document.
- The glorious state machine; the state machine is a powerful tool for managing complex workflows and processes. By defining states and transitions, you can easily model the behavior of your system and handle different scenarios based on the current state.
- Async with channels, futures, and handlers; the document can accept messages directly or ask connected users for messages. Learn how to define handlers and ask user for messages.
Information is structured either for persistence or communication. Persistence refers to data that is stored for a long time and needs to be retrieved later, while communication refers to data that is transmitted from one point to another in real-time.
- Records; learn how to structure persistence within a document using records.
- Messages; learn how to structure communication to and within document using messages.
- Tables and integrated query; learn how to collect records and messages into tables which can be queried with integrated query.
- Anonymous messages and arrays; learn how to use anonymous messages to instantiate messages with or without a type.
- Maps and reduce; learn how to use maps as a basic collection.
Defining and changing state is great, but Adama takes it a step further by enabling connections to other services, handling web requests, and communication between documents. These additional capabilities allow Adama to operate within a larger ecosystem of services and data sources. With Adama, users can create sophisticated applications that interact with various data sources, making it a powerful tool for building complex systems.
- Web processing
- Interacting with remote services
- Talking to other Adama Documents as an Actor Network
Common language guide
- Comments are good for your health
- Constants
- Local variables and assignment
- Doing math
- Maybe some data, maybe not
- Standard control
- Functions, procedures, and methods oh my
- Enumerations and dynamic dispatch
Document layout
At the heart of Adama is a focus on data, which makes organizing your data for state management a critical component of building applications with this language. In Adama, state is organized at the document level as a series of fields, which represent different aspects of the state that your application needs to manage. By carefully laying out these fields, you can create a robust and efficient system for managing your application's state. For example, the Adama code below outlines three fields that might be used in an application:
public string output;
private double balance;
int count;
These three fields will establish a persistent document in JSON:
{"output":"","balance":0.0,"count":0}
The public and private modifiers control what users will see, and the omission of either results in private by default. In this case, users will see:
{"output":""}
when they connect to the document. Adama's strong privacy isolation guarantees ensure a clear separation between what users can see and what the system sees, creating a gap that protects sensitive data from unauthorized access.
The language has many types to leverage along with a more ways to expressive privacy rules.
Furthermore, state can be laid out with records, collected into tables, and computations exposed via formulas.
Include Statement
In Adama's data-centric approach, simple applications often don't require additional files. However, for larger projects, managing everything in a single file can be cumbersome. Adama supports splitting files using the @include keyword, without the .adama file extension, for example:
@include path/to/file;
Static policies and document events
In Adama, protecting the state of a document from unauthorized access or malicious actors is a crucial aspect of designing a secure and reliable application. In this section, we will delve into the details of access control and explore the key questions that arise in this context. Specifically, we will answer these questions:
- Who can create documents?
- Who can invent documents? And what does document invention mean?
- How do I tell when a document is loaded? How to upgrade document state?
- Who can connect to a document?
- Who can delete a document?
- Who can attach resources (i.e. files) to documents?
- What resource got attached? And when do assets get deleted?
One of the key features that sets Adama apart from other document stores is its approach to access control. In Adama, access control is built directly into the platform at the lowest level, rather than being implemented as yet another configuration on top of the system. This design choice ensures that security and privacy are core features of Adama, rather than afterthoughts or add-ons.
As a result, access control is an essential first step in building anything with Adama. By carefully designing your access control policies and privacy rules, you can ensure that your users' data is protected from unauthorized access or misuse, while still providing them with the functionality and features they need to get the most out of your application.
Static policies
Adama uses static policies to enforce access control rules that are evaluated without any state information, precisely because that state is not available at the time the policy is evaluated.
For example, the ability to create a new document in Adama requires a policy to be in place.
To define static policies, Adama provides the @static {} construct, which denotes a block of policies that are evaluated at the time the policy is enforced.
Within the @static block, developers can define a variety of policies, such as create and invent, that restrict or allow users' access to create documents.
These policies are evaluated based on the user's identity and other relevant metadata, such as their IP address or location, to determine whether they have permission to perform a particular action.
Answer: Who can create documents within your space?
The create policy within @static block is responsible for controlling who can create a document. The associated code block must return true to allow the document creation, and false to block creation.
@static {
create {
return true;
}
}
The above policy allows anyone to create a document within your space (#open #rude), so you will want to lock it down. For instance, we can lock it down to just adama developers.
@static {
create {
return @who.isAdamaDeveloper();
}
}
We can also validate the user is one of your people using a public key you provided via authorities.
@static {
create {
return @who.fromAuthority("Z2YISR3YMJN29XZ2");
}
}
The static policy also has context which provides location about where the user is connecting from using @context constant.
@static {
create {
return @who.isAdamaDeveloper() &&
@context.origin == "https://www.adama-platform.com";
}
}
From a security perspective, origin can't be trusted from malicious actors writing bots as they can forge the Origin header. However, the origin header is sufficient for preventing XSS attacks and limiting accidental usage across the web.
Answer: What is invention and who can invent documents within your space?
Document invention happens when a user attempts to connect to a document that doesn't exist.
If the document requires no constructor arg then the invent policy is evaluated.
If the invent policy returns true, then the document is created and the connect request is tried again.
This is useful for introducing real-time scenarios to an already mature user-base as construction can happen on-demand.
The invent policy works similar to create.
@static {
invent {
return who.isAdamaDeveloper();
}
}
The logic within invent can mirror that of create.
Static properties
With the @static block, we can also configure fixed properties that balance cost versus features or enable new modes.
For instance, the maximum_history property will inform the system how much history to preserve.
@static {
maximum_history = 500
}
Here, at least 500 changes to the document will be kept active.
We also have delete_on_close which will automatically delete the document once the document is closed.
This is useful for ephemeral experiences like typing indicators.
@static {
delete_on_close = true;
}
Document events
Document events are evaluated against a specific instance of a document. These events happen when a document is created, when a client connects or disconnects to a document, and when an attachment is added to a document.
Note: at this time, document events don't support @context. See issue #118
Construction: How to initialize a document?
Fields within a document can be initialized with a default value or via code within the @construct event.
// y has a default value of 42
public int y = 42;
// x has a default value = 0
public int x;
// who owns the document
public principal owner;
@construct {
owner = @who;
// overwrite the default value of x with 42
x = 42;
}
From a security perspective, it is exceptionally important to capture the creator (via the @who constant) for access control towards establishing an owner of the document as this enables more stringent access control policies.
The @construct event will fire exactly once when the document is constructed.
As documents can only be constructed once, this enables documents to have an authoritative owner which can be used within privacy policies and access control.
Load: how to run code when a document is loaded?
Since documents may need to experience radical change, the @load events provides an opportunity to upgrade data when loaded.
@load {
if (version < 2) {
// transfer data to new world
}
if (version < 3) {
// transfer data to super new world
}
version = 3;
}
Connected and Disconnected
The primary mechanism for users to get access to the document is via a persistent connection (vis-à-vis WebSocket) and then send messages to the document.
Before messages can be sent, the connection must be authorized by the document and this is done via the @connected event.
@connected {
return true;
}
The @connected event is the primary place to enforce document-level access control. For example, we can combine the constructor with the @connected event.
public principal owner;
public bool open_to_public;
@construct {
owner = @who;
open_to_public = false;
}
@connected {
if (owner == @who) {
return true;
}
return open_to_public;
}
If the return value is true then the connection is established.
Since the @connected event runs within the document scope, it can both mutate the document and lookup data within the document.
A more stringent policy would have a table with who can access the document.
Above, we always allow the owner to connect and a boolean controls whether a random person can connect.
Not only can they connect, but they also naturally disconnect (either on purpose or due to technical difficulties).
The disconnect signal is an informational event only, and is available via the @disconnected event.
@disconnected {
}
This allows us to mutate the document on a person disconnecting.
Delete
When document deletion is requested from via the API, the @delete event runs to validate the principal can delete the document.
@delete {
return @who == owner;
}
Asset Attachments
Adama allows you to attach assets to documents. Assets are essentially files or binary blobs that are associated with the document. Since the storage and association of assets is non-trivial, there are two document events for assets.
Answer: Who can attach a file to your document?
The @can_attach document event works much like @connnected in that the code is ran and the person attempting to upload is validated.
If the event returns true, then the user is allowed to attach the file.
return @who.isAdamaDeveloper();
}
This event primarily exists to protect user devices from erroneously uploading attachments. After this event returns true, the user will begin the upload which will durably store the file as an asset.
Answer: What resource was attached
Once the asset is durable stored, the @attached event is run with the asset as a parameter.
public asset most_recent_file;
@attached (what) {
most_recent_file = what;
}
The type of the what variable is asset which has the following methods.
| method | type | what it is |
|---|---|---|
| name() | string | The name provided by the uploader (i.e. file name) |
| id() | string | A unique id to denote the asset |
| size() | long | The number of bytes of the asset |
| type() | string | The Content type of the asset ( |
| valid() | bool | The asset is real or not. The default value for an asset is @nothing |
Note: at this time, using assets is a pain. See issue #120
Answer: How do assets leave
Since there is a maximum history for the lifetime of a document, assets are periodically collected and then garbage collected. Once an asset object leaves the document and the stored history, the associated bytes are cleaned up.
Note: this is not true at this time. See issue #121
Privacy and bubbles
Adama's focus on data privacy is a critical aspect of the language and is enforced through privacy checks on document fields and records. In this section, we will explore how Adama exposes data to users and the role of privacy modifiers in protecting sensitive information. 1At the heart of Adama's privacy system is the use of privacy modifiers, which are prefixes added to each field to control how they are accessed and by whom. These privacy modifiers allow you to control the visibility of each field and ensure that sensitive information is only accessible to authorized users.
By carefully managing the privacy of your fields and records, you can create a secure and reliable system for managing data in your Adama applications. This is particularly important in web and mobile applications, where sensitive information such as user credentials and financial data must be protected at all times. Adama's privacy system offers a unique and innovative approach to data protection, and by understanding how it works, you can build applications that are both efficient and secure. With Adama's support for privacy modifiers and other privacy features, you can create applications that meet the highest standards of data protection and ensure that your users' information is always safe and secure.
Shared-value modifiers
These modifiers are prefixes added to each field to control how they are exposed to users, and they allow you to specify who can see the data contained within. The following modifiers are commonly used in Adama to control field visibility:
| Modifier | Effect |
|---|---|
| public | Anyone can see it |
| private | No one can see it |
| viewer_is<field> | Only the viewer indicated by the given field is able to see it |
| use_policy<policy> | Validate the viewer can witness the value via code; policies are defined within documents and records via the policy keyword. |
record Row {
// it's public
public int pub;
// it's private, no one can see it
private int pri;
// a private person
private principal who;
// data that is only visible to the who
viewer_is<who> int whos_age;
// a custom policy based on code
use_policy<my_policy> int custom;
// defining the policy
policy my_policy(c) {
return pub < pri;
}
require p1;
}
table<Row> tbl;
// reveal mine via a formula where me represents the client viewing the document
bubble mine = iterate tbl where who == @who;
Viewer dependent modifiers
The bubble keyword is a powerful tool for controlling access to viewer-dependent data within a document.
Instead of using a policy to dictate who can see a shared value within a document, the bubble modifier allows you to create a custom computation for each viewer, ensuring that each user sees only the data that they are authorized to view.
One important caveat of using the bubble keyword to create privacy bubbles is that the resulting field is ephemeral and can only be seen by the connected viewer. This means that you cannot use a bubble field within the document itself, as it would not be visible to other logic.
// reveal mine via a formula where me represents the client viewing the document
bubble mine = iterate tbl where who == @who;
Diving Into Details
public/private
The private modifier hides data from users. The public modifier discloses data to users. If no modifier is specified, the default is private.
viewer_is<>
Inside the angle brackets denotes a variable local to the document or record which must be of type client. For instance:
principal owner;
viewer_is<owner> int data_only_for_owner;
Here, the field owner is referenced via the privacy modifier for data_only_for_owner such that only the device/client authenticated can see that data.
use_policy<> & policy
As visibility may depend on some intrinsic logic or internal state, use_policy will leverage code outlined via a policy. This code is then run when the client wishes to see the data.
record Card {
// some internal state
private bool played;
// who owns the card
private principal owner;
// the value of the card
use_policy<is_in_play> value; // 0 to 51 for a standard playing deck
// who can see the card
policy is_in_play {
// if it has been played, then everyone knows
// otherwise, only the owner can see it
return played || owner == @who;
}
}
bubble<>
While privacy policies ensure compliance, we can leverage bubbles to efficiently query the document based on the viewer.
table<Card> deck;
bubble hand = iterate deck where owner == @who;
Reactive formulas
Adama draws inspiration from spreadsheets and their ability to do more than just organize data into tables. By utilizing formulas, spreadsheets can perform useful computations, a concept that forms the basis of Adama's reactive programming model.
One of Adama's defining features is its simplicity in defining formulas, as demonstrated in the following example:
public int x;
public int y;
public formula len = Math.sqrt(x * x + y * y);
The formula identifier in Adama serves as a type that allows expressions to be combined into mathematical expressions using any previously defined state or other formulas.
However, there are two key rules to keep in mind.
Firstly, the right-hand side of the formula must be "pure," meaning it cannot mutate the document in any way. This restriction limits the use of only math and functions, while procedures are strictly prohibited. Secondly, the right-hand side must only refer to a state defined before the introduction of the formula, which effectively prevents circular logic.
In terms of performance and semantics, formulas in Adama are 100% lazy. No computation is executed until the data is requested, and the result is cached until the underlying data is invalidated. If changes occur in the data, the result is discarded until the next time the data is accessed.
The state machine
Each document in Adama acts as a state machine where there is a single state label indicating the major state of the document. The rest of the document is considered supporting or related state included within the state machine. This approach simplifies the coding process. Initially, the code is associated with a state machine label:
#start {
/* fun times */
}
Second, transitioning into a state within the state machine is done via the transition keyword.
This keyword allows you to specify the new state label.
@construct {
transition #state;
}
The transition keyword not only allows you to transition to a new state but can also delay the transition using the in keyword, which specifies the time in seconds.
This is useful when you want to schedule a future transition, for example, transitioning to a different state after a certain amount of time has passed.
By specifying the delay in seconds, you can set a timer to transition automatically to the desired state.
bool done;
@construct {
done = false;
transition #state;
}
#start {
transition #end in 60;
}
#end {
done = true;
}
Async with channels, futures, and handlers
Handling messages directly
When a user connects to a document, the main way they can interact with it is by sending messages to the document. A message for this purpose typically includes a number of fields, such as the message type, the user's ID, and other message content. The document can then process the message and update accordingly, potentially changing its state or sending messages to other services.
The following example has a single document field along with a message.
public string output = "Hello World";
message ChangeOutput {
string new_output;
}
In order to establish communication between the user and the document, a channel is used to open a pathway for messages to execute code. Adding a message handler is one way to achieve this. A message handler is a function that gets called when a specific message is received on the channel. This function takes the message as its input, and it can execute any necessary code in response to the message.
channel change_output(principal sender, ChangeOutput change) {
output = change.new_output;
}
In the example provided, the channel named 'change_output' is the pathway that clients will use to send their messages to trigger the associated code. It is important to note that multiple channels with the same message type can be introduced to the system.
channel change_output(principal sender, ChangeOutput change) {
output = change.new_output;
}
channel set_output(principal sender, ChangeOutput change) {
output = change.new_output;
}
Waiting for users via futures
The async/await pattern within code is a useful way to combine multiple messages in an orderly fashion, and Adama was designed with board games in mind. To use this pattern, a message type and an incomplete channel need to be defined. This pattern is useful for games that involve multiple players taking turns or for applications that require the processing of a series of events in a specific order.
In asynchronous programming, message handlers or state machine transitions can be blocked using the await keyword.
This is particularly useful when it's necessary to ensure that messages arrive in a specific order, even when writing synchronous code.
By blocking the message handler or state machine transition using await, the document can wait for a specific event to occur before proceeding to the next step.
This can help prevent errors or unexpected behavior that might occur if the events were not processed in the correct order.
This is the secret sauce that enables board games and workflow processing.
In this example, we define an incomplete channel.
message SomeDecision {
string text;
}
channel<SomeDecision> decision;
An incomplete channel can be created and then used in either a message handler or a state transition. The use of a state transition can be particularly useful when soliciting decisions from multiple users. For example, in a scenario where two users need to make a decision, a state transition can be used to prompt each user for their input in turn. By leveraging an incomplete channel in this way, the program can ensure that it receives the necessary input from both users before proceeding to the next step in the process.
private principal player1;
private principal player2;
#getsome {
future<SomeDecision> sd1 = decision.fetch(player1);
future<SomeDecision> sd2 = decision.fetch(player2);
string text1 = sd1.await().text;
string text2 = sd2.await().text;
// do something with text1 and text2 to decide a winner, I guess?
}
This decoupling of asking a person (i.e. the fetch) and getting the data in code (i.e. the await) enables concurrency, allowing two users to come up with the message independently.
Note that this approach can improve the efficiency of the program and enable multiple tasks to be performed simultaneously.
methods on channel<T>
| method signature | return type | behavior |
|---|---|---|
| fetch(principal who) | T | Block until the principal returns a message |
| decide(principal who, T[] options) | maybe | Block until the principal return a message from the given array of options |
methods on channel<T[]>
| method signature | return type | behavior |
|---|---|---|
| fetch(principal who) | T[] | Block until the principal returns an array of message |
| choose(principal who, T[] options, int limit) | maybe<T[]> | Block until the principal returns a subset of the given array of options |
Records
To structure information for persistence, Adama uses a record, which is a collection of fields that represent a specific type of data. These fields can be assigned values and then stored in the document, a table, another record, or even a map. Records can be customized with privacy rules and visibility modifiers to control access to the data they contain.
record Person {
public string name;
private int age;
private double balance;
}
Adama's data elements reflect the structure of data in the the root document, but the record type offers additional flexibility. Records can be used in multiple ways, such as being nested within another record.
record Relationship {
public Person a;
public Person b;
}
By enabling records to be nested within each other, Adama establishes a foundation for constructing composite types and collections. This straightforward re-use of records is fundamental to building more complex data structures.
See:
- types for more information on which types can go within records.
- privacy policies for how privacy per field is specified within a record.
- bubbles for how data is exposed based on the viewer from the record.
- reactive formulas for how to expose reactively compute data to the viewer of record.
In addition to being nestable and reusable, records in Adama come equipped with several useful features. They can have methods, can declare privacy policies, and hint at indexing for tables.
If a record is used within a table, an implicit field called id is created with an integer type.
To facilitate communication via messages, Adama provides a free helper that easily converts a record to a message.
Methods
We can associate code with a record via a method, allowing for increased functionality and flexibility. For example, a method can be used to mutate a record, which can be helpful for consolidating how records change over time. By providing a way to associate code with a record, Adama makes it possible to implement complex logic and functionality directly within the data structure itself.
For example, the following record, R, has a method to zero out the score.
record R {
public int score;
method zero() {
score = 0;
}
}
Methods can be marked as read-only. This means that these methods are not permitted to mutate the document, which makes them available for use in reactive formulas. By designating certain methods as read-only, Adama provides a way to ensure that these methods do not interfere with other parts of the data structure or cause unintended side effects.
record R {
public int score;
method double_score() -> int readonly {
return score * 2;
}
public formula ds = double_score();
}
Policies
Records can express policies that are bits of code associated with the record and identified by the @who keyword.
These policies specify the access permissions for the record and provide a way to restrict or control how the record is used or modified.
By associating policies with records, Adama enables the implementation of fine-grained security and access controls within the data structure itself.
record R {
private principal owner;
policy is_owner {
return owner == @who;
}
}
Policies can also be used to protect individual fields within a record. By associating a policy with a specific field, access to that field can be restricted or controlled based on the user's permissions or other criteria. This allows for a more granular level of control over data access and modification, providing enhanced security and flexibility for complex data structures.
record R {
private principal owner;
use_policy<is_owner> int balance;
policy is_owner {
return owner == @who;
}
}
Policies can also be used to protect the entire record. By associating a policy with the record as a whole, access to the record can be restricted or controlled based on the user's permissions or other criteria. In this case, the visibility and existence of the record is determined by whether the policy returns true or false.
record R {
private principal owner;
public int balance;
policy is_owner {
return owner == @who;
}
require is_owner;
}
Indexing tables
The best mental model for a record is that of a row within a table. By default, each row has a primary key index on the id field, which has a type of int. This makes it easy to reference and manipulate individual rows within a table, as well as to perform fast lookups and queries.
In addition to the primary key index, Adama also allows for additional fields within a record to be indexed. This can be particularly useful for speeding up queries and searches within large data sets. By indexing specific fields, Adama can quickly locate and retrieve the records that match a given set of criteria, which can be critical for performance in many real-world applications.
In this example, we introduce a secondary key and instruct the record to index it.
record R {
private int key;
index key;
}
table<R> _table;
In Adama, the index keyword can be used to inform a table that it can group records by a specific field, known as the key, in order to reduce the number of candidates considered during a where clause.
By creating an index on the key field, Adama can more efficiently locate the records that match a given query, which can result in significant performance improvements.
Easily convert to a message for communication
The @convert keyword can be used to convert a message or record into a message type.
This is a useful feature for communicating with external systems or other parts of an application that expect data to be formatted in a particular way.
record R {
public int x;
}
R r;
message M {
int x;
}
#sm {
M m = @convert<M>(r);
}
The ability to convert records into a message using the @convert keyword can be incredibly useful in a variety of situations.
For example, when working with channels and futures are outlined, it may be necessary to present users with a list of options derived from a table, which can be accomplished by converting the table data to a specific message type.
Similarly, when sending records to another service using Adama services, it may be necessary to convert the data to a specific format in order to ensure compatibility with the receiving system.
Messages
A message is essentially a simplified version of a record, lacking privacy awareness and privacy concerns, and without formulas or bubbles. It provides a limited form of methods compared to records. All fields within a message are public, making it suitable for use by users. In contrast to records, which are designed to store data within the system, messages are intended to be used for communication with external services or between different parts of the system.
The following defines a real-world message:
message JoinGroup {
string name;
}
Within a message, it is possible to define almost all types that can be defined within code, with the exception of channels, services, and futures. It is important to note that all data defined within a message must be complete in a serialized form. Messages can also be constructed anonymously on the fly, which allows for easy and efficient communication between different parts of the system.
#yo {
let msg = {x:1, y:2};
}
Messages undergoes static type rectification, which means that any type errors are detected at compile time rather than runtime. This makes message handling safer and more reliable. Additionally, Adama supports a simplified form of type inference, which means that messages of a known type can be constructed without having to explicitly declare their types.
message M {
int x;
int y;
}
@construct {
M m = {x:1, y:1};
}
Methods
In a message, methods can be defined, but they are more limited compared to records. Methods within messages can only reference data from within the message as messages, and cannot reference data outside of the message, unlike methods in records which can reference data from the entire document. This is because messages are designed to be used for communication and are often sent over the network, so they should be self-contained and not rely on external data.
message X {
int val;
method succ() -> int {
return val + 1;
}
}
A collection of messages is a native table
Messages, like records, can be put into a table within code. They can also be used in other ways that records can, such as being used as parameters or return types for functions. However, since messages lack privacy policies and formulas, they may not be suitable for all use cases where records are used. When messages are put into a table, they are not indexed as there is no primary key.
message M {
int x;
int y;
}
#turn {
table<M> tbl;
tbl <- {x:1, y:1};
tbl <- {x:1, y:2};
}
Tables and integrated query
Tables are Adama's primary way to collect and query records. They are similar to tables in relational databases and are based on the same concepts. Adama uses relational database ideas to construct and query tables, which is why the relational database literature is an excellent way to think about data in Adama. Adama tables allow users to store data and query it using a variety of methods, such as sorting, filtering, and grouping. Tables in Adama are powerful tools for managing data and analyzing it in a structured way.
For example, a record can be used to define the structure of a row within a table. Consider this record.
record Rec {
public int id;
public string name;
public int age;
public int score;
}
We can then use this record type to define a table called _records.
Note, the underscore has become a convention within Adama as tables are never directly visible to users and there is no available privacy modifier.
table<Rec> _records;
A table is a way of organizing information per given record type, and a table is a useful construct that enables many common operations found in data structures, such as adding, updating, and querying records. The above table can contain data such as:
| id | name | age | score |
|---|---|---|---|
| 1 | Joe | 45 | 1012 |
| 2 | Bryan | 49 | 423 |
| 3 | Jamie | 42 | 892 |
| 4 | Jordan | 52 | 7231 |
The id field is a primary key that is automatically generated by the system for each new record.
The name, age, and score fields yield information about a person and their score in the office game of trash can basketball.
Adding rows/records to table via ingestion
The ingestion operator (<-) allows data to be inserted from a variety of sources. For instance, we can simply use ingestion to copy a message into a row.
record Rec {
public int x;
public int y;
}
message Msg {
int x;
int y;
}
table<Rec> tbl;
channel foo(Msg m) {
tbl <- m;
}
#foo {
tbl <- {x:42, y:13};
}
Notes about the special id field. If a record has the 'id' field, then it must be an integer. ingestion will generate an id, and we can get that via the 'as' keyword.
channel foo(Msg m) {
tbl <- m as m_id;
}
#foo {
tbl <- {x:42, y:13} as xy_id;
}
Reactive lists
Lists of records can be filtered, ordered, sequenced, and limited via language integrated query (LINQ).
iterate
First, the iterate keyword will convert the table<Rec> into a list<Rec>.
public formula all_records =
iterate _records;
Now, by itself, it will list the records in their canonical ordering (by id). It is important to note that the list is lazily constructed up until the time that it is materialized by a consumer, and this enables some query optimizations to happen on the fly.
where
We can suffix a LINQ expression with where to filter items.
public formula young_records =
iterate _records
where age < 18;
where_as
Simillar to where, except we bind the record to a variable rather than build an environment. This has the advantage of eliminating conflicts between the variables feeding the query versus variables within
view int age;
bubble records_younger_than_viewer =
iterate _records
where_as x: x.age < @viewer.age;
indexing!
Yes, we can make things faster by indexing our tables. The index keyword within a record will indicate how tables should index the record.
public formula lucky_people =
iterate _records where age == 42;
This will accelerate the performance of where expressions when expressions like age == 42 are detected via analysis.
shuffle
The canonical ordering by id is not great for card games, so we can randomize the order of the list. Now, this will materialize the list.
public formula random_people =
iterate _records shuffle;
public formula random_young_people =
iterate _records where age < 18 shuffle;
reduce
Reduce allows taking the result and reducing it into a map via a function.
public formula grouped_by_x =
iterate _records
reduce on x via (@lambda list: list);
The reduce expression will take the list and group items into lists with a common field value, and then send the list to a function.
For more details, see Maps and reduce
order
Since the canonical ordering by id is the insertion/creation ordering, order allows you to reorder any list.
public formula people_by_age =
iterate _records
order by age asc;
order_dyn
Many times, the user wants to be in control of ordering the results of a query. This is available via order_dyn where the right hand expression is a string containing ordering instructions.
For example, a string of form "age" would sort records by age in ascending order while a string like "-age" would sort in descending order. This compose via a comma such that "age,name" would sort by age first, and everyone with the same age would be sorted by name.
view string sort_people_by;
bubble people =
iterate _records
order_dyn @viewer.sort_people_by;
limit
public formula youngest_person =
iterate _records
order by age asc
limit 1;
offset
With offset, you can skip the first entries with a query.
public formula next_youngest_person =
iterate _records
order by age asc
offset 1
limit 1;
Bulk Assignments
A novel aspect of a reactive list is bulk field assignment, and this allows us to do some nice things. Take the following definition of a Card table representing a deck of cards:
record Card {
public int id;
public int value;
public principal owner;
public int ordering;
}
table<Card> deck;
We can shuffle the deck using shuffle and bulk assignment.
procedure shuffle() {
int ordering = 0;
(iterate deck shuffle).ordering = ordering++;
}
This assignment of ordering will memorize the results from shuffling. With a single statement, we can deal cards by assigning ownership.
procedure deal_cards(principal who, int count) {
(iterate deck // look at the deck
where owner == @no_one // for each card that isn't own
order by ordering asc // follow the memoized ordering
limit count // deal only $count cards
).owner = who; // for each card, assign an owner to the card
}
This ability makes it simple to update a single field, but it also applies to method invocation as well.
Bulk method execution
Similar to a bulk assignment, bulk method execution allow executing a method on every record within a result.
record Rec {
int x;
method zero() {
x = 0;
}
}
table<Rec> tbl;
procedure zero_records() {
(iterate tbl).zero();
}
Bulk Deletes
Every record has an implicit delete method which will remove the record from the owned table.
procedure trash_cards_randomly(principal who, int count) {
(iterate deck // look at the deck
where owner == who // for each card that isn't own
shuffle // randomize the cards
limit count // deal only $count cards
).delete();
}
Anonymous messages and arrays
Adama is a programming language that allows messages and arrays to be constructed as literals, similar to how objects and arrays can be written in JavaScript. This means that developers can write code more efficiently and succinctly, by directly specifying the values of messages and arrays in the code itself.
Messages
Anonymous messages (or message literals) are a way to construct messages without explicitly defining a type beforehand. To create an anonymous message in Adama, braces are used to indicate the beginning and end of an object, similar to how this is done in JavaScript/JSON. For example, a simple message can be created using the following syntax:
@construct {
let m = {cost:123, name:"Cake Ninja"};
}
Messages can be given a named type, and the type system uses a weak form of inference to convert anonymous messages to explicitly named message types. This means that, when an anonymous message is created, the type system can automatically infer the type of the message based on its structure and the types of its fields. By doing so, the message can be converted to an explicitly named type, which can help ensure that the message is properly typed and structured according to its intended use.
message M {
int cost;
string name;
}
@construct {
M m = {cost:123, name:"Cake Ninja"};
}
This weak form of type inference is done via type rectification. Type rectification is the process of taking two values of different types and finding (or creating) a type that can hold both values. This process is used to ensure that messages can be correctly processed, even when they have different structures or types. For example, the rectified type of an int and a double is double, because double can hold both types of values. Similarly, when rectifying messages with distinct fields, the resulting rectified type is a message that includes all of the original fields, but with their new types wrapped in maybes.
This approach allow static typed systems to compete with duck typing.
Arrays
In Adama, anonymous arrays (or array literals) are supported and can be created using the brackets syntax, which is similar to JavaScript. This approach provides a convenient way to create arrays without explicitly defining their type beforehand. For example, the following code creates an array:
@construct {
let a = [1, 2, 3];
}
Anonymous arrays are statically typed, which means that the elements within them must have a compatible type under type rectification. This ensures that the elements can be properly processed and compared within the array. It's important to note that the process of type rectification is necessary in cases where the elements have different types.
A good example of this is the following code snippet, which creates an array with using different types of elements rectified into one common type.
@construct {
let a = [{x:1}, {y:2}, {z:3}];
}
The common type generated is
message GeneratedType123 {
maybe<int> x;
maybe<int> y;
maybe<int> z;
}
Working with arrays
When you have an array like:
@construct {
int[] a = [1, 2, 3];
}
The primary way of accessing a particular element in an array is through the index lookup operator ([int]).
However, the result of the index operator has a particular twist in Adama's type system, which aims to maximize safety.
Specifically, the index operator always returns a maybe type, which means that the result may or may not exist.
This approach helps to prevent errors and ensure that the code is always properly typed and safe.
For example, consider the following code snippet, which attempts to access the second element in an array:
@construct {
int[] a = [1, 2, 3];
maybe<int> second = a[1];
}
The result type is maybe<int> which requires a second inspection to determine if it exists, and this both forces the checking of range and contends with invalid ranges.
The only way to really know the value of the second index is via an if statement like so:
@construct {
int[] a = [1, 2, 3];
maybe<int> second = a[1];
if (second as actual_second) {
// ok, do whatever you want
} else {
// range failure
}
}
While this approach may seem cumbersome at first, it ultimately helps to ensure that the code is properly typed and can handle cases where the requested element does not exist or is out of range. By forcing the programmer to check for the existence of a value using an if statement, Adama helps to avoid unexpected runtime errors and promotes safer, more robust code. While this approach may require more verbose code, it ultimately helps to prevent issues that could lead to difficult-to-debug errors.
Iterating through arrays
An array should be interated via a foreach loop, see Standard Control. The size of an array size can be accessed via .size() to utilize a for loop.
Maps and reduce
Explicit maps
Adama supports maps from integral and string types to other types.
record Point {
int x;
int y;
}
table<Point> pointdb;
map<string, Point> named_points;
map<int, Point> index_points;
Maps via reduction
Many times, we need to group things in a table by a common property. Here, this is done via the reduce function.
enum Breed { Lamancha:1, Boer:2, Numbian:3, Pygmy:4, Alpine:5 }
record Goat {
Breed breed;
}
table<Goat> goats;
public formula grouped_by_breed = iterate goats reduce breed via (@lambda x: x);
Graph Indexing
A common pattern within Adama is nesting tables within records which themselves are in a table, and pattern trade space for reduced document size and reactivity pressure. Consider the following specification
record User {
public int id;
public string name;
public principal account;
}
table<User> _users;
record Member {
int user_id;
}
record Group {
public int id;
public string name;
table<Member> _members;
}
table<Group> _groups;
The problem with the above specification is that if you want to find all the groups for a specific user, then you have to iterate over every group. The normal way to do this within an RDBMS is to have a table relating users to groups, but this introduces replication of the associated group_id and the blast radius of reactive flux increases. Instead, Adama supports graph indexing via association maps which are a many-to-many index.
Using Assoc
In the above example, we can retrofit an index between User and Group via the assoc keyword.
assoc<User,Group> _users_to_groups;
At this moment, it is empty, so we populate it by having the _members table join in
record Group {
public int id;
public string name;
table<Member> _members;
join _users_to_groups via _members[x] from x.user_id to id;
}
This now binds the group's record (and lifetime) with the elements within the table. The table now drives a partial aspect of the graph such that as members come and go, the graph will update. This creates an index of users to the associate group id, and we can use this via the traverse keyword.
bubble my_groups = iterate _users where account == @who traverse _users_to_groups;
This transforms the list<User> into a list<Group> where the user is the viewer and the group was joined to that user via the assoc table.
Web processing
Your adama script is a webserver! Each Adama document is an opinionated webserver supporting GET, PUT, OPTIONS, and DELETE methods. These methods can return HTML, JSON, or XML.
Documents are addressable within a region via a URL of the form:
https://$region.adama-platform.com/$space/$key/$path
Where $region is the region to request the data from, $space is the adama's script name, $key is the document key, and the $path is then handed over to the specified document.
GET
@web get / {
return {
html: "Oh, Hello there! this is the root document"
};
}
OPTIONS (Cors Preflight)
@web options / {
return {
cors: true
};
}
PUT (& POST)
Adama normalizes url-encoded bodies into JSON objects, and converts POST into PUT.
message TwilioSMS {
string From;
string Body;
}
@web put /webhook (TwilioSMS sm) {
return {
xml: "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<Response><Message>Thank you for the data. NOM. NOM.</Message></Response>"
};
}
DELETE
@web delete / {
return {
json: {}
};
}
Query parameters
The @web handler has @parameters (a special constant) for accessing the query parameters as a dynamic.
Headers
The @web handler has @headers (a special constant) for accessing the headers parameters as a map<string,string>.
Responding
The return value on a @web is a message that is compile-time interpreted with rules. This message controls the behavior of the web server
The body
The returned message within a @web may contain at most one body field.
| field | value type | behavior |
|---|---|---|
| json | message | the message is converted to JSON and sent to the client with content type 'application/json' |
| xml | string | the string is sent to the client with content type 'application/xml' |
| css | string | the string is sent to the client with content type 'text/css' |
| js | string | the string is sent to the client with content type 'text/javascript' |
| error | string | the string is sent to the client with content type 'text/error' |
| html | string | the string is sent to the client with the content type 'text/html' |
| asset | asset | the asset is downloaded and sent to the client with the appropriate content type |
| sign | string agent | the agent is is treated as a document agent and turned into a JWT token signed by Adama (see auth) |
| identity | string | yield a pre-signed identity |
| forward | url | perform a redirect using 302 (permanent) |
| redirect | url | perform a redirect using 301 (temporary) |
Cross origin resource sharing
The returned message within a @web may set a 'cors' field to true.
This will allow the request to be visible to a browser.
@web get / {
return {json:{}, cors: true}
}
Caching
Adama supports caching using both internal and browser caching. This is achieved via the 'cache_ttl_seconds' field.
@web get / {
return {json:{}, cache_ttl_seconds:60}
}
Interacting with remote services
Adama supports third party services that allow the document to escape it's container and talk to the fullness of the world.
Google SSO
A simple way to leverage google to provide single-sign on is to get a client token and then have the server convert that token to an email.
// this brings the service into the document
@link googlevalidator {}
message GoogleSignin {
string token;
}
@web put /google (GoogleSignin gs) {
// invoking the service method available
if (googlevalidator.validate(@who, {token:gs.token}).await() as validated) {
if((iterate _users where email == validated.email)[0] as user) {
return {sign:"" + user.id};
} else {
return {error:"Not a valid user in the system"};
}
}
return {error:"Failed to Sign in with Google", cors:true};
}
Built-in services
TODO: Code generate this!
Talking to other Adama Documents as an Actor Network
Types
Adama has many built-in primal types! The following tables outline which types are available.
| type | contents | default | fun example |
|---|---|---|---|
| bool | bool can have one of the two values true or false. | false | true |
| int | int is a signed integer number that uses 32-bits. This results in valid values between −2,147,483,648 and 2,147,483,647. | 0 | 42 |
| long | long is a signed integer number that uses 64-bits. This results in valid values between -9,223,372,036,854,775,808 and +9,223,372,036,854,775,807. | 0 | 42 |
| double | double is a floating-point type which uses 64-bit IEEE754. This results in a range of 1.7E +/- 308 (15 digits). | 0.0 | 3.15 |
| complex | complex is a tuple of two doubles under the complex field of numbers | 0 + 0 * @i | @i |
| string | string is a utf-8 encoded collection of code-points. | "" (empty string) | "Hello World" |
| label | label is a pointer to a block of code which is used by the state machine, | # (the no-state) | #hello |
| principal | principal is a reference to a connected person, and the backing data establishes who they are. This is used for acquiring data and decisions from people, | @no_one | @no_one |
| dynamic | a blob of JSON | @null | @null |
Call-out to other types
The above built-in types are building blocks for richer types, and the below table provides callouts to other type mechanisms. Not all types are valid at the document level.
| Type | Quick call out | Applicable to document/record |
|---|---|---|
| assets | An asset is an externally stored byte blob | yes |
| enum | An enumeration is a type that consists of a finite set of named constants. | yes |
| messages | A message is a collection of variables grouped under one name used for communication via channels. | only via a formula |
| records | A record is a collection of variables grouped under one name used for persistence. | yes |
| maybe | Sometimes things didn't or can't happen, and we use maybe to express that absence rather than null. Monads for the win! | yes (only for applicable types) |
| table | A table forms the ultimate collection enabling maps, lists, sets, and more. Tables use records to persist information in a structured way. | yes |
| channel | Channels enable communication between the document and people via handlers and futures. | only root document |
| future | A future is a result that will arrive in the future. | no |
| maps | A map enables associating keys to values, but they can also be the result of a reduction. | yes |
| lists | A list is created by using language integrated query on a table | yes |
| arrays | An array is a read-only finite collection of a adjacent items | only via a formula |
| result | A result is the ongoing progress of a service call made to a remote service | only via a formula |
| service | A service is a way to reach beyond the document to a remote resources | only root document |
Rich Types
Complex Numbers
Adama supports complex numbers out-of-the-box with the traditional mathematical operations.
Methods
| method | behavior |
|---|---|
| len | returns the length of the complex number |
maybe<double>
dynamic
lists
transforms
operations
Comments are good for your health
We humans need to "enhance" our logic with prose and explanation for others humans (and future versions of ourselves). Since code should be manageable and understandable over time via different people, Adama supports C style comments.
// This is a comment with a single line which terminates at the ->\n
/* This is a comment with multiple lines
It can have oh so many lines.
* <- why not? it's freeform madness!
*/
int x /* and can be embedded anywhere */ = 123;
This enables comments to be sprinkled liberally within Adama code.
A Tiny (kind of useless) Technical Detail
Comments are part of the syntax tree for Adama as part of hidden meta-data on tokens. This is so that comments are available to tooling such that error messages can more helpful, but also so documentation can be generated and shared with document consumers.
Comments associate with tokens can be either in a forwards or backwards manner. Comments on multiple lines such as:
/**
* foo
*/
always associate forward. For instance the comment in
/* age of the user */
int age;
is associated to the 'int' token. Whereas single line comment like
int age; // age of the user
usually associate backwards. Here, the comment is associated with the ';' token. Sometimes, the single line comment will associate forward but only after a multi-line comment has been introduced. For instance
/* the age */ // of the user
int age;
will associate both comments to the 'int' token.
Constants
You want numbers? We got numbers. You want strings? We got strings. You want complex numbers, we got complex numbers! Constants are a fast way to place data into a document. For instance, the following code outlines some basic constants:
#we_got_constants {
int x = 123;
int y = 0x04;
double z = 3.14;
bool b = true;
principal c = @no_one;
complex cx = 1 + @i;
}
Details
There are a variety of ways to conjure up constants. The following table illustrates examples:
| type | syntax | examples | |
|---|---|---|---|
| bool | (true, false) | false, true | |
| int | [0-9]+ | 42, 123, 0 | |
| int | 0x[0-9a-fA-F]+ | 0xff, 0xdeadbeef | |
| double | [0-9].?[0-9]([eE](0-9)+)? | 3.14, 10e19, 2.72e10 | |
| string | "(^" | escape)*" | "", "hello world", "" |
| label | #[a-z]+ | #foo, #start | |
| principal | @no_one | @no_one | |
| maybe<?> | @maybe<Type> | @maybe<int> | |
| maybe(?) | @maybe(Expr) | @maybe(123) | |
| complex | @i | 1 + @i |
@who is executing
The @who constant refers to the principal that is executing the current code.
@context of the caller
Within static policies, document constructors and events, and message handlers there is constant @context which is useful for getting access to the origin and ip or the caller.
@web's @parameters and @headers
The web handler has access to the parsed query string and HTTP headers respectively via the @parameters and @headers constants.
@parameters is a dynamic with the query string converted to JSON.
@headers is a map<string,string>.
Bubble's @viewer
A privacy bubble can access viewer state via the @viewer which behaves like a message.
Dynamic @null
The default dynamic type has a value of "null" which is represented via @null.
String escaping
A character following a backslash (\) is an escape sequence within a string, and it is an escape for the parser to inject special characters. For instance, if you are parsing a string initiated by double quotes, then how does one get a double quote into the string? Well, that's what the escape is for. Adama's strings support the following escape sequences:
| escape code | behavior |
|---|---|
| \t | a tab character |
| \b | a backspace character |
| \n | a newline |
| \r | a carriage return |
| \f | a form feed |
| " | a double quote (") |
| \\ | a backslash character (\) |
| \uABCD | a unicode character formed by the four adjoined hex characters after the \u |
Local variables and assignment
While document variables are persisted, variables can be defined locally within code blocks (like constructors to be used to compute things. These variables are only used to compute.
private int score;
@construct {
int temp = 123;
temp = 42;
}
Define by type
Native types can be defined within code without a value as many of them have defaults:
#transition {
int local;
local = 42;
string str = "hello";
}
The default values follow the principle of least surprise.
| type | default value |
|---|---|
| bool | false |
| int | 0 |
| long | 0L |
| double | 0.0 |
| string | "" |
| list<T> | empty list |
| table<T> | empty table |
| maybe<T> | unset maybe |
| T[] | empty array |
readonly keyword
A local variable can be annotated as readonly, meaning it can not be assigned.
#transition {
readonly int local = 42;
}
This is fairly verbose, so we introduce the let keyword.
Define via the "let" keyword and type inference
Instead of leading with the readonly and the type, you can simply say "let" and allow the translator to precisely infer the type and mark the variable as readonly.
#transition {
let local = 42;
}
This simplifies the code and the aesthetics.
Math-based assignment, increment, decrement
Numerical types provide the ability to add, subtract, and multiply the value by a right-hand side. Please note: division and modulus are not available as there is the potential for division by zero, and division by zero is bad.
#transition {
int x = 3; // 3
x *= 4; // 12
x--; // 11
x += 10; // 21
x *= 2; // 42, the cosmos are revealed
x++;
}
List-based bulk assignment
Lists derived from tables within the document provide a bulk assignment via '=' and the various math based assignments (+=, -=, *=, ++, --).
record R {
int x;
}
table<R> _records;
procedure reset() {
(iterate _records).x = 0;
}
procedure bump() {
(iterate _records).x++;
}
Doing math
Adama lets you do math, and that's awesome! It has the typical operations that you would expect, and then some fun twists. So, let's get into it.
Operators
Parentheses: ( expr )
You can wrap any expression with parentheses, and parentheses will alter the precedence of evaluation. See operator precedence section for details about operator precedence.
Sample Code
public int z;
@construct {
z = (1 + 2) * 3;
}
Result
{"z":6}
Typing: The resulting type is the type of the sub-expression.
Unary numeric negation: - expr
When you want to turn a positive into a negative, a negative into a positive, a smile into a frown, a frown upside down, or reflect a value over the y-axis. This is done with the subtract symbol prefixing any expression.
Sample Code
public int z;
public formula neg_z = -z;
@construct {
z = 42;
}
Result
{"z":42,"neg_z":-42}
Typing: The sub-expression type must be an int, long, or double. The resulting type is the type of the sub-expression.
Unary boolean negation / not / logical compliment: ! expr
Turn false into true, and true into false. This is the power of the unary Not operator using the exclamation point !. Money back if it doesn't invert those boolean values!
Sample Code
public bool a;
public formula not_a = !a;
@construct {
a = true;
}
Result
{"a":true,"not_a":false}
Typing: The sub-expression type must be a bool, and the resulting type is also bool.
Addition: expr + expr
You'll need to use addition to count the phat stacks of money you'll earn with a computer science degree.
Sample Code
public int a;
public formula b = a + 10;
public formula c = b + 100;
@construct {
a = 1;
}
Result
{"a":1,"b":11,"c":111}
Typing: The addition operator is commonly used to add two numbers, but it can also be used with strings and lists. The following table summarizes the typing and behavior:
| left type | right type | result type | behavior |
|---|---|---|---|
| int | int | int | integer addition |
| double | double | double | floating point addition |
| double | int | double | floating point addition |
| int | double | double | floating point addition |
| long | long | long | integer addition |
| long | int | long | integer addition |
| int | long | long | integer addition |
| string | string | string | concatenation |
| int | string | string | concatenation |
| long | string | string | concatenation |
| double | string | string | concatenation |
| bool | string | string | concatenation |
| string | int | string | concatenation |
| string | long | string | concatenation |
| string | double | string | concatenation |
| string | bool | string | concatenation |
| list<int> | int | list<int> | integer addition on each element |
| list<int> | long | list<long> | integer addition on each element |
| list<int> | double | list<double> | floating point addition on each element |
| list<long> | int | list<int> | integer addition on each element |
| list<long> | long | list<long> | integer addition on each element |
| list<double> | int | list<double> | floating point addition on each element |
| list<double> | double | list<double> | floating point addition on each element |
| list<string> | int | list<string> | concatenation on each element |
| list<string> | long | list<string> | concatenation on each element |
| list<string> | double | list<string> | concatenation on each element |
| list<string> | bool | list<string> | concatenation on each element |
Subtraction: expr - expr
You'll need the subtract operator to remove taxes from your phat stack of dolla-bills.
Sample Code
public int a;
public formula b = a - 10;
public formula c = b - 100;
@construct {
a = 1000;
}
Result
{"a":1000,"b":990,"c":890}
Typing:
The subtraction operator is commonly used to subtract a number from another number, but it can also be used with lists. The following table summarizes the typing and behavior.
| left type | right type | result type | behavior |
|---|---|---|---|
| int | int | int | integer subtraction |
| int | double | double | floating point subtraction |
| double | double | double | floating point subtraction |
| double | int | double | floating point subtraction |
| long | int | int | integer subtraction |
| long | long | long | integer subtraction |
| int | long | int | integer subtraction |
| list<int> | int | list<int> | integer subtraction on each element |
| list<int> | long | list<long> | integer subtraction on each element |
| list<int> | double | list<double> | floating point subtraction on each element |
| list<long> | int | list<int> | integer subtraction on each element |
| list<long> | long | list<long> | integer subtraction on each element |
| list<double> | int | list<double> | floating point subtraction on each element |
| list<double> | double | list<double> | floating point subtraction on each element |
Multiplication: expr * expr
TODO: something pithy about multiplication.
Sample Code
public int a;
public formula b = a * 2;
public formula c = b * 3;
@construct {
a = 7;
}
Result
{"a":7,"b":14,"c":42}
Typing: TODO | int | int | int | integer subtraction | | int | double | double | floating point subtraction | | double | double | double | floating point subtraction | | double | int | double | floating point subtraction | | long | int | int | integer subtraction | | long | long | long | integer subtraction | | int | long | int | integer subtraction |
Division: expr / expr
TODO: something pithy about division.
Sample Code
public double a;
public formula b = a / 2;
public formula c = b / 10;
@construct {
a = 20;
}
Result
{"a":20.0,"b":10.0,"c":1.0}
Typing:
In Adama, division always results in a maybe<> due to a division by zero.
| left type | right type | result type |
|---|---|---|
| int | int | maybe |
| double | int | maybe |
| int | double | maybe |
| double | double | maybe |
Modulus: expr % expr
TODO: something pithy about Modulus and remainders.
Sample Code
public int a;
public formula b = a % 2;
public formula c = a % 4;
@construct {
a = 7;
}
Result
{"a":7,"b":1,"c":3}
Typing: The left and right side must be integral (i.e. int or long), and the result is integral as well. The following table summarizes the logic precisely.
| left type | right type | result type |
|---|---|---|
| int | int | int |
| long | int | int |
| int | long | int |
| long | long | long |
Less than: expr < expr
TODO: something pithy
Sample Code
public int a;
public int b;
public formula cmp1 = a < b;
public formula cmp2 = b < a;
@construct {
a = 1;
b = 2;
}
Result
{"a":1,"b":2,"cmp1":true,"cmp2":false}
Typing: The left and right must be comparable, and the resulting type is always bool. The following table outlines comparability
| left type | right type |
|---|---|
| int | int |
| int | long |
| int | double |
| long | int |
| long | long |
| long | double |
| double | int |
| double | long |
| double | double |
| string | string |
TODO: do maybes play into this?
Greater than: expr > expr
TODO: something pithy
Sample Code
public int a;
public int b;
public formula cmp1 = a > b;
public formula cmp2 = b > a;
@construct {
a = 1;
b = 2;
}
Result
{"a":1,"b":2,"cmp1":false,"cmp2":true}
Typing: This has the same typing as <
Less than or equal to: expr <= expr
TODO: something pithy
Sample Code
public int a;
public int b;
public formula cmp1 = a <= b;
public formula cmp2 = b <= a;
public formula cmp3 = a + 1 <= b;
@construct {
a = 1;
b = 2;
}
Result
{"a":1,"b":2,"cmp1":true,"cmp2":false,"cmp3":true}
Typing: This has the same typing as <
Greater than or equal to: expr >= expr
TODO: something pithy
Sample Code
public int a;
public int b;
public formula cmp1 = a >= b;
public formula cmp2 = b >= a;
public formula cmp3 = a + 1 >= b;
@construct {
a = 1;
b = 2;
}
Typing: This has the same typing as <
Result
{"a":1,"b":2,"cmp1":false,"cmp2":true,"cmp3":true}
Equality: expr == expr
TODO: something pithy
Sample Code
public int a;
public int b;
public formula eq1 = a == b;
public formula eq2 = a + 1 == b;
@construct {
a = 1;
b = 2;
}
Result
{"a":1,"b":2,"eq1":false,"eq2":true}
Typing: If a left and right type are comparable (see table under <), then the types can be tested for equality. The resulting type is a bool. Beyond comparable left and right types, the following table
Inequality: expr != expr
TODO: something pithy
Sample Code
public int a;
public int b;
public formula neq1 = a != b;
public formula neq2 = a + 1 != b;
@construct {
a = 1;
b = 2;
}
Result
{"a":1,"b":2,"neq1":true,"neq2":false}
Typing: This has the same typing as =;
Logical and: expr && expr
TODO: something pithy
Truth Table
| left | right | result |
|---|---|---|
| false | false | false |
| true | false | false |
| false | true | false |
| true | true | true |
Sample Code
public bool a;
public bool b;
public formula and = a && b;
@construct {
a = true;
b = false;
}
Result
{"a":true,"b":false,"and":false}
Typing: The left and right expressions must have a type of bool, and the resulting type is bool.
Logical or: expr || expr
TODO: something pithy
Truth Table
| left | right | result |
|---|---|---|
| false | false | false |
| true | false | true |
| false | true | true |
| true | true | true |
Sample Code
public bool a;
public bool b;
public formula or = a || b;
@construct {
a = true;
b = false;
}
Result
{"a":true,"b":false,"or":true}
Typing: The left and right expressions must have a type of bool, and the resulting type is bool.
Conditional / Ternary: expr ? expr : expr
Sample Code
public bool cond;
public formula inline = a ? 5 : 10;
@construct {
cond = true;
}
Result
{"cond":true,"inline":5}
Typing: The first expression must have a type of bool, and the second and third type must be the compatible under type rectification. The result is the rectified type. For more information about type rectification, see anonymous messages and arrays.
Operator precedence
When multiple operators operate on different operands (i.e. things), the order of operators (or operator precedence) is used to break ambiguities such that the final result is deterministic. This avoids confusion, and operators with a higher level must evaluate first.
When there are multiple operators at the same level, then an associativity rule indicates how to evaluate those operations. Typically, this is left to right, but some operators may not be associative or be right to left.
| level | operator(s) | description | associativity |
|---|---|---|---|
| 11 | expr._ident expr[expr] exprF(expr0,...,exprN) (expr) | field dereference index lookup functional application parentheses | left to right |
| 10 | expr++ expr-- | post-increment post-decrement | not associative |
| 9 | ++expr --expr | pre-increment pre-decrement | not associative |
| 8 | -expr !expr | unary negation | not associative |
| 7 | expr*expr expr/expr expr%expr | multiply divide modulo | left to right |
| 6 | expr+expr expr-expr | addition subtraction | left to right |
| 5 | expr<expr expr>expr expr<=expr expr>=expr | less than greater than less than or equal to greater than or equal to | not associative |
| 4 | expr==expr expr!=expr | equality inequality | not associative |
| 3 | expr&&expr | logical and | left to right |
| 2 | expr||expr | logical or | left to right |
| 1 | expr?expr:_expr | inline conditional / ternary | right to left |
Maybe some data, maybe not
Too many times, a value could not be found nor make sense to compute with the data at hand. The lack of a value is something to contend with, and failing to contend with it well has proven to be a billion dollar mistake. Adama uses the maybe (or optional) pattern. For example, the following defines an age which may or may not be available:
public maybe<int> age;
// how to write
#sm1 {
age = 40;
}
// how to read
#sm2 {
if (age as a) {
// so something with a if it exists
} else {
// age has no value, :(
}
}
Philosophy
The concept of maybe<> enforces better coding-discipline by leveraging the type system as a forcing function to prevent bad things from happening. Segmentation fault, NullPointerException, and index out of range exceptions are avoided entirely. Within Adama, a failure feels catastrophic as a failure signals the end of the game. This is a core motivation why Adama is a closed ecosystem (i.e. no disk or networking) such that the failures are limited to logic bugs or division by zero (and the jury is out as to whether or not division should result in a maybe<double> or not)
Using maybes
Data can always freely enter a maybe using regular assignment.
maybe<int> key;
#sm {
key = 123;
}
To safely retrieve data, the safe way is using an if ... as statement.
maybe<int> key;
#sm {
if (key as k) {
// yay, I have the value
} else {
// nay, I don't have a value
}
}
Maybe expressions
An instance of a maybe with a given type can be generated on the fly via maybe<Type>. Example:
#sm {
let key = @maybe<int>;
}
And an instance of a maybe with a given value can be generated via maybe(Expr). Example:
#sm {
let key = @maybe(123);
}
Standard control
Adama has many control and loop structures similar to C-like languages like:
And we introduce two non-traditional ones:
Diving Into Details
if
if statements are straightforward ways of controlling the flow of execution, and Adama's if behaves like most other languages.
public int x;
@construct {
if (true) {
x = 123;
} else {
x = 42;
}
}
if-as
Unlike most languages, Adama has a special extension to the if statement which is used for maybe. This allows safely extracting values out from the maybe.
int x;
@construct {
maybe<int> m_value = 123;
if (m_value as value) {
x = value;
}
}
while
while statements are a straightforward way to iterate while a condition is true.
int x = 10;
int y = 0;
while (x > 0) {
x --;
y += x;
}
do-while
do-while statements are a way to run code at least once.
int x = 10;
int y = 0;
do {
x--;
y += x;
} while (x > 0);
for
for statements are a common shorthand for while loops to initialize and step.
int y = 0;
for(int x = 10; x > 0; x--) {
y += x;
}
foreach
foreach statements are a shorthand for iterating over arrays
int y;
foreach (x in [1,2,3,4,5,6,7,8,9,10]) {
y += x;
}
Functions, procedures, and methods
Adama has three forms of colloquial functions: Functions, procedures, and methods.
Functions in Adama are pure in that they have no side effects and also are context-free. That is, the output of the function is 100% dependent on the inputs as decreed by Mathematics.
function square(int x) -> int {
return x * x;
}
On the other hand, there are procedures. A procedure can read state from outside of the function's scope. The reason for this distinction is for two reasons. First, the author has a Mathematics degree (and a chip on his shoulders) and feels the history of functions should be respected. Second, in a reactive environment, the important aspect is functions can't write state and thus cause non-determinism of a reactive read causing a write invalidating a reactive read in an infinite spiral of chaos.
int x;
procedure square_of_x() -> int {
return x * x;
}
We can also mark a procedure as readonly since the ability to read state from outside a procedure is important for building complex results in bubbles and formulas
int x;
procedure square_of_x() -> int readonly {
return x * x;
}
public formula x2 = square_of_x();
The third form is a method which is a procedure attached to a record. Methods also support the readonly annotation.
record R {
int x;
int y;
method foo() -> int readonly {
return x + y;
}
}
R z;
public formula z_foo = z.foo();
Enumerations
Enumerations in Adama are simply ways of associating integers to names.
enum Suit { Hearts:1, Spades:2, Clubs:3, Diamonds:4 }
We can refer to a single value via :: by
Suit x = Suit::Hearts;
Enumeration collections
We can build an array of all the values within an enumeration using the * symbol. For example, we can build an array of all the suit types via:
Suit[] all = Suit::*;
which is a handy. We can also build an array of all enumeration values which share a prefix. For instance, given the enum
enum Role { CoreLeft, CoreRight, Normal };
then we can refer to the collection of all values that start with Core via
Role[] core = Role::Core*;
This is a handy way to build a strict taxonomy within an enumeration.
Dispatch
Dispatching via enums is a way to split complex functions based on enumerations with an implicit switch statement.
Suppose we have an enumeration with three values:
enum X { Open, Hay, Stubble }
record Item {
X resource;
int count;
}
We can build a dispatcher function called tick which accepts an item.
dispatch X::Open tick(Item item) {
// do a thing for the Open resource
}
dispatch X::Hay tick(Item item) {
// do a thing for the Open resource
}
dispatch X::Stubble tick(Item item) {
// do a thing for the Open resource
}
The tick function then becomes a property of the X enumeration such that
Item item;
#sm {
item.resource.tick(item);
}
This creates a simple way of doing dispatch for rules per enumeration value. This statically creates an error when an enum value is created when the associated dispatcher function hasn't been written. For example, if we add the value What to the enum, then the following error is
Enum 'X' has a dispatcher 'tick' which is incomplete and lacks: What.
Reference
For more information on how to authenticate to Adama, see the Authentication section
The Javascript API Reference details the various methods found on the JavaScript client library once connected, and it's helpful to refer to JavaScript Connection and Authentication to setup a connection and how to authenticate each method call. If you are using a language other than JavaScript, then the JSON Delta Format is useful for understanding how to reconstruct JSON objects for document connections.
The Standard Library outlines the built-in functions that Adama provides developers without the need to reach out to remote services.
Standard Library
Strings
The core string type is extended with a variety of methods which can be invoked on string objects. For example,
public string x;
formula x_x = (x + x).reverse();
Methods
| Method | Description | Result type |
|---|---|---|
| length() | Returns the length of a string | int |
| split(string word) | Splits the string into a list of parts seperated by the given word | list<string> |
| split(maybe<string> word) | Splits the string into a list of parts seperated by the given word if the word is available | maybe<list<string>> |
| contains(string word) | Tests if the string contains the given word | bool |
| contains(maybe<string> word) | Tests if the string contains the given word if the word is available | maybe<bool> |
| indexOf(string word) | Returns the position of the given word | int |
| indexOf(maybe<string> word) | Returns the position of the given word if the word is available | maybe<int> |
| indexOf(string word, int offset) | Returns the position of the given word after the given offset | int |
| indexOf(maybe<string> word, int offset) | Returns the position of the given word if the word is available after the given offset | maybe<int> |
| trim() | Returns a new version of the string with whitespace removed from both the head and tail | string |
| trimLeft() | Returns a new version of the string with whitespace removed from the head/start/left-side of the string | string |
| trimRight() | Returns a new version of the string with whitespace removed from the tail/end/right-side of the string | string |
| upper() | Returns a new version of the string with all upper case characters | string |
| lower() | Returns a new version of the string with all lower case characters | string |
| mid(int start, int length) | Returns the part of the string starting at the indicated start position with the length provided. | maybe<string> |
| left(int start) | Returns the part of the string starting at the indicated start position until the end of the string | maybe<string> |
| right(int length) | Returns a string with the indicated length coming from the end of the string | maybe<string> |
| substr(int start, int end) | Returns a string that starts at the given position and ends with the given position | maybe<string> |
| startsWith(string prefix) | Returns whether or not string is prefixed by the given string | bool |
| endsWith(string prefix) | Returns whether or not string is suffixed by the given string | bool |
| multiply(int n) | Returns the concatentation of the string n times | string |
| reverse() | Returns a copy of the string with the characters reversed | string |
Functions
| Function | Description | Result type |
|---|---|---|
| String.charOf(int ch) | Returns a string with the give integer character converted into a string | string |
Math
The math library adds methods to the primitive data types of int, double, long, and complex.
For example, instead of
public int x;
formula a_x = Math.abs(x);
developers can instead use
public int x;
formula a_x = x.abs();
Also, many math functions also work on maybe types since some mathematical operators may be undefined (i.e. division by zero). Operating on maybe types, while inefficient, allows for expressive compute.
Type: int
| Method | Description | Result type |
|---|---|---|
| abs() | Returns the absolute value of the given integer. | int |
Type: long
| Method | Description | Result type |
|---|---|---|
| abs() | Returns the absolute value of the given long. | long |
Type: double, maybe<double>
| Method | Description | Result type |
|---|---|---|
| abs() | Returns the absolute value of the given double. | double |
| sqrt() | Returns the square root | complex |
| ceil() | - | double |
| floor() | - | double |
| ceil(double precision) | - | double |
| floor(double precision) | - | double |
| round() | - | double |
| round(double precision) | - | double |
| roundTo(int digits) | - | double |
Note; while many math functions are supported; they don't yet operate on maybe types; see #124
Type: complex, maybe<compex>
| Method | Description | Result type |
|---|---|---|
| conj() | Returns the complex conjugate. | complex |
| length() | Returns the length of the complex number per the pythagorean theorem. | double |
Statistics
Principals
The principal represents an agent on behalf of an authority. The default authority is 'adama' which represents Adama Developers authenticated via the Adama Platform. The principal has a unique facet where only the platform is allowed to create them as they represent identity, and this identity can be used for access control and privacy.
Part of access control is also validating that a user is from the right place which is where the standard library provides some simple functions to check a few things.
Type: principal
| Method | Description | Result type |
|---|---|---|
| isAdamaDeveloper() | Returns whether the principal is an Adama Developer | bool |
| fromAuthority(string authority) | Returns whether the principal was derived from the given authority. See authentication for how to bring your own authentication. | bool |
| isAnonymous() | Returns whether or not the principal is anonymous | bool |
| isFromDocument() | Returns whether or not the principal is from the given document | bool |
| "agent".principalOf() | Generate a principal bound to the current document | principal |
Date & Time
Adama supports four date and time related types:
- date for storing year, month, day
- time for storing hour, minute
- datetime for storing year, month, day, hour, minute, second, ms
- timespan for storing a duration
Constants
| Type | Syntax | Example | Notes |
|---|---|---|---|
| time | @time $hr:$min | @time 4:20 | Use military time for PM |
| date | @date $year/$mo/$day | @date 2023/10/31 | Must be valid |
| timespan | @timespan $count $unit | @timespan 30 min | units are sec, min, hr, day, week |
| datetime | @datetime "$iso8601" | @datetime "2023-04-24T17:57:19.802528800-05:00[America/Chicago]" | ZonedDateTime.parse |
Getting the current date/time
| Method | Description | Result type |
|---|---|---|
| Time.today() | Get the current date | date |
| Time.datetime() | Get the current date and time | datetime |
| Time.time() | Get the current time of day | time |
| Time.zone() | Get the document's time zone | string |
| Time.setZone(string zone) | Set the document's time zone | bool |
| Time.now() | Get the current time as a UNIX time stamp | long |
Time functions
| Method | Description | Result type |
|---|---|---|
| Time.make(int hr, int min) | make a time | maybe<time> |
| Time.extendWithinDay(time t, timespan s) | add the timespan to the time clamping the result at midnight | time |
| Time.cyclicAdd(time t, timespan s) | add the timespan to the time wraping around the clock | time |
| Time.toInt(time t) | convert the time to an integer | int |
| Time.overlaps(time a, time b, time c, time d) | do the temporal ranges [a,b] and [c,d] overlap | bool |
Date functions
| Method | Description | Result type |
|---|---|---|
| Date.day() | Get the day as an int | int |
| Date.month() | Get the month as an int | int |
| Date.year() | Get the year as an int | int |
| Date.make(int yr, int mo, int day) | make a date | maybe<date> |
| Date.construct(date dy, time t, double sec, string zone) | make a datetime | maybe<datetime> |
| Date.calendarViewOf(date d) | Get the surrounding month for the given date | list<date> |
| Date.weekViewOf(date d) | Get the surrounding week for the given date | list<date> |
| Date.neighborViewOf(date d, int days) | Get the neighborhood for the given date inclusively starting $days in the past to $days into the future | list<date> |
| Date.patternOf(bool m, bool tu, bool w, bool th, bool fr, bool sa, bool su) | Convert the week pattern into an integer bitmask | int |
| Date.satisfiesWeeklyPattern(date d, int pattern) | Does the given date align/match the pattern | bool |
| Date.inclusiveRange(date from, date to) | Inclusively return a list of all dates starting at $from and ending on $to | list<date> |
| Date.inclusiveRangeSatisfiesWeeklyPattern(date from, date to, int pattern) | Inclusively return a list of all dates starting at $from and ending on $to that align/match the pattern | list<date> |
| Date.dayOfWeek(date d) | Get the day of the week (1 = Monday, 7 = Sunday) as an integer | int |
| Date.dayOfWeekEnglish(date d) | Get the day of the week in english | string |
| Date.monthNameEnglish(date d) | Get the month in english | string |
| Date.offsetMonth(date d, int m) | Add/subtract the number of months from the given date | date |
| Date.offsetDay(date d, int days) | Add/subtract the number of days from the given date | date |
| Date.periodYearsFractional(date from, date to) | Get the number of years between two dates | double |
| Date.periodMonths(date from, date to) | Get the number of months between two dates | int |
| Date.between(datetime from, datetime to) | Get the time between two datetimes | timespan |
| Date.format(date, string format, string lang) | Format the date for the given format in the given language (time component is midnight at 0 seconds using UTC time zone) | maybe<string> |
| Date.format(date, string format) | Format the date for the given format using english (time component is midnight at 0 seconds using UTC time zone) | maybe<string> |
| Date.min(date d1, date d2) | pick the minimum date | date |
| Date.max(date d1, date d2) | pick the maximum date | date |
| Date.overlaps(date a, date b, date c, date d) | do the date ranges [a,b] and [c,d] overlap | bool |
Timespan functions
| Method | Description | Result type |
|---|---|---|
| TimeSpan.add(timespan a, timespan b) | Add the two timespans together, also the + operator works for this | timespan |
| TimeSpan.multiply(timespan a, double v) | Multiply the timespan by the given double, also the + operator works for this | timespan |
| TimeSpan.seconds(timespan a) or a.seconds() | Return the timespan as seconds | double |
| TimeSpan.minutes(timespan a) or a.seconds() | Return the timespan as minutes | double |
| TimeSpan.hours(timespan a) or a.seconds() | Return the timespan as hours | double |
DateTime functions
| Method | Description | Result type |
|---|---|---|
| Date.future(datetime d, timespan t) | Get the future datetime by the given timespan | datetime |
| Date.past(datetime d, timespan t) | Get the past datetime by the given timespan | datetime |
| Date.date(datetime d) | Convert the datetime to a date, throwing away the time | date |
| Date.time(datetime d) | Convert the datetime to a time, throwing away the date | time |
| Date.adjustTimeZone(datetime d, String tz) | Adjust the timezone if the timezone exists | maybe<datetime> |
| Date.format(datetime, string format, string lang) | Format the datetime for the given format in the given language | maybe<string> |
| Date.format(datetime, string format) | Format the datetime for the given format using english | maybe<string> |
| Date.withYear(datetime d, int year) | Replace the year | maybe<datetime> |
| Date.withMonth(datetime d, int month) | Replace the month | maybe<datetime> |
| Date.withDayOfMonth(datetime d, int day) | Replace the day of the month | maybe<datetime> |
| Date.withHour(datetime d, int hour) | Replace the hour | maybe<datetime> |
| Date.withMinute(datetime d, int minute) | Replace the minute the month | maybe<datetime> |
| Date.withTime(datetime d, time t) | Replace both the hour and minute and zero out seconds and milliseconds | maybe<datetime> |
| Date.truncateDay(datetime) | Zero out the day, hour, minute, seconds, milliseconds | datetime |
| Date.truncateHour(datetime) | Zero out the hour, minute, seconds, milliseconds | datetime |
| Date.truncateMinute(datetime) | Zero out the minute, seconds, milliseconds | datetime |
| Date.truncateSeconds(datetime) | Zero out the seconds, milliseconds | datetime |
| Date.truncateMilliseconds(datetime) | Zero out the milliseconds | datetime |
| Date.min(datetime d1, datetime d2) | pick the minimum date | datetime |
| Date.max(datetime d1, datetime d2) | pick the maximum date | datetime |
| Date.overlaps(datetime a, datetime b, datetime c, datetime d) | do the datetime ranges [a,b] and [c,d] overlap | bool |
Authentication
Many parameters within the API have an 'identity' field. For securing your application or game, this field is a JSON Web Token that is signed by either Adama or you. There is a weaker form of security using a special string prefixed by 'anonymous'; this allows developers to open up documents to the internet. Below is a table of the various forms of authentication supported by Adama.
| method | description |
|---|---|
| anonymous | an identity token of 'anonymous:$name' results in a principal of ($name, 'anonymous`). |
| adama | The platform has a global authentication mechanism for all adama developers. The principal is ($adamaUserId, 'adama'). The identity token is always secured by a ephemeral private key. |
| authority | In the spirt of allowing developers top bring their own authentication, an authority is a named and uploaded keystore with public keys. This allows you to secure your private key however you want. Click here for more information |
| document | A document is able to grant a web visitor a special principal that is tied to the document; this token is generated via a web response. Click here for more information |
Authorities
An authority is a named keystore where public keys are stored in Adama.
Create an authority
You can create a keystore via the CLI tool.
java -jar ~/adama.jar authority create
This will return the name for your new keystore. For the remainder of this document, we will use 3LZXGH9PUOEH25GZYQ17IL7W713XLJ as the name.
Create the keystore
The tooling can create a keystore that contains an initial public key. The below command will create the keystore for the prior created authority.
java -jar adama.jar authority create-local \
--authority 3LZXGH9PUOEH25GZYQ17IL7W713XLJ \
--keystore my.keystore.json \
--private first.private.key.json
This will create two files within your working directory:
- my.keystore.json is a collection of public keys used by Adama to validate a private
- first.private.key.json is a private key used by your software to sign your users' id. This requires safe-keeping!
This keystore and private key were created entirely locally on your machine (for exceptional security), and now you upload only the keystore with:
Upload the keystore
With a keystore full of public keys, we can upload the keystore to Adama.
java -jar adama.jar authority set \
--authority 3LZXGH9PUOEH25GZYQ17IL7W713XLJ \
--keystore my.keystore.json
This will allow the users signed by that private key into Adama.
Sign an example identity
Consuming the private key will require some crypto libraries in some infrastructure that you manage, but we can get started by using the Adama tooling to create an identity today!
java -jar adama.jar authority sign \
--key first.private.key.json \
--agent user001
This will create a principal with agent user001 and authority of 3LZXGH9PUOEH25GZYQ17IL7W713XLJ
Adding another public key
Similar to create-local which initializes a keystore, we can generate and append a new public key and side-channel write the private key.
java -jar adama.jar authority append-local \
--authority 3LZXGH9PUOEH25GZYQ17IL7W713XLJ \
--keystore my.keystore.json
--private second.private.key.json
Document
Documents can create a signed identity via a document PUT by returning a object with a sign field like so:
message WebRegister {
string email;
string password;
}
@web put /register (WebRegister register) {
// .. validate the registration and insert into a table
return { sign: register.email; }
}
We leverage web put because we most likely don't have a connection to the document as we are trying to get credentials to connect to the document. The web put allows us to register users, and passwords must be hashed prior to being sent to the server. Since a web put will write a message to the change log, we shouldn't use it for authenticating a user. Instead, there is an @authorization handler that accepts a message and has a complex handshake between the document and platform which you can learn more about here.
message AuthPipeInvoke {
string email;
}
@authorization (AuthPipeInvoke api) {
// find the person
if ((iterate _people where email == api.email)[0] as person) {
// return the agent and the hash to check
return {
agent: "" + person.id,
hash: person.password_hash,
};
}
abort;
}
Whatever these functions result is considered the agent (or subject) of the principal while the authority is the document (doc/$space/key).
Document based Auth Workflow
The @authorization handler is fairly complex since hashing and security is handled by the platform rather than the document. At core, the @authorization handler is a special channel that returns a complex dynamic object to configure the platform. In the barest form, implementation starts by defining a message to interpret and the response then provides the associated agent along with a hash to check. The platform will check the hash and all important security details are handled by the platform.
message AuthPipeInvoke {
string email;
}
@authorization (AuthPipeInvoke api) {
// find the person
if ((iterate _people where email == api.email)[0] as person) {
// return the agent and the hash to check
return {
agent: "" + person.id,
hash: person.password_hash,
};
}
abort;
}
The methods to invoke this handler are either document/authorization or document/authorization-domain. These both accept a JSON object under the field message. This message is converted to the associated message structure (in this case: AuthPipeInvoke).
The code then either either returns an structure containing the fields hash and agent OR aborts. If the code aborts, then the authorization fails. If the code returns an agent with hash, then the hash is checked against the provided password (see password handling) for clarity). If the provided password satisfies the hash, then the authorization allowed and the identity is created using the agent field under the authority of 'doc/$space/$key'.
read-only behavior
The @authorization handler is read-only and unable to mutate the document. We can turn around immediately to perform a write via the channel and success fields. The channel field allows a successful mutation to be executed with the associated message in the success field.
This trampoline allows (1) password resets, (2) one time password cleanup, (3) metrics. Below is sample code of using both the channel and success fields with one time passwords and resets.
message AuthPipeInvoke {
bool otp;
int otp_id;
string email;
maybe<string> new_password;
}
record OneTimePassword {
private int id;
private int user_id;
private string hash;
}
table<OneTimePassword> _otps;
@authorization (AuthPipeInvoke api) {
if (api.otp) {
if ((iterate _otps where id == api.otp_id)[0] as otp) {
if (api.new_password as new_password) {
return {
agent: "" + otp.user_id,
hash: otp.hash,
channel: "set_password_from_authpipe_otp",
success: {new_password: new_password}
};
} else {
return {
agent: "" + otp.user_id,
hash: otp.hash,
channel: "post_authorization_clear_otp",
success: {}
};
}
}
} else {
if ((iterate _people where email == api.email)[0] as user) {
if (api.new_password as new_password) {
// set password at login
return {
agent: "" + user.id,
hash: user.password_hash,
channel: "set_password_from_authpipe",
success: {new_password: new_password}
};
} else {
// just validate
return {
agent: "" + user.id,
hash: user.password_hash,
};
}
}
}
abort;
}
message AuthPipeSetPassword {
string new_password;
}
channel set_password_from_authpipe(AuthPipeSetPassword apsp) {
if ((iterate _people where who == @who)[0] as user) {
user.password_hash = apsp.new_password;
}
}
channel set_password_from_authpipe_otp(AuthPipeSetPassword apsp) {
if ((iterate _people where who == @who)[0] as user) {
user.password_hash = apsp.new_password;
(iterate _otps where user_id == user.id).delete();
}
}
channel post_authorization_clear_otp(Empty e) {
if ((iterate _users where who == @who)[0] as user) {
(iterate _otps where user_id == user.id).delete();
}
}
Deployment Plan
Since the configuration behind a space is fundamentally code, it is valuable to change it slowly for a variety reasons. For instance, it is wise to gate a deployment to a small population to test and gather metrics. It may also be wise to go slow to avoid an expensive bill.
The deployment plan has three root fields:
- versions providing a mapping of id to versions.
- default is an id to use when the plan fails to pick an id
- plan is a list of rules to pick a version id
The versions mapping and the default id.
The versions object is a mapping of ids to versions of the script to use. The range of the mapping is either a string or an object. For example,
{
"versions": {
"x": "public int x;"
},
"default": "x",
"plan": []
}
is a minimal deployment plan with a single version containing a single source script. The "x" field within "versions" is a string representing adama code to compile, and it is the default version to use. However, there are more features to building an Adama script, and the "x" field may also be an object.
{
"versions": {
"x": {
"main": "public int x; @include xyz;",
"includes": {
"xyz" : "public int y;"
},
"rxhtml": "<forest>...</forest>"
}
},
"default": "x",
"plan": []
}
Now the "x" field has an object with a main which is the primary Adama script which may include other scripts which are stored within the "includes" object. Furthermore, RxHTML can be included to augment the web capabilities of Adama.
Safety happens with planning
Since change is a source of engineering pain, the plan field within a deployment plan is a simple rule engine. Simply, it's a list of objects where each object represents the parameters to a decision to route to a specific version.
For example,
{
"versions": {
"x": "public int x;",
"y": "public int x; public int y;"
},
"default": "x",
"plan": [
{
"version": "y",
"keys": ["1", "2"],
"percent": 1,
"prefix": "new",
"seed": "xyz"
}
]
}
The version field within a plan's object is simply a key within the versions object in the deployment plan. The optional keys field is a hard-coded list of which keys must go to the indicated version. If the percent is 100 or more and the key shares the key shares the prefix, then that key will go to the indicated version. If the percent is less than 100 and the key shares the prefix, then the given key is hashed with the seed as a value between 0 and 100. If the value is less than percent, then the key will used the indicated version. The first rule to pick a version wins, and if no rule matches then the default is used.
The above prose represents the below algorithm
public String pickVersion(String key) {
for (Stage stage : stages) {
if (stage.keys != null) {
if (stage.keys.contains(key)) {
return stage.version;
}
}
if (key.startsWith(stage.prefix)) {
if (stage.percent >= 100) {
return stage.version;
}
if (hash(stage.seed, key) <= stage.percent) {
return stage.version;
}
}
}
return defaultVersion;
}
By fully utilizing the deployment plan, changes can be made exceptionally safe.
API Reference
Methods: InitSetupAccount, InitConvertGoogleUser, InitCompleteAccount, Deinit, AccountSetPassword, AccountGetPaymentPlan, AccountLogin, AccountSocialLogin, Probe, Stats, IdentityHash, IdentityStash, AuthorityCreate, AuthoritySet, AuthorityGet, AuthorityList, AuthorityDestroy, SpaceCreate, SpaceGenerateKey, SpaceGet, SpaceSet, SpaceRedeployKick, SpaceSetRxhtml, SpaceGetRxhtml, SpaceSetPolicy, PolicyGenerateDefault, SpaceGetPolicy, SpaceMetrics, SpaceDelete, SpaceSetRole, SpaceListDevelopers, SpaceReflect, SpaceList, PushRegister, DomainMap, DomainClaimApex, DomainRedirect, DomainConfigure, DomainReflect, DomainMapDocument, DomainList, DomainListBySpace, DomainGetVapidPublicKey, DomainUnmap, DomainGet, DocumentDownloadArchive, DocumentListBackups, DocumentForceBackup, DocumentDownloadBackup, DocumentListPushTokens, DocumentAuthorization, DocumentAuthorizationDomain, DocumentAuthorize, DocumentAuthorizeDomain, DocumentAuthorizeWithReset, DocumentAuthorizeDomainWithReset, DocumentCreate, DocumentDelete, DocumentList, MessageDirectSend, MessageDirectSendOnce, ConnectionCreate, ConnectionCreateViaDomain, ConnectionSend, ConnectionPassword, ConnectionSendOnce, ConnectionCanAttach, ConnectionAttach, ConnectionUpdate, ConnectionEnd, DocumentsCreateDedupe, DocumentsHashPassword, BillingConnectionCreate, FeatureSummarizeUrl, ReplicationCreate, ReplicationEnd, AttachmentStart, AttachmentStartByDomain, AttachmentAppend, AttachmentFinish
Method: InitSetupAccount (JS)
wire method:init/setup-account
This initiates developer machine via email verification.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| yes | String | The email of an Adama developer. |
JavaScript SDK Template
connection.InitSetupAccount(email, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: InitConvertGoogleUser (JS)
wire method:init/convert-google-user
The converts and validates a google token into an Adama token.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| access-token | yes | String | A token from a third party authorization service. |
JavaScript SDK Template
connection.InitConvertGoogleUser(access-token, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: InitCompleteAccount (JS)
wire method:init/complete-account
This establishes a developer machine via email verification.
Copy the code from the email into this request.
The server will generate a key-pair and send the secret to the client to stash within their config, and the public key will be stored to validate future requests made by this developer machine.
A public key will be held onto for 30 days.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| yes | String | The email of an Adama developer. | |
| revoke | no | Boolean | A flag to indicate wiping out previously granted tokens. |
| code | yes | String | A randomly (secure) generated code to validate a user via 2FA auth (via email). |
JavaScript SDK Template
connection.InitCompleteAccount(email, revoke, code, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: Deinit (JS)
wire method:deinit
This will destroy a developer account. We require all spaces to be deleted along with all authorities.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
JavaScript SDK Template
connection.Deinit(identity, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: AccountSetPassword (JS)
wire method:account/set-password
Set the password for an Adama developer.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| password | yes | String | The password for your account or a document |
JavaScript SDK Template
connection.AccountSetPassword(identity, password, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: AccountGetPaymentPlan (JS)
wire method:account/get-payment-plan
Get the payment plan information for the developer.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
JavaScript SDK Template
connection.AccountGetPaymentPlan(identity, {
success: function(response) {
// response.paymentPlan
// response.publishableKey
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| payment-plan | String | Payment plan name. The current default is "none" which can be upgraded to "public". |
| publishable-key | String | The public key from the merchant provider. |
Method: AccountLogin (JS)
wire method:account/login
Sign an Adama developer in with an email and password pair.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| yes | String | The email of an Adama developer. | |
| password | yes | String | The password for your account or a document |
JavaScript SDK Template
connection.AccountLogin(email, password, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: AccountSocialLogin (JS)
wire method:account/social-login
Sign an Adama user in with an email and password pair.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| yes | String | The email of an Adama developer. | |
| password | yes | String | The password for your account or a document |
| scopes | yes | String | The scopes of a social login. For example, * is all scopes which is applicable for a Adama controlled property while another scope is $space1/*,$space2/$key1 |
JavaScript SDK Template
connection.AccountSocialLogin(email, password, scopes, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: Probe (JS)
wire method:probe
This is useful to validate an identity without executing anything.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
JavaScript SDK Template
connection.Probe(identity, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: Stats (JS)
wire method:stats
Get stats for the current connection This method has no parameters.
JavaScript SDK Template
connection.Stats({
next: function(payload) {
// payload.statKey
// payload.statValue
// payload.statType
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| stat-key | String | A key for the stats |
| stat-value | String | The value for a stat |
| stat-type | String | The type of the stat. |
Method: IdentityHash (JS)
wire method:identity/hash
Validate an identity and convert to a public and opaque base64 crypto hash.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
JavaScript SDK Template
connection.IdentityHash(identity, {
success: function(response) {
// response.identityHash
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity-hash | String | A hash of an identity |
Method: IdentityStash (JS)
wire method:identity/stash
Stash an identity locally in the connection as if it was a cookie
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| name | yes | String | An identifier to name the resource. |
JavaScript SDK Template
connection.IdentityStash(identity, name, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: AuthorityCreate
wire method:authority/create
Create an authority. See Authentication for more details.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
Request response fields
| name | type | documentation |
|---|---|---|
| authority | String | An authority is collection of third party users authenticated via a public keystore. |
Method: AuthoritySet
wire method:authority/set
Set the public keystore for the authority.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| authority | yes | String | An authority is collection of users held together via a key store. |
| key-store | yes | ObjectNode | A collection of public keys used to validate an identity within an authority. |
This method simply returns void.
Method: AuthorityGet
wire method:authority/get
Get the public keystore for the authority.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| authority | yes | String | An authority is collection of users held together via a key store. |
Request response fields
| name | type | documentation |
|---|---|---|
| keystore | ObjectNode | A bunch of public keys to validate tokens for an authority. |
Method: AuthorityList
wire method:authority/list
List authorities for the given developer.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| authority | String | An authority is collection of third party users authenticated via a public keystore. |
Method: AuthorityDestroy
wire method:authority/destroy
Destroy an authority.
This is exceptionally dangerous as it will break authentication for any users that have tokens based on that authority.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| authority | yes | String | An authority is collection of users held together via a key store. |
This method simply returns void.
Method: SpaceCreate (JS)
wire method:space/create
Create a space.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| template | no | String | When creating a space, the template is a known special identifier for how to bootstrap the defaults. Examples: none (default when template parameter not present). |
JavaScript SDK Template
connection.SpaceCreate(identity, space, template, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: SpaceGenerateKey
wire method:space/generate-key
Generate a secret key for a space.
First party and third party services require secrets such as api tokens or credentials.
These credentials must be encrypted within the Adama document using a public-private key, and the secret is derived via a key exchange. Here, the server will generate a public/private key pair and store the private key securely and give the developer a public key. The developer then generates a public/private key, encrypts the token with the private key, throws away the private key, and then embeds the key id, the developer's public key, and the encrypted credential within the adama source code.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
Request response fields
| name | type | documentation |
|---|---|---|
| key-id | Integer | Unique id of the private-key used for a secret. |
| public-key | String | A public key to decrypt a secret with key arrangement. |
Method: SpaceGet
wire method:space/get
Get the deployment plan for a space.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
Request response fields
| name | type | documentation |
|---|---|---|
| plan | ObjectNode | A plan is a predictable mapping of keys to implementations. The core reason for having multiple concurrent implementations is to have a smooth and orderly deployment. See deployment plans for more information. |
Method: SpaceSet
wire method:space/set
Set the deployment plan for a space.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| plan | yes | ObjectNode | This 'plan' parameter contains multiple Adama scripts all gated on various rules. These rules allow for a migration to happen slowly on your schedule. Note: this value will validated such that the scripts are valid, compile, and will not have any major regressions during role out. |
This method simply returns void.
Method: SpaceRedeployKick
wire method:space/redeploy-kick
A diagnostic call to optimistically to refresh a space's deployment
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
This method simply returns void.
Method: SpaceSetRxhtml
wire method:space/set-rxhtml
Set the RxHTML forest for the space when viewed via a domain name.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| rxhtml | yes | String | A RxHTML forest which provides simplified web hosting. |
This method simply returns void.
Method: SpaceGetRxhtml
wire method:space/get-rxhtml
Get the RxHTML forest for the space when viewed via a domain name.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
Request response fields
| name | type | documentation |
|---|---|---|
| rxhtml | String | The RxHTML forest for a space. |
Method: SpaceSetPolicy
wire method:space/set-policy
Set the access control policy for a space
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| access-policy | yes | ObjectNode | A policy to control who can do what against a space. |
This method simply returns void.
Method: PolicyGenerateDefault
wire method:policy/generate-default
Generate a default policy template for inspection and use
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
Request response fields
| name | type | documentation |
|---|---|---|
| access-policy | ObjectNode | A policy to control who can do what against a space. |
Method: SpaceGetPolicy
wire method:space/get-policy
Returns the policy for a specific space
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
Request response fields
| name | type | documentation |
|---|---|---|
| access-policy | ObjectNode | A policy to control who can do what against a space. |
Method: SpaceMetrics
wire method:space/metrics
For regional proxies to emit metrics for a document
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| prefix | no | String | A prefix of a key used to filter results in a listing or computation |
| metric-query | no | ObjectNode | A metric query to override the behavior on aggregation for specific fields |
Request response fields
| name | type | documentation |
|---|---|---|
| metrics | ObjectNode | A metrics object is a bunch of counters/event-tally |
| count | Integer | The number of items considered/available. |
Method: SpaceDelete (JS)
wire method:space/delete
Delete a space.
This requires no documents to be within the space, and this removes the space from use until garbage collection ensures no documents were created for that space after deletion. A space may be reserved for 90 minutes until the system is absolutely sure no documents will leak.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
JavaScript SDK Template
connection.SpaceDelete(identity, space, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: SpaceSetRole
wire method:space/set-role
Set the role of an Adama developer for a particular space.
Spaces can be shared among Adama developers.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| yes | String | The email of an Adama developer. | |
| role | yes | String | The role of a user may determine their capabilities to perform actions. |
This method simply returns void.
Method: SpaceListDevelopers
wire method:space/list-developers
List the developers with access to this space
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| String | A developer email | |
| role | String | Each developer has a role to a document. |
Method: SpaceReflect (JS)
wire method:space/reflect
Get a schema for the space.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
JavaScript SDK Template
connection.SpaceReflect(identity, space, key, {
success: function(response) {
// response.reflection
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| reflection | ObjectNode | Schema of a document. |
Method: SpaceList (JS)
wire method:space/list
List the spaces available to the user.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| marker | no | String | A key to skip ahead a listing. When iterating, values will be returned that are after marker. To paginate an entire list, pick the last key or name returned and use it as the next marker. |
| limit | no | Integer | Maximum number of items to return during a streaming list. |
JavaScript SDK Template
connection.SpaceList(identity, marker, limit, {
next: function(payload) {
// payload.space
// payload.role
// payload.created
// payload.enabled
// payload.storageBytes
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| space | String | A space which is a collection of documents with a common Adama schema. |
| role | String | Each developer has a role to a document. |
| created | String | When the item was created. |
| enabled | Boolean | Is the item in question enabled. |
| storage-bytes | Long | The storage used. |
Method: PushRegister (JS)
wire method:push/register
Register a device for push notifications
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
| subscription | yes | ObjectNode | A push subscription which is an abstract package for push notifications |
| device-info | yes | ObjectNode | Information about a device |
JavaScript SDK Template
connection.PushRegister(identity, domain, subscription, device-info, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: DomainMap
wire method:domain/map
Map a domain to a space.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| certificate | no | String | A TLS/SSL Certificate encoded as json. |
This method simply returns void.
Method: DomainClaimApex
wire method:domain/claim-apex
Claim an apex domain to be used only by your account
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
Request response fields
| name | type | documentation |
|---|---|---|
| claimed | Boolean | Has the apex domain been claimed and validated? |
| txt-token | String | The TXT field to introduce under the domain to prove ownership |
Method: DomainRedirect
wire method:domain/redirect
Map a domain to another domain
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
| destination-domain | yes | String | A domain name to forward to |
This method simply returns void.
Method: DomainConfigure
wire method:domain/configure
Configure a domain with internal guts that are considered secret.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
| product-config | yes | ObjectNode | Product config for various native app and integrated features. |
This method simply returns void.
Method: DomainReflect (JS)
wire method:domain/reflect
Get a schema for the domain
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
JavaScript SDK Template
connection.DomainReflect(identity, domain, {
success: function(response) {
// response.reflection
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| reflection | ObjectNode | Schema of a document. |
Method: DomainMapDocument
wire method:domain/map-document
Map a domain to a space.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| route | no | Boolean | A domain can route to the space or to a document's handler |
| certificate | no | String | A TLS/SSL Certificate encoded as json. |
This method simply returns void.
Method: DomainList
wire method:domain/list
List the domains for the given developer
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| domain | String | A domain name. |
| space | String | A space which is a collection of documents with a common Adama schema. |
| key | String | The key. |
| route | Boolean | Does the domain route GET to the document or the space. |
| forward | String | Does the domain have a forwarding address |
| configured | Boolean | Is the domain configured? |
| apex_managed | Boolean | Is the domain managed by an apex domain? |
Method: DomainListBySpace
wire method:domain/list-by-space
List the domains for the given developer
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| domain | String | A domain name. |
| space | String | A space which is a collection of documents with a common Adama schema. |
| key | String | The key. |
| route | Boolean | Does the domain route GET to the document or the space. |
| forward | String | Does the domain have a forwarding address |
| configured | Boolean | Is the domain configured? |
| apex_managed | Boolean | Is the domain managed by an apex domain? |
Method: DomainGetVapidPublicKey (JS)
wire method:domain/get-vapid-public-key
Get the public key for the VAPID
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
JavaScript SDK Template
connection.DomainGetVapidPublicKey(identity, domain, {
success: function(response) {
// response.publicKey
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| public-key | String | A public key to decrypt a secret with key arrangement. |
Method: DomainUnmap
wire method:domain/unmap
Unmap a domain
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
This method simply returns void.
Method: DomainGet
wire method:domain/get
Get the domain mapping
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
Request response fields
| name | type | documentation |
|---|---|---|
| space | String | A space which is a collection of documents with a common Adama schema. |
Method: DocumentDownloadArchive
wire method:document/download-archive
Download a complete archive
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| base64-bytes | String | Bytes encoded in base64. |
| chunk-md5 | String | MD5 of a chunk |
Method: DocumentListBackups
wire method:document/list-backups
List snapshots for a document
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| backup-id | String | The id of a backup (encoded) |
| date | String | The date of a backup |
| seq | Integer | The sequencer for the item. |
Method: DocumentForceBackup
wire method:document/force-backup
Force a backup to occur
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
Request response fields
| name | type | documentation |
|---|---|---|
| backup-id | String | The id of a backup (encoded) |
Method: DocumentDownloadBackup
wire method:document/download-backup
Download a specific snapshot
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| backup-id | yes | String | The reason a backup was made |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| base64-bytes | String | Bytes encoded in base64. |
| chunk-md5 | String | MD5 of a chunk |
Method: DocumentListPushTokens
wire method:document/list-push-tokens
List push tokens for a given agent within a document
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| domain | yes | String | A domain name. |
| agent | yes | String | Agent within a principal |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| id | Long | a long id |
| subscription-info | ObjectNode | Subscription information for a push subscriber. |
| device-info | ObjectNode | Device information for a push subscriber. |
Method: DocumentAuthorization (JS)
wire method:document/authorization
Send an authorization request to the document
Parameters
| name | required | type | documentation |
|---|---|---|---|
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| message | yes | JsonNode | The object sent to a document which will be the parameter for a channel handler. |
JavaScript SDK Template
connection.DocumentAuthorization(space, key, message, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: DocumentAuthorizationDomain (JS)
wire method:document/authorization-domain
Send an authorization request to a document via a domain
Parameters
| name | required | type | documentation |
|---|---|---|---|
| domain | yes | String | A domain name. |
| message | yes | JsonNode | The object sent to a document which will be the parameter for a channel handler. |
JavaScript SDK Template
connection.DocumentAuthorizationDomain(domain, message, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: DocumentAuthorize (JS)
wire method:document/authorize
Authorize a username and password against a document.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| username | yes | String | The username for a document authorization |
| password | yes | String | The password for your account or a document |
JavaScript SDK Template
connection.DocumentAuthorize(space, key, username, password, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: DocumentAuthorizeDomain (JS)
wire method:document/authorize-domain
Authorize a username and password against a document via a domain
Parameters
| name | required | type | documentation |
|---|---|---|---|
| domain | yes | String | A domain name. |
| username | yes | String | The username for a document authorization |
| password | yes | String | The password for your account or a document |
JavaScript SDK Template
connection.DocumentAuthorizeDomain(domain, username, password, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: DocumentAuthorizeWithReset (JS)
wire method:document/authorize-with-reset
Authorize a username and password against a document, and set a new password
Parameters
| name | required | type | documentation |
|---|---|---|---|
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| username | yes | String | The username for a document authorization |
| password | yes | String | The password for your account or a document |
| new_password | yes | String | The new password for your account or document |
JavaScript SDK Template
connection.DocumentAuthorizeWithReset(space, key, username, password, new_password, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: DocumentAuthorizeDomainWithReset (JS)
wire method:document/authorize-domain-with-reset
Authorize a username and password against a document, and set a new password
Parameters
| name | required | type | documentation |
|---|---|---|---|
| domain | yes | String | A domain name. |
| username | yes | String | The username for a document authorization |
| password | yes | String | The password for your account or a document |
| new_password | yes | String | The new password for your account or document |
JavaScript SDK Template
connection.DocumentAuthorizeDomainWithReset(domain, username, password, new_password, {
success: function(response) {
// response.identity
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| identity | String | A private token used to authenticate to Adama. |
Method: DocumentCreate (JS)
wire method:document/create
Create a document.
The entropy allows the randomization of the document to be fixed at construction time.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| entropy | no | String | Each document has a random number generator. When 'entropy' is present, it will seed the random number generate such that the randomness is now deterministic at the start. |
| arg | yes | ObjectNode | The parameter for a document's @construct event. |
JavaScript SDK Template
connection.DocumentCreate(identity, space, key, entropy, arg, {
success: function() {
},
failure: function(reason) {
}
});
This method simply returns void.
Method: DocumentDelete
wire method:document/delete
Delete a document (invokes the @delete document policy).
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
This method simply returns void.
Method: DocumentList (JS)
wire method:document/list
List documents within a space which are after the given marker.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| marker | no | String | A key to skip ahead a listing. When iterating, values will be returned that are after marker. To paginate an entire list, pick the last key or name returned and use it as the next marker. |
| limit | no | Integer | Maximum number of items to return during a streaming list. |
JavaScript SDK Template
connection.DocumentList(identity, space, marker, limit, {
next: function(payload) {
// payload.key
// payload.created
// payload.updated
// payload.seq
// payload.lastBackup
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| key | String | The key. |
| created | String | When the item was created. |
| updated | String | When the item was last updated. |
| seq | Integer | The sequencer for the item. |
| last-backup | String | The time of the last internal backup. |
Method: MessageDirectSend (JS)
wire method:message/direct-send
Send a message to a document without a connection
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| channel | yes | String | Each document has multiple channels available to send messages too. |
| message | yes | JsonNode | The object sent to a document which will be the parameter for a channel handler. |
JavaScript SDK Template
connection.MessageDirectSend(identity, space, key, channel, message, {
success: function(response) {
// response.seq
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| seq | Integer | The sequencer for the item. |
Method: MessageDirectSendOnce (JS)
wire method:message/direct-send-once
Send a message to a document without a connection
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| dedupe | no | String | A key used to dedupe request such that at-most once processing is used. |
| channel | yes | String | Each document has multiple channels available to send messages too. |
| message | yes | JsonNode | The object sent to a document which will be the parameter for a channel handler. |
JavaScript SDK Template
connection.MessageDirectSendOnce(identity, space, key, dedupe, channel, message, {
success: function(response) {
// response.seq
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| seq | Integer | The sequencer for the item. |
Method: ConnectionCreate (JS)
wire method:connection/create
Create a connection to a document.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| viewer-state | no | ObjectNode | A connection to a document has a side-channel for passing information about the client's view into the evaluation of bubbles. This allows for developers to implement real-time queries and pagination. |
JavaScript SDK Template
connection.ConnectionCreate(identity, space, key, viewer-state, {
next: function(payload) {
// payload.delta
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| delta | ObjectNode | A json delta representing a change of data. See the delta format for more information. |
Method: ConnectionCreateViaDomain (JS)
wire method:connection/create-via-domain
Create a connection to a document via a domain name.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
| viewer-state | no | ObjectNode | A connection to a document has a side-channel for passing information about the client's view into the evaluation of bubbles. This allows for developers to implement real-time queries and pagination. |
JavaScript SDK Template
connection.ConnectionCreateViaDomain(identity, domain, viewer-state, {
next: function(payload) {
// payload.delta
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| delta | ObjectNode | A json delta representing a change of data. See the delta format for more information. |
Method: ConnectionSend
wire method:connection/send
Send a message to the document on the given channel.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| channel | yes | String | Each document has multiple channels available to send messages too. |
| message | yes | JsonNode | The object sent to a document which will be the parameter for a channel handler. |
Request response fields
| name | type | documentation |
|---|---|---|
| seq | Integer | The sequencer for the item. |
Method: ConnectionPassword
wire method:connection/password
Set the viewer's password to the document; requires their old password.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| username | yes | String | The username for a document authorization |
| password | yes | String | The password for your account or a document |
| new_password | yes | String | The new password for your account or document |
This method simply returns void.
Method: ConnectionSendOnce
wire method:connection/send-once
Send a message to the document on the given channel with a dedupe key such that sending happens at most once.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| channel | yes | String | Each document has multiple channels available to send messages too. |
| dedupe | no | String | A key used to dedupe request such that at-most once processing is used. |
| message | yes | JsonNode | The object sent to a document which will be the parameter for a channel handler. |
Request response fields
| name | type | documentation |
|---|---|---|
| seq | Integer | The sequencer for the item. |
Method: ConnectionCanAttach
wire method:connection/can-attach
Ask whether the connection can have attachments attached.
Parameters
| name | required | type | documentation |
|---|
Request response fields
| name | type | documentation |
|---|---|---|
| yes | Boolean | The result of a boolean question. |
Method: ConnectionAttach
wire method:connection/attach
This is an internal API used only by Adama for multi-region support.
Start an upload for the given document with the given filename and content type.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| asset-id | yes | String | The id of an asset. |
| filename | yes | String | A filename is a nice description of the asset being uploaded. |
| content-type | yes | String | The MIME type like text/json or video/mp4. |
| size | yes | Long | The size of an attachment. |
| digest-md5 | yes | String | The MD5 of an attachment. |
| digest-sha384 | yes | String | The SHA384 of an attachment. |
Request response fields
| name | type | documentation |
|---|---|---|
| seq | Integer | The sequencer for the item. |
Method: ConnectionUpdate
wire method:connection/update
Update the viewer state of the document.
The viewer state is accessible to bubbles to provide view restriction and filtering. For example, the viewer state is how a document can provide real-time search or pagination.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| viewer-state | no | ObjectNode | A connection to a document has a side-channel for passing information about the client's view into the evaluation of bubbles. This allows for developers to implement real-time queries and pagination. |
This method simply returns void.
Method: ConnectionEnd
wire method:connection/end
Disconnect from the document.
Parameters
| name | required | type | documentation |
|---|
This method simply returns void.
Method: DocumentsCreateDedupe (JS)
wire method:documents/create-dedupe
Ask the server to create a dedupe token This method has no parameters.
JavaScript SDK Template
connection.DocumentsCreateDedupe({
success: function(response) {
// response.dedupe
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| dedupe | String | A UUID dedupe string |
Method: DocumentsHashPassword (JS)
wire method:documents/hash-password
For documents that want to hold passwords, then these passwords should not be stored plaintext.
This method provides the client the ability to hash a password for plain text transmission.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| password | yes | String | The password for your account or a document |
JavaScript SDK Template
connection.DocumentsHashPassword(password, {
success: function(response) {
// response.passwordHash
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| password-hash | String | The hash of a password. |
Method: BillingConnectionCreate (JS)
wire method:billing-connection/create
Create a connection to the billing document of the given identity.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
JavaScript SDK Template
connection.BillingConnectionCreate(identity, {
next: function(payload) {
// payload.delta
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| delta | ObjectNode | A json delta representing a change of data. See the delta format for more information. |
Method: FeatureSummarizeUrl (JS)
wire method:feature/summarize-url
Summarize a URL by parsing it's meta-data.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| url | yes | String | A http(s) URL that resolves to a HTML page. |
JavaScript SDK Template
connection.FeatureSummarizeUrl(identity, url, {
success: function(response) {
// response.summary
},
failure: function(reason) {
}
});
Request response fields
| name | type | documentation |
|---|---|---|
| summary | ObjectNode | A json summary of a URL |
Method: ReplicationCreate
wire method:replication/create
Replicate low level data
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
Streaming payload fields
| name | type | documentation |
|---|---|---|
| reset | Boolean | Signal that the associated delta should reset the entire state of the replication. |
| change | ObjectNode | A json change behind a replica. |
Method: ReplicationEnd
wire method:replication/end
Stop replicating data
Parameters
| name | required | type | documentation |
|---|
This method simply returns void.
Method: AttachmentStart (JS)
wire method:attachment/start
Start an upload for the given document with the given filename and content type.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| space | yes | String | A 'space' is a collection of documents with the same schema and logic, and the 'space' parameter is used to denote the name of that collection. Spaces are lower case ASCII using the regex a-z[a-z0-9-]* to validation with a minimum length of three characters. The space name must also not contain a '--' |
| key | yes | String | Within a space, documents are organized within a map and the 'key' parameter will uniquely identify documents. Keys are lower case ASCII using the regex [a-z0-9._-]* for validation |
| filename | yes | String | A filename is a nice description of the asset being uploaded. |
| content-type | yes | String | The MIME type like text/json or video/mp4. |
JavaScript SDK Template
connection.AttachmentStart(identity, space, key, filename, content-type, {
next: function(payload) {
// payload.chunk_request_size
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| chunk_request_size | Integer | The attachment uploader is asking for a chunk size. Using the WebSocket leverages a flow control based uploader such that contention on the WebSocket is minimized. |
Method: AttachmentStartByDomain (JS)
wire method:attachment/start-by-domain
Start an upload for the given document with the given filename and content type.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| identity | yes | String | Identity is a token to authenticate a user. |
| domain | yes | String | A domain name. |
| filename | yes | String | A filename is a nice description of the asset being uploaded. |
| content-type | yes | String | The MIME type like text/json or video/mp4. |
JavaScript SDK Template
connection.AttachmentStartByDomain(identity, domain, filename, content-type, {
next: function(payload) {
// payload.chunk_request_size
},
complete: function() {
},
failure: function(reason) {
}
});
Streaming payload fields
| name | type | documentation |
|---|---|---|
| chunk_request_size | Integer | The attachment uploader is asking for a chunk size. Using the WebSocket leverages a flow control based uploader such that contention on the WebSocket is minimized. |
Method: AttachmentAppend
wire method:attachment/append
Append a chunk with an MD5 to ensure data integrity.
Parameters
| name | required | type | documentation |
|---|---|---|---|
| chunk-md5 | yes | String | A md5 hash of a chunk being uploaded. This provides uploads with end-to-end data-integrity. |
| base64-bytes | yes | String | Bytes encoded in base64. |
This method simply returns void.
Method: AttachmentFinish
wire method:attachment/finish
Finishing uploading the attachment upload.
Parameters
| name | required | type | documentation |
|---|
Request response fields
| name | type | documentation |
|---|---|---|
| asset-id | String | The id of an uploaded asset. |
JSON Delta Format
The core algorithm used for deltas is JSON under the merge operation as defined by RFC 7386 with one big exception around arrays.
Arrays are special because RFC 7386 does not have a great way to merge arrays when small changes occur within an element. Adama works around this by converting arrays to objects, and then reconstruct the arrays with two hidden
During the merge, we detect that an object is an array if:
- the prior version is an array
- the object contains an '@o' field
- the object contains an '@s' field.
Beyond arrays, the delta format also supports document based operational transforms which support collaborative text editing (For example, using Code Mirror 6). The text documents are converted to objects with three special fields: '$s', '$g', and '$i'.
Handling '@o' field (ordering operational transform)
The '@o' is an instruction to build the array from keys within the object. For instance, if the '@o' contains
['1', 'x', 'y', '2']
then the array formed is
[
obj['1'],
obj['x'],
obj['y'],
obj['2']
]
This allows small changes within elements to occur as '@o' is only transmitted when elements are added, removed, or re-ordered within the array. However, for small insertions within an array, then the format is rather excessive as it transmit keys. The '@o' array can leverage a prior version of the object. For example, if a delta contains an '@' with value:
[[0,3],'z']
then the array is formed as
[
prior[0],
prior[1],
prior[2],
prior[3],
obj['z']
]
This operational transform allows minimal reconstruction of the array such that insertions happen at any frequency in any place without much cost beyond a full client side reconstruction.
Handling '@s' (size setter transform)
This is a simpler array construction signal which assumes the keys are integers starting at 0. A '@s' value of 5 would construct an array of
[
obj[0],
obj[1],
obj[2],
obj[3],
obj[4]
]
Handling '$s', '$g', and '$i' keys for operational transform
| field | meaning |
|---|---|
| $s | sequencer |
| $g | generation |
| $i | initial value |
The generation of a text field represent a unique lifetime for the document, and changes with '$g' imply a complete change in both '$i' and '$s' signalling a different document.
The initial value is used to initialize the collaborative editor at construction, and the sequencer indicates that changes are available within the document. For example, if the value of '$s' changed from 3 to 5, then the following updates can be handed over to the editor.
changes = [obj[3], obj[4], obj[5]].
For more information, please see code mirror's collaborative editing sample
Testing
Low and behold, Adama has testing via "revertable invariants". This means that tests can manipulate the document, but the changes are not persisted. In the devbox, tests can run automatically on every local deployment.
Mental Model
Since state is so bloody hard to deal with, the best way to leverage Adama's testing is to probe the document and validate invariants based on existing data or data recently added.
Example from product management suite
procedure body_create_task(CreateTask ct) {
if ((iterate _projects where id == ct.project_id)[0] as project) {
project._tasks <- ct;
}
}
channel create_task(CreateTask ct) {
body_create_task(ct);
}
test create_project_with_tasks {
_projects <- {name: "Name", description:"description"} as p_id;
CreateTask ct;
for (int k = 1; k <= 4; k++) {
ct.name = "task " + k;
ct.notes = "";
ct.project_id = p_id;
body_create_task(ct);
}
maybe<Project> project_m = (iterate _projects where id == p_id)[0];
assert project_m.has();
if (project_m as project) {
assert 4 == project._tasks.size();
}
}
At this time, channels can not be invoked, so this is something to be fixed.
Web Serving
Adama, at core, is a web server serving HTTP/HTTPS/WebSocket. This section is going to be about how requests are routed. Adama serves content and provides various ways of transacting with Adama documents. From a content servicing perspective, Adama serves up:
- RxHTML shells
- Spacial assets
- Document queries
GET
Adama uses the HTTP Host header to route traffic. Based on the Host, behavior may change. By default, all documents are publically addressable via the production endpoint (like https://aws-us-east-2.adama-platform.com/). Requests against the production endpoint of the form:
https://aws-us-east-2.adama-platform.com/$space/$key/$uri
will load the document and then execute a web get against the document. For example, the given uri
https://aws-us-east-2.adama-platform.com/your_space/your_key/my_thing
will execute the @web get handler:
@web get /my_thing {
return {html: "Hello World"};
}
Now, granted, this isn't a pretty URI, so Adama offers custom domains. In your domain register, if you point www.mydomain.com to the production endpoint via a CNAME, then you can map this domain to a space and/or document. In the CLI, this is available via:
java -jar ~/adama.jar domain map
This command requires --domain www.mydomain.com and --space your_space minimally. There is also --key your_key and --route false/true. The route flag only applies to the GET verb as there is a conflict between the document and the space. Here, there is a bit of complexity, so let's bring in a diagram.
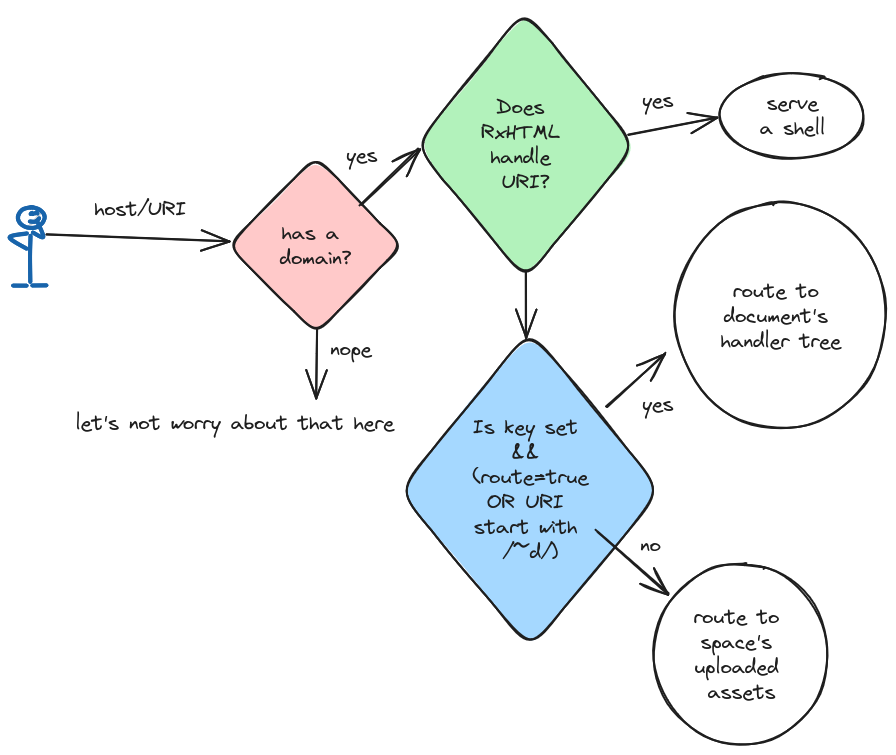
The common scenario is to map a domain to a document, see multi-tenant products.
POST/PUT/DELETE
Adama unifies and normalizes PUT/POST and always go to a document (as spaces only provide readonly serves and RxHTML has no write path).
Multi-tenant products
Each document within Adama can be hosted on a domain such that each document's web processing capabilities are addressable via domain. This also means connections can be domain centric providing seemless multi-tenant hosting where each document is a single silo application.
TODO: talk about the domain actions (sign in, put, )
RxHTML
The forest of root elements
With RxHTML, the root element is no longer <html>. Instead, it is a <forest> with multiple pages (via <page> element) and templates (via <template> element). While there are a few custom elements like <connection> (connect the children html to an Adama document) and <lookup> (pull data from the Adama document into a text node), the bulk of RxHTML rests with special attributes like rx:if, rx:ifnot, rx:iterate, rx:switch, rx:template, and more. These attributes reactively bind the HTML document to an Adama tree such that changes in the Adama tree manifest in DOM changes.
The root elements within a <forest>
There are three core elements under a <forest>: pages, templates, and the one true shell.
<page uri="$uri">
A page is a full-page document that is routable via a uri.
<forest>
<page uri="/">
<h1>Hello World</h1>
</page>
</forest>
The uri is broken up into components by splitting via the '/' character and the uri must alway start with '.'. For example, the uri "/foo/page/doctor" breaks down into three components
| index | component |
|---|---|
| 0 | foo |
| 1 | page |
| 2 | doctor |
These components are all fixed constants, but we can introduce both numeric and string variances by prefixing the component with the '$' character.
Beyond the uri, a page may also require authentication. This is denoted by the valueless attribute authenticate. When there is no default identity available, requests to that URI will forward to the page marked with the valueless attribute default-redirect-source. For example:
<forest>
<page uri="/product" authenticate>
The secure product
</page>
<page uri="/signin" default-redirect-source>
</forest>
<template name="$name">
A template is fundamentally a way to wrap a shared bit of RxHTML within a name. At core, it's a function with no parameters. Templates are how RxHTML achieve user interface re-use, and the philosophy is akin to duck typing where if the data behaves like a duck, then a template will make the duck pretty.
<forest>
<template name="template_name">
<nav>
It's common to use template for components
that are repeated heavily like headers,
components, widgets, etc...
</nav>
</template>
</forest>
However, there are parameters via the <fragment> element and the rx:case attribute. See below for more details.
<forest>
<template name="template_name_that_switches">
<nav>
It's common to use template for components
that are repeated heavily like headers,
components, widgets, etc...
</nav>
<fragment case="x" />
<fragment case="y" />
<fragment case="x" />
</template>
</forest>
Templates can be invoked in one of two ways: as a child or inline. The above template can be invoked via the rx:template attribute as a child.
<forest>
<page uri="/use-template-child">
<div rx:template="template_name_that_switches" class="clazz">
<div rx:case="y">
[Y]
</div>
<div rx:case="x">
[X]
</div>
</div>
</page>
</forest>
This will has the effect of generating DOM like:
<div class="clazz">
<nav>
It's common to use template for components
that are repeated heavily like headers,
components, widgets, etc...
</nav>
<div>[X]</div>
<div>[Y]</div>
<div>[X]</div>
</div>
Now, if the parent div is not desired, then <inline-template> is available as a pseudo-node within RxHTML.
<forest>
<page uri="/use-template-child">
<inline-template name="template_name_that_switches">
<div rx:case="y">
[Y]
</div>
<div rx:case="x">
[X]
</div>
</inline-template>
</page>
</forest>
This will act as if inline-template doesn't exist and merge the tree into the parent. This requires care as some elements or attributes will inject a div when needed.
The shell
An RxHTML forest can only have one <shell> element which is used to configure the generated application shell.
Data binding with <connection space="$space" key="$key" >
Data can be pulled into HTML via a connection to an Adama document given the document coordinates (space and key).
<forest>
<page uri="/">
<connection space="my-space" key="my-key">
... use data from the document ...
</connection>
</page>
</forest>
Alternatively, connections can be established via the domain for use in a multi-tenant product.
<forest>
<page uri="/">
<connection use-domain>
... connect to the domain referenced by the domain ...
</connection>
</page>
</forest>
Pathing; understanding what $path values
The connection is ultimately providing an object, and various elements and attributes will utilize a value as a path. We see this directly in the <lookup> text element.
...
<lookup path="my_field" />
...
This will find the value the value at my_field within the document and convert it to a text node.
The mental model being played out is that a connection is providing a document that is a hierarchical in nature. We use pathing similar to how file systems provide a current working directory. At the start of a connection, we start in the root of the document. Various attributes will manipulate the pathing, but we can also explicitily navigate the directory for lookup.
This path may be a simple field within the current object, or it can be a complex expression to navigate the object structure.
| rule | what | example |
|---|---|---|
| /$ | navigate to the document's root | >lookup path="/title" /> |
| ../$ | navigate up to the parent's (if it exists) | >lookup path="../name" /> |
| child/$ | navigate within a child object | >lookup path="info/name" /> |
Viewstate versus Data
At any time, there are two sources of data. There is the data channel which comes from adama, and there is the view channel which is the view state.
The view state is information that is controlled by the view to define the focus of the viewer, and it is sent to Adama asynchronously.
You can prefix a path with "view:" or "data:" to pull either source, and in most situations, the default is "data:".
Using data: pulling in a text node via <lookup path="$path" >
<forest>
<page uri="/">
<connection space="my-space" key="my-key">
<h1><lookup path="title" /></h1>
<h2><lookup path="byline" /></h2>
<p>
<lookup path="intro" /><
</p>
</connection>
</page>
</forest>
Lookup's transforms
The lookup pseudo-element has a transform attribute that runs a function to transform the input into a nicer looking output.
| transform value | behavior |
|---|---|
| principal.agent | pull out the agent from a principal |
| principal.authority | pull out the authority from a principal |
| trim | trim the string |
| upper | convert the string to upper case |
| lower | convert the string to lower case |
| is_empty_str | returns true/false if the string is empty |
| is_not_empty_str | returns true/false if the string is not empty |
| jsonify | convert the lookup value to a string via JSON |
| time_now | get the current time now |
| size_bytes | convert a number into a size with a suffix of B, KB, MB, GB |
| vulgar_fraction | converts a double into a integer part with the closest unicode vulgar fraction (eighths) |
| time_ago | convert a datetime into a time ago |
| time | convert a datetime or time from military time to |
Using data: connecting data to attributes
Attributes have a mini-language for building up attribute values using variables pulled from the document or conditions which control the output.
| syntax | what |
|---|---|
| {var} | embed the text behind the variable into the string |
| [b]other[/] | embed the stuff between the brackets if the evaluation of the variable b is true |
| [b]true branch[#]false branch[/] | embed the stuff between the brackets based of the evaluation of b |
| [v=$val]other[/] | embed the stuff between the brackets if the evaluation of the value v is the given $val |
| [v=$val]true[#]false[/] | embed the stuff between the brackets if the evaluation of the value v being the given $val |
<forest>
<page uri="/">
<connection space="my-space" key="my-key">
<a class="[path-to-boolean]active[#]inactive[/]" href="#blah">
</a>
</connection>
</page>
</forest>
Attribute extensions to existing HTML elements
A Guiding philosophy of RxHTML is to minimally extend existing HTML elements with new attributes which bind the HTML tree to a JSON tree
<tag ... rx:iterate="$path" ... >
The rx:iterate will iterate the elements of a list/array and scope into each element.
This attribute works best when there is a single HTML child of the tag placed, and it will insert a div if there isn't a single child.
In terms of path, the resulting path is two levels deep: first added level is the list and second added level is the item.
<table>
<tbody rx:iterate="employees">
<tr>
<td><lookup path="name" /></td>
<td><lookup path="level" /></td>
<td><lookup path="email" /></td>
</tr>
</tbody>
</table>
rx:iterate respects rx:expand-view-state. rx:expand-view-state will force the view path to change to mirror the iteration. This allows each element in the iteration to have a unique view state.
<tag ... rx:if="$path" ... >
The rx:if will test a path for true or the presence of an object. If there is an object, then it will scope into it.
<div rx:if="active">
Show this if active.
</div>
Note: this only renders anything if the value active is present
<tag ... rx:ifnot="$path" ... >
Similar to rx:if, rx:ifnot will test the absense of an object or if the value is false.
<div rx:ifnot="active">
Show this if not active.
</div>
Note: this only renders anything if the value active is present
<tag ... rx:else ... >
Within a tag that has rx:if or rx:ifnot, the rx:else indicates that this element should be within the child if the condition on the parent is the opposite specified.
<div rx:if="active">
Show this if active.
<span rx:else>Show this if not active</span>
</div>
force-hiding
For rx:if and rx:ifnot, the behavior controls the children of the node. This is required because the node must be stable, and we can ameliorate with the valueless attribute force-hiding which will synchronize the result with the node's style.display as this is a common workaround. However, this then means that the associated rx:else will never render.
<div rx:ifnot="active" force-hiding>
Show this ONLY if active is true
</div>
<tag ... rx:switch="$path" ... >
A wee bit more complicated than rx:if, but instead of testing if a value is true will instead select cases based on a string value.
Children the element are selected based on their rx:case attribute.
<div rx:switch="type">
Your card is a
<div rx:case="face_card">
face card named <lookup path="name"/>
</div>
<div rx:case="digit">
numbered card with value of <lookup path="value"/>
</div>
</div>
Note: this only renders anything if the value is present
<tag ... rx:case="$value" ... >
Part of rx:switch and rx:template, this attribute identifies the case that the element belongs too. See rx::switch for an example.
If a dom element within a child with rx:switch doesn't have an rx:case then it is rendered for every case, and this is true for both rx:switch and templates.
<tag ... rx:template="$name" ... >
The children of the element with rx:template are stored as a fragment and then replaced the children from the <template name=$name>...</template>.
The original children be used within the template via <fragment />
<template name="header">
<header>
</header>
<div class="blah-header">
<h1><fragment /></h1>
</div>
</template>
<page ur="/">
<div rx:template="header">
Home
</div>
<page>
<fragment>
Fragment is a way for a template to gain access to the children of the invoking element.
Furthermore, fragments support case attribute to filter out children.
<signout>
Once this element is seen, the identities are destroyed
<tag ... rx:scope="$path" ... >
Enter an object assuming it is present.
<form ... rx:action="$action" ... >
Forms that talk to Adama can use a variety of built-in actions like
| rx:action | behavior | requirements |
|---|---|---|
| domain:sign-in | execute an authorize against the document pointed to by the domain | form inputs: username, password |
| domain:sign-in-reset | execute an authorize and password change against the document pointed to by the domain | form inputs: username, password, new_password |
| domain:put | execute a @web put against a document pointed to by the domain | form element has path attribute |
| domain:upload-asset | upload an asset (and maybe execute a send) | form inputs: files |
| document:sign-in | sign in to the document | form inputs: username, password, space, key, remember |
| document:sign-in-reset | sign in to the document and reset the password | form inputs: username, password, space, key, new_password |
| document:put | execute a @web put against a document | form element has attributes: path, space, key |
| document:upload-asset | upload assets to the indicated document | form inputs: files, space, key |
| adama:sign-in | sign in as an adama developer | form inputs: email, password, remember |
| adama:sign-up | sign up as an adama developer | form inputs: email |
| adama:set-password | change your adama developer password | form inputs: email, password |
| send:$channel | send a message | form inputs should confirm to the channel's message type |
| copy-from:$formId | copy the form with id $formId into the view state | - |
| copy:$path | copy the current form into the view state | - |
| custom:$verb | run custom logic | - |
<custom- ... rx:link="$value" ... >
TODO
<tag ... rx:wrap="$value" ... >
TODO
<input ... rx:sync="$path" ... >, <textarea ... rx:sync="$path" ... >, <select ... rx:sync="$path" ... >, oh my
Synchronize the input's value to the view state at the given path. This will propagate to the server such that filters, searches, auto completes happen.
<input type="text" rx:sync="search_filter" />
<option> text within rx:iterate
No children DOM elements are allowed within an <option> tag, so to use dynamic text, us label="{$path}" instead of <lookup> or any other DOM element
<select rx:iterate="$path">
<option value="$path" label="$path" />
</select>
<exit-guard guard="$path" set="$path" >
The <exit-guard> will protect against data loss by preventing transition to a new page if the guard path is set to true. If the guard path is true while a page transition happens, then the set path is raised to true.
<monitor path="$path" delay="10" rise="..." fall="..." />
The <monitor> element will watch a numeric variable and then fire events if the value rises or falls mirroring signal edge transitions.
<todotask>
For the sheer joy of task management, <todotask> formats a TODO item in the HTML and aggregates the task into a file within the devbox.
<title>
Unlike traditional title where the title is placed within the element, the title has a value attribute that can be reactively bound to the document.
<title value="Messages for {person_name}" />
Events (rx:click, etc...)
Adama supports running a very restrictive command language on various events. The semantics is that a command string evaluates left to right and is delimited by spaces.
...
<input type="text" value="{view:up} / {view:down}">
<button rx:click="inc:up dec:down">Click Me</button>
...
Sinces spaces delineate commands, the single quote character is used to open a string
<button rx:click="set:title='The Big Thing'">Change Title</button>
<button rx:click="set:title='The Next Thing'">Change Title Again</button>
Command language
| command | behavior |
|---|---|
| toggle:$path | toggle a boolean within the viewstate at the given path |
| inc:$path | increase a numeric value within the viewstate at the given path |
| dec:$path | decrease a numeric value within the viewstate at the given path |
| custom:$verb | run a custom verb |
| set:$path=$value | set a string to a value within the viewstate at the given path |
| raise:$path | set a boolean to true within the viewstate at the given path |
| lower:$path | set a boolean to true within the viewstate at the given path |
| decide:$channel | response with a decision on the given channel pulling (see decisions) |
| goto:$uri | redirect to a given uri |
| decide:$channel | respond to a decision for a given (TODO) |
| choose:$channel | add a decision aspect for a given channel (TODO) |
| finalize | if there are multiple things to choose, then finalize will commit to a selection |
| force-auth:identity=key | inject an identity token into the system |
| fire:$channel | send an empty message to the given channel |
| ot:$path=$val | the value at the path is a special order string used by order_dyn |
| te:$path | transfer the event's message into the view state at the given path |
| tm:$path|$x|$y | transfer the mouse coordinate's X and Y into the view state |
| reset | reset the form |
| submit | submit the form |
| resume | when an exit guard is place, this will resume the transition |
| nuke | finds the <nuclear> element containing the element throwing the event and then removes it from the DOM |
Standard Events
| rx:$event | behavior |
|---|---|
| click | the element was clicked |
| mouseenter | the mouse entered |
| mouseleave | the mouse left |
| change | the input field changed |
| blur | the input field lost focus |
| focus | the input field gained focus |
| check | input checkbox is checked |
| uncheck | input checkbox is unchecked |
Custom Events
| rx:$event | behavior |
|---|---|
| load | runs when the DOM element is bound |
| success | the form was success |
| failure | the form was a failure |
| submit | the form was submitted |
| aftersync | the rx:sync just synchronized |
Todo
- customdata
- wrapping
- decisions
Recipes
Templates
templates.rx.html
<forest>
<template name="my-template">
<h1>My template with content</h1>
<fragment />
</template>
</forest>
pages.rx.html
<forest>
<page uri="/product">
<div rx:template="my-template">
This is the main content of the page
</div>
</page>
</forest>
Output for /product
<div>
<h1>My template with content</h1>
This is the main content of the page
</div>
Navigation
main.rx.html
<forest>
<template name="my-nav">
<ul>
<li>
<a href="/product" class="[view:current=product]active[#]inactive[/]">Product</a>
</li>
<li>
<a href="/about" class="[view:current=about]active[#]inactive[/]">About</a>
</li>
</ul>
<fragment />
</template>
<page uri="/product">
<div rx:template="my-nav" rx:load="set:current=product">
<h1>My Product</h1>
</div>
</page>
<page uri="/about">
<div rx:template="my-nav" rx:load="set:current=about">
<h1>About</h1>
</div>
</page>
</forest>
Output for /about
<div>
<ul>
<li>
<a href="/product" class=" inactive ">Product</a>
</li>
<li>
<a href="/about" class=" active ">About</a>
</li>
</ul>
<h1>About Page</h1>
</div>
Multi-level navigation
main.rx.html
<forest>
<template name="my-nav">
<ul>
<li>
<a href="/product" class="[view:current=product]active[#]inactive[/]">Product</a>
</li>
<li>
<a href="/about" class="[view:current=about]active[#]inactive[/]">About</a>
<ul rx:if="view:current=about" force-hiding>
<li>
<a href="/about/team" class="[view:navsub=team]active[#]inactive[/]">Team</a>
</li>
</ul>
</li>
</ul>
<fragment />
</template>
<page uri="/product">
<div rx:template="my-nav" rx:load="set:current=product">
<h1>My Product</h1>
</div>
</page>
<page uri="/about">
<div rx:template="my-nav" rx:load="set:current=about">
<h1>About</h1>
</div>
</page>
<page uri="/about/team">
<div rx:template="my-nav" rx:load="set:current=about set:navsub=team">
<h1>About</h1>
</div>
</page>
</forest>
Output for /product
<div>
<ul>
<li>
<a href="/product" class=" active ">Product</a>
</li>
<li>
<a href="/about" class=" inactive ">About</a>
<ul force-hiding="true" style="display: none;"></ul>
</li>
</ul>
<h1>About Page</h1>
</div>
Output for /about/team
<div>
<ul>
<li>
<a href="/product" class=" inactive ">Product</a>
</li>
<li>
<a href="/about" class=" active ">About</a>
</li>
<ul>
<li>
<a href="/about/team" class=" active ">Team</a>
</li>
</ul>
</ul>
<h1>About Page</h1>
</div>
Modals
Dropdowns
Bulk editing
Field sets
Escape Hatches
rx:behavior
A simple pass-through indexing thingy... TODO
rx:custom
Ultimately, components care about three things: (1) reading data from server, (2) writing control state, (3) sending messages to the server to mutate data.
port:$path=$viewPath
attributes prefixed "port:" are injected to create functions such that the rx:custom module can emit data to the view state controlled by a path
parameter:$name=$value
attributed prefixed by "parameter:" are turned into a reactive object that the custom code can hook into to learn about updates
TODO: what is hard
- get by id not possible, it's not mounted
- good "settle" signal when the data and DOM are stable. How do you know when the DOM is ready to be scanned? or when it was updated? -> examples
examples:
- drag and drop where the items are dynamic
- easier to grab an element and add an event listener
- viewstate that is iterable AND THEN ViewState.merge can populate
- mini around around manipulating the view state with respect to trees
- lifecycle, research various other frames about lifecycle
- testing web components with RxHTML like shoe-lace
- feature flags
- any event -> access to the event data
- scrollbar -> figure better ways of addressing bars
- a better event escape hatcing (improving events that have java with full event parity
- manipulate data on front-end
rx:behavior
One escape hatch available to create great user experiences is the attribute rx:behavior which will run some custom javascript once the associated element is created. This is the most limited escape hatch since it scopes the customization down to just having access to (1) the associated DOM node, (2) the connection, (3) static config, (4) and the RxHTML framework. It's worth noting that the spirit behind rx:behavior is what is used to extend RxHTML, and this is made available for custom code.
Start with custom.js
Somehow, you will link a custom.js or whatcodeyouwant.js into the project via the <script> tag within the <shell>, and you can access rxhtml via window.rxhtml. As an example, we are going to build a simple and generic drag and drop system and evaluate how to make it the canonical default way to do drag and drop in RxHTML.
The core game starts by defining the behavior
window.rxhtml.defineBehavior('dnd', function (el, connection, config, $) {
// do fun things here
});
This enables elements
<div rx:behavior="dnd">Drag And Drop Me Bro</div>
Ideally, we want a drag and drop system and we work backwards from what needs to happen to invoke a change: send a message. Sending a message ultimately requires information from the element being dragged and the element being dropped on. Thus, dragging thing X to thing Y will generate a message taking information from both X and Y and merging them together. With this, we will annotate an element that is draggable with the element with data using attribute like drag:data:$field or and similarly for an element that is droppable drop:data:$field.
We will leverage the default draggable attribute to indicate that an element opts-in to being dragged, and we will introduce a new attribute drop:channel to indicate an element opts-in to being dropped upon and which channel to send the associate message to.
Given the composition of various drag and drop elements within the same page, we will also create a simple match making system such that the thing being dragged can even be dropped on the element with droppable. We will introduce a bit vector on both draggable and droppable elements under the attributes drag:types and drop:types. The value is a list of fields seperated by comma which we split on, and if the intersection of the bit vectors is true then we allow the drop.
Putting these requirements together, we come up with two helpers: (1) scan an element to produce a spec, (2) intersect two bit vectors.
var scanElementIntoSpec = function (type, spec, el) {
var dataPrefix = type + ":data:";
spec.data = {};
spec.types = { basic: true };
for (const attr of el.attributes) {
if (attr.name.startsWith(dataPrefix)) {
spec.data[attr.name.substring(dataPrefix.length)] = attr.value;
}
if (attr.name == type + ":types") {
spec.types = {};
var types = attr.value.split(",");
for (var k = 0; k < types.length; k++) {
spec.types[types[k]] = true;
}
}
}
};
var intersectTypes = function (a, b) {
for (t in a) {
if (b[t]) {
return true;
}
}
for (t in b) {
if (a[t]) {
return true;
}
}
return false;
};
Now, we leverage this in the defineBehavior call by sketching out the event structure
window.rxhtml.defineBehavior('dnd', function (el, connection, config, $) {
if (el.draggable === true) {
var drag = {};
el.addEventListener("dragstart", function (e) {
// START
});
el.addEventListener("dragend", function (e) {
// STOP
});
}
if ('drop:channel' in el.attributes) {
var drop = {};
drop.channel = el.attributes['drop:channel'].value;
el.addEventListener("dragenter", function (e) {
// ENTER
});
el.addEventListener("dragover", function (e) {
// OVER
});
el.addEventListener("dragleave", function (e) {
// LEAVE
});
el.addEventListener("drop", function (e) {
// DROP
});
}
});
At this point, we have all the tools to enable this element
<div class="cursor-move"
rx:behavior="dnd"
draggable="true"
drag:data:x="1"
drop:channel="some_adama_channel"
drop:data:y="0">
Thing A to Drag or Drop onto
</div>
to drop onto this element
<div class="cursor-move"
rx:behavior="dnd"
draggable="true"
drag:data:x="2"
drop:channel="some_adama_channel"
drop:data:y="20">
Thing B to Drag or Drop onto
</div>
START
When the browser detects an element should be dragged, it will invoke dragstart. We need to (1) mark the element has being dragged so we don't drop onto itself, (2) read the data from the element being drag and copy into the data transfer.
el.addEventListener("dragstart", function (e) {
e.target._dragging = true;
var drag = {};
scanElementIntoSpec("drag", drag, e.target);
e.dataTransfer.setData("application/json", JSON.stringify(drag));
});
End
The only thing we need to do when the dragging ends is unmark that the element is being dragged.
el.addEventListener("dragend", function (e) {
e.target._dragging = false;
});
Enter
When an element enters another element, we need to (1) make sure we do nothing if it is itself, (2) extract the bit vectors, (3) intersect the bit vectors and set the dropEffect appropriately. A hard thing at hand is how to specify the behavior for visualizing the reaction, so for now we hack at the border.
el.addEventListener("dragenter", function (e) {
// ignore self
if (e.target._dragging) { return; }
e.preventDefault();
scanElementIntoSpec("drop", drop, e.target);
var drag = JSON.parse(e.dataTransfer.getData("application/json"));
if (intersectTypes(drag.types, drop.types)) {
e.target.style = "border:1px solid red";
e.dataTransfer.dropEffect = 'move';
drop.effect = 'move';
} else {
e.dataTransfer.dropEffect = 'none';
drop.effect = 'none';
}
});
Over
As a bug, we need to leverage the drag:over to echo the dropEffect
el.addEventListener("dragover", function (e) {
e.preventDefault();
e.dataTransfer.dropEffect = drop.effect;
});
Leave
The element is no longer interesting, so let's clean up
el.addEventListener("dragleave", function (e) {
e.preventDefault();
e.target.style = "";
});
Drop
When the drop happens, if the bit vectors intersect then we merge the data messages and send the message.
el.addEventListener("drop", function (e) {
e.preventDefault();
e.target.style = "";
scanElementIntoSpec("drop", drop, e.target);
var drag = JSON.parse(e.dataTransfer.getData("application/json"));
if (intersectTypes(drag.types, drop.types) && connection) {
var msg = {};
for (var k in drag.data) {
msg[k] = drag.data[k];
}
for (var k in drop.data) {
msg[k] = drop.data[k];
}
connection.send(drop.channel, msg, {
success: function () {
// TODO: fire success
},
failure: function (reason) {
// TODO: fire failure
}
});
}
});
And boom, a simple drag and drop system is born. Now, there are some thing to sort out before integrating into RxHTML such as:
I need a way to sort out
Audit Details
This is a linear deep dive of the features as I build the type checker.
element: <connection>
<connection> establishes the data: channel with a reactive tree that updates via a WebSocket.
- not a real element
- attribute 'name' will define the name of the connection
- mode: attribute 'use-domain' will use the location.host to pick a document via the domain mapping parts
- mode: attribute 'space' + attribute 'key' will find the document directly via the space and key
- mode: attribute 'billing' will connect to the current user's billing document
- attribute 'identity' is used for authorization
- attribute 'redirect' will be used to redirect the page to a different location
- attribute 'name', 'identity', 'redirect', 'space', 'key' are all reactive
- children branch based on connection status
- attribute 'keep-open' prevents the falling edge of connection status from from connected to disconnected from rendering the false branch
element: <connection-status>
<connection-status> is used to present the status of the connection (connected/disconnected)
- not a real element
- attribute 'name' is used to find the connection to reflect the status of
- children branch of connected and disconnected (rx:else/rx:disconnected)
element: <pick>
<pick> is used to find an existing connection to use as the data channel
- not a real element
- attribute 'name' is used to find a previously defined connection, this connection is then re-used
- children branch based on connection status
- attribute 'keep-open' prevents the falling edge of connection status from from connected to disconnected from rendering the false branch
attribute: rx:expand-view-state
This attribute modifies rx:scope, rx:iterate, rx:repeat such that the scope of the view state is expanded. For example, if you scope into an object, then rx:expand-view-state will scope the view to mirror it such that the view state is isolated to that object's name.
attribute: rx:scope
This attribute is like "change directory" where you scope into a object. rx:scope="field"
- rx:scope="field" is "cd field"
- rx:scope="/root" is "cd /root"
- rx:scope="../sibling is "cd ../sibling"
- rx:scope="view:x" is like "cd /mount/tree/view/x" (or cd "V:\x)
attribute: rx:iterate
This attribute will iterate over the elements in an array or list. Unlike scope, this will change directory effectively twice because there are two levels: the list level and the element level.
- The value follows the same rules as rx:scope EXCEPT each iterate also scopes into the element by index
- Requires there to be exactly one child element. If this isn't the case, then a false div is injected.
- Hint: for <table> use <tbody>
attribute rx:if, rx:ifnot
Conditions!
- at core, rx:if and rx:ifnot are the same up beyond how the value is expressed
- branch: "decide:$channel" will be true when there is a decision to be made based on the 'name' (default to the 'name' attribute)
- branch: "choose:$channel"/"chosen:$channel" will be true when a value has been chosen for a multi-select as determined by channel & name
- branch: "finalize:$channel" will be true if a multi-select is capable of being sent
- rx:if="$path" is true when the given path evaluates to a value of true (or a value exists)
- rx:if="$path1=$path2" is true when the given path evalutes to values that are equal
- attribute 'force-hiding' when present will show/hide the dom element based on the true branch (this ignores rx:else from a rendering perspective)
A decision is a concept of Adama from board game days where there is an inversion of control such that the server asks the client to make a decision. This decision is determined by a channel along with a unique field determined by the name attribute. The default field is 'id'.
A multi-select decision is when the server asks "pick between #X to #Y elements from the given array."
An odd behavior of rx:if is it only renders either the true/false branches if the $path is valid and has a value.
attribute: rx:monitor
rx:monitor will watch the given path and if it is a number will trigger rx:rise and rx:fall commands
- rx:rise is fired when the integer/number goes up (or becomes true for the first time)
- rx:fall is fired when the integer/number goes down (or becomes false for the first time)
attribute: rx:behavior
rx:behavior is an escape hatch for very simple behaviors
See escape hatches
attribute: rx:wrap (deprecated)
rx:wrap is the precursor to rx:custom, see escape hatches
attribute: rx:custom
rx:custom behaves like rx:template except custom JavaScript code run which is registered.
see escape hatches
attribute: rx:repeat
rx:repeat is like rx:iterate except the path revolves an integer
- as the number increases, more children are added
- as the number decreases, the most recently added children are removed
This is useful very useful for adding form elements dynamically for a form submission
attribute: rx:switch
rx:switch works with rx:case such that path revolves a value and the DOM is constructed on the fly based on the value. The immediate children are chosen based on rx:case's value matching the value of the path resolved via rx:switch. As a side effect, this allows multiple children to be added such that complex things are built. Note: this behavior is respected in templates
<div rx:switch="thing">
Always rendered
<div rx:case="a">Thing is A</div>
<div rx:case="b">Thing is B</div>
<div rx:case="a">Thing is A</div>
</div>
attribute: rx:template
This attribute is used to control the children of the element by pulling from a <template> element
The children within a template can use rx:case to pick
element: fragment
When used within a <template>, this references the children of the invocation.
<forest>
<template name="foo">
<nav>
Hello <fragment/>
</nav>
</template>
<page uri="/demo">
<div rx:template="foo">
World
</div>
</page>
</forest>
fragment also has the capability of leveraging the attribute rx:case
<forest>
<template name="foo">
<nav>
Hello <fragment case="name"/>!
It is time to begin the <fragment case="task"/>
</nav>
</template>
<page uri="/demo">
<div rx:template="foo">
<span rx:case="name">World</span>
<span rx:case="task">Ritual</span>
</div>
</page>
</forest>
attribute: children-only
For rx:case usage (rx:switch and templates), the "children-only" attribute will ignore the holding element and merge the children into the parent
<forest>
<template name="foo">
<nav>
Hello <fragment case="name"/>!
It is time to begin the <fragment case="task"/>
</nav>
</template>
<page uri="/demo">
<div rx:template="foo">
<span rx:case="name" children-only>World</span>
<span rx:case="task" children-only>Ritual</span>
</div>
</page>
</forest>
element: <inline-template>
This element is like rx:template except it merges the children of the <template> element into the current parent
- not a real element
- children are merged into the parent
element: <todo-task>
At one point, RxHTML had a vision of having an embedded project management system for tracking TODOs...
- should be deprecated
element: <monitor>
Like rx:monitor except introduces no dom element. Only supports rx:rise and rx:fall
- the attribute delay controls how the signal is debounced
element: <view-write>
This is a transfer of state from anything to the view.
<view-write path="v" value="{name} is {value}" />
element: <lookup>
Simply look up a field by path and render to the DOM as a text node.
- attribute 'path' is used to resolve to a value that is injected as a Text Node
- attribute 'transform' is a function that makes the value more pretty. For the datetime, 'time_ago' is a nice one
- attribute 'refresh' is used to recompute the transform based on a frequency (refresh="$x" where $x is an integer representing milliseconds)
TODO: how to add custom transforms
element: <trusted-html>
Simply look up a field by path and render to the DOM as a dom element under a 'div'
- attribute 'path' is used to resolve to a value that is then injected via innerHTML
element: <exit-gate>
Set a guard to protect traversal away from the current page
- attribute 'guard' is used to read only from the view a path to detect a guard
element: <title>
Normally, <title> is in the <meta> of a page, but since RxHTML operates with a forest of pages, the <title> is now part of a page based on any branch and uses a dynamic value attribute
<forest>
<template>
<title value="Hi {name}" />
</template>
</forest>
element: <view-state-params>
This little neat non-element will monitor variables in the view state via "sync:$name=$path" and then dump them into the location's search after ?$name=path. This lets the view state become reactively deep linked
elements (input, textarea, select)
- attribute rx:sync will periodically (see rx:debounce) write the value into the viewstate
- attribute rx:debounce defines the frequency (via milliseconds) of how often the viewstate gets updated
element <sign-out>
This element will destroy the connected identity
- attribute 'name' will define which identity to destroy
Password Handling
The field name "password" is considered sensitive and is never directly sent to the server. In general, it is not advised to use type="password" with any other name beyond "password" or "new_password" and the handful of virtual password fields.
RxHTML treats passwords (both with names of "new_password" or "password" along with an input type "password") as very restrictive and there are only two allowed ways of sending a password.
First, when sending a message to a channel, the passwords are hashed immediately such that the plain-text password is never seen by the data layer and thus never logged. Second, when sending a message to the @authorization handler, the "password" is striped from the message prior to sending to the @authorization handler while "new_password" is hashed immediately.
Virtual Password fields
There are three "special" field names that may use type="password" and these are to provide common authorization features like confirming a password or setting a new password.
- confirm-password
- confirm-new_password
Both "confirm-password" and "confirm-new_password" are used within the UI to respectively validate the "password" and "new_password" fields. These fields are stripped from the final message.
TODO and Future
So, The documentation for RxHTML and the reality have drifted a bunch. This document serves as a refresher of the entire code base for all the caveats that I need to document.
Attribute Command Language
- Choose
- Custom
- Decide
- Decrement
- Finalize
- Fire
- ForceAuth
- Goto
- Increment
- Manifest*
- Nuke
- Order Toggle
- Reload
- Reset
- Resume
- Set
- Submit
- SubmitById
- Toggle
- TogglePassword
- TransferError
- TransferMouse
- Scroll
- Uncheck (to deprecate)
Attribute Template Language
- autovar
- concat
- condition
- empty
- lookup
- negate
- operate
- text
- transform
Pre-processing
- static:content
- element: common-page (uri-prefix, static: template, init:, authenticate )
- page's attribute template:use and template:tag
Pathing
- dive into "path0/path1/path2" A
- root "/root" A
- parent "../parpath" A
- pick/switch "view:" "data:" A
Attributes
- branching: force-hiding A
- branching: rx:if, rx:ifnot A
- source: boolean mode A
- source: decide: A
- source: choose: A
- source: chosen: A
- source: finalize: A
- source: compare mode ($pathL=$pathR) A
- future source: eval:
- branching: rx:else / rx:disconnected / rx:failed A
- rx:monitor A
- rx:behavior A
- rx:repeat (solo child) A
- rx:iterate (solo child) (rx:expand-view-state) A
- rx:switch, rx:case
- rx:wrap (to deprecate) A
- rx:custom (big one) A
- rx:template A
- feature: "merge"
- rx:link (what is this?)
Config
- config:$name=$value on a template
- config:if=$b within a template
- config:if=!$b within a template
- config:if=$k=$v within a template
- config:if=!$k=$v within a template
-
Scoping
- rx:scope A
- rx:expand-view-state A
Attribute Setting
- boolean inputs
- href
- class / src (more to come)
- value (input, input, select, option)
- value (boolean input) OR button + disabled
- option + label
Events / Commands
- rx:click,
- rx:load
- rx:mouseenter, rx:mouseleave
- rx:blur, rx:focus
- rx:change
- rx:delay:$ms
- rx:rise, rx:fall
- rx:check, rx:uncheck
- rx:keyup, rx:keydown
- rx:settle, rx:settle-once
- rx:ordered - fire after a rx:iterate ordered an array
- rx:success, rx:failure
- rx:submit, rx:submitted
- rx:aftersync
- rx:new - fire after a new element was introduced into an rx:iterate or rx:repeat was incremented
Forms
- rx:identity (should this be just identity)
- rx:action
- send:$channel
- document:authorize
- domain:authorize
- document:sign-in, domain:sign-in, document:sign-in-reset, domain:sign-in-reset (deprecated)
- document:put
- domain:put
- adama:sign-in
- adama:sign-up
- adama:set-password
- dynamic:send
- custom:
- adama:upload-asset (to remove)
- document:upload-asset
- domain:upload-asset
- copy-form:$ID (to deprecate?)
- copy:$path (to deprecate)
Form Behavior
- rx:forward
- rx:success
- rx:failed
- rx:submit
- rx:submitted
- rx:failure-variable (to deprecate)
- default rx:success, rx:failure (to deprecate)
Unknown
- rx:link
Root elements
- template
- page
- shell
Elements
- fragment / fragment & case A
- monitor A
- view-write A
- lookup A
- lookup transforms A
- lookup refresh A
- trustedhtml (like lookup but for HTML) A
- exit-gate (guard, set) A
- todo-task A
- title A
- view-state-params A
- view-sync (to deprecated?)
- connection-status A
- connection A
- local-storage-poll
- document-get (TODO)
- domain-get
- pick A
- custom-data
- input/text-area/select (rx:sync) (TODO, write to multiple places) A
- input/text-area/select (rx:debounce) A
- sign-out A
- inline-template A
RxObject
- parameter:
- search:
History and Motivations behind Adama (i.e. Why!?!)
"Why" is a very hard (and sometimes painful) question to answer because it cuts so deep, and the answer boils down to the a motivating problem, some values held by the inventor, and a whole lot of frustration.
It all starts with the original design to bring friends together around an online Battlestar Galatica (the board game). However, the mind breaking complexity of the interplay of all the rules and player capabilities required a new kind of thing. That new thing had to manifest some values, and those values are simply:
- Laziness which makes the job easier to get done with more capabilities.
- Affordability because the solution shouldn't break the bank and good things happen when costs trend towards zero.
- Stability because a thing built today should work tomorrow until the heat death of the universe.
- Fun because building should be fun.
Now, the funny bit is that this all started with a couple of tools to make representing state easier, and then it turned into a giant document store with a full programming language. It wasn't planned, but it's pretty neat. This lead to a post-hoc attempt to define what this thing even is:
Origin Story
This programming language was born from a desire to bring a great game board-game online: Battlestar Galactica. I absolutely love board games. Unfortunately, every time I tried to implement it or any other board game, I find myself broken, hating everything about the technology I use.
At core, I believe board games represent a limit point of both technical and product complexity where traditional web techniques break down. However, old-school gaming techniques work better, but these old-school techniques have their own issues. The first motivation of this project is to bridge how web and old-school gaming techniques can work together in a cohesive way.
The complexity of a board game manifests when describing the implicit state machine required for people to communicate and execute complex rules which interact among players within a single conceptual "turn". We take day to day conversations for granted, and the best way to overcome this technically is to eschew classical HTTP/1.1 and use WebSockets (or just a socket). However, the moment you embrace WebSockets, you have a whole new world of hurt because the internet is not reliable enough for a six-hour board game.
Furthermore, I believe good things happen when compute and storage come together. I've worked and tinkered in this space for a while, and Adama is the culmination of 20 years of problems and experience into a single language, runtime, and platform.
Now, I admit, things will not be perfect. This language is intended to be niche and limited, and I want to be exceptionally upfront about this. I don't want to over-promise that this language will cure cancer or any fanciful claims of grandeur, but I do believe we are living in a dark ages of sort with these machines. Ultimately, I strongly believe we can do better, but doing better requires putting a stake in the ground as to what better looks like.
This project is a stake in the ground.
About the name
Adama was a special Lamancha goat that my wife and I raised until he passed due to calcium stones that blocked his urethra. He was an adorable goat that would love to cuddle, and I named this project after him.
Embracing Laziness
A core principle within Adama is that we should off-load as much work as possible to the language and runtime. We should be lazy and allow the language to do some valuable heavy lifting for us. The question then is "how can the language help with building real things?".
Well, the challenge is that most of the "serious programmer" languages these days are within a narrow band and do similar enough things. Worse yet, we can be rather discriminatory when it comes to languages. For instance, consider Dijkstra once wrote:
It is practically impossible to teach good programming to students that have had a prior exposure to BASIC: as potential programmers, they are mentally mutilated beyond hope of regeneration.
Now, he was railing against a different BASIC than what you or I may know. I was raised with QBasic, which I would then leverage in Visual Basic for Applications. If you are a professional software engineer, then you may even sneer at VBA. However, we should ask why VBA is still used and learned. Is it just inertia? Or, is it that it is simple enough for simple tasks, and "non-serious programmer" people can understand it. Not only can "non-serious programmer" understand it, they can hack it!
Don't get me wrong, there are great reasons to hate on Basic/VBA; however, the antidote is not to force people to contend with category theory. Adama aims to bridge this in a reasonable and clear enough way, and the key is to be lazy. Specifically, Adama intends to co-opt the most accessible programming model ever devised: Excel.
With Excel in mind, Adama will do some heavy lifting for product builders. Adama developers will never ever need to think about:
- Serializing data from structures to byte arrays
- Using a network that will fail
- Using a disks that may fail
- Think about synchronizing state
Excel is the rallying cry for Adama because Excel is just so fucking awesome at being productive. The challenge with Excel is that shipping products with it is not competitive with shipping software in "serious languages" from "serious programmers" to build web products. Adama hopes is to be as productive as Excel except with pure text files.
Sadly, Just being super productive is not enough for this world. Adama must also support some super powers...
Affordability (i.e. Cheap)
We live in magical times when you can spin up a Linux machine for less than $5/mo. For the average individual, the power of that machine is unimaginable (when used efficiently). Unfortunately, this creates an illusion where things are cheap.
That $5/mo machine could power thousands of games, and you could turn that $5 into way more than $5 with a reasonable business model. You will have to, since there is a human cost for managing that $5/mo machine as machines fail. But, what happens when the revenue dips below the $5 + human cost? The game is shutdown, and a core group of fans are disenfranchised. You need not look further than archive.org to know that people generally have a hard time letting go of things.
Fixing this requires a new type of cloud which amortizes both the machine and human cost down. Furthermore, if the cost of a game can be driven so low, then investments could be leveraged to convert the ongoing cost to a single up-front payment.
Let's look at Amazon S3 as a model. As of 4/11/2020, Amazon S3 charges $0.023/mo per gigabyte. For modeling purposes, let's use $0.15/mo which was the price in 2010. Furthermore, embrace pessimism and assume there exists an investment vehicle which will only be able to guarantee 1% in a year forever. For the low up-front cost of $180 ($0.15 * 12 / 0.01), a single gigabyte could exist for as long as Amazon S3 exists.
This $180 price tags feels reasonable for an important document, but a gigabyte is a lot of data. A board game at an extreme maximum may use 100KB of storage. This represents paying two cents to keep that board game's source code alive forever.
Sadly, Amazon S3 only provides storage. This is where Adama comes into the picture for compute. Adama allows a storage service to perform arbitrary-enough compute. In essence, Adama is the spark that turns dead durable storage into lively durable compute storage.
What this means is that not only will the code for a game be able to live forever, but also players will be able to play any game ever written in Adama forever. Future players will still be on the hook to pay for playing a game, but the cost of a single game now is already ridiculously cheap if you can leverage a $5/month machine to run thousands of distinct games.
Stable computing
For a variety of reasons, code requires maintenance. Furthermore, software people are expensive (really expensive), so maintenance is expensive. This is a problem for crafting software because opportunity cost has to come in balance with keeping the lights on.
In theory, some things can be done right, but it is so hard that we can have scope the conditions of the game being played. Now, Adama, the language and runtime, has the goal to provide a stable platform. The back-end for a board game written in 2021 with Adama must still function in the year 3025. Why is this a goal? Well, it sounds fun, that's why.
Adama aims for long term stability, and solving this requirement requires understanding why code requires maintenance in the first place.
First, it is hard to get code right, so we have to fix issues. The good news is that this isn't the language's problem; it's your problem. If the code is wrong, then stability would mean it will stay wrong... forever. Keep in mind, COBOL still exists. Code broken in specific ways should remain broken.
Second, code does not exist in a vacuum. The code must run on a machine, and the code must leverage a runtime. Achieving stability requires defining how to leverage a machine, and then being exceptionally careful with the runtime.
Machines are, more or less, stable enough. Fortunately, machines can be emulated with virtual machines. Adama is initially targeting a virtual machine which should last 1000 years: the JVM. The JVM can run code from the 90s, but there can be breakage. For instance, that breakage generally happens at the edge which are explored due to performance. For Adama, we will therefore drop extreme performance as a requirement. Performance is a nice to have, but it is more important to focus on conceptual simplicity and keeping the math at the elementary level.
Runtimes require great care to build to remain stable. This means when something is added to the runtime, then it should remain functional for a very long time. With Performance a non-goal, the goal is for the runtime to only expose deterministic and simple features.
Achieving a stable runtime is a serious burden. Every API in Adama gets a serious amount of formal and rigorous scrutiny. As an example, there are no plans to add any "get the current time" function. The core reason is that function doesn't exist in a mathematical sense, and it is not deterministic and stable. For productivity, Adama will import some libraries, but only a minimal number of them are high quality and can adapt standards into the minimal interfaces that Adama supports (i.e. Netty for the server). Adama's code base will mostly be a monolith.
Third, stability requires a closed ecosystem. Adama will not support direct networking or disk access. This is why many games from the 90s can be emulated with great success, and this is why some MMOs are gone forever.
Fourth, stability requires a lack of growth. Adama and the runtime are limited such that no more than 1,000 people can play a single game at a time. There, growth solved!
The reality of this desire to achieve stability is a disciplined approach. This project is not going to be done in a weekend, but a decade.
Slow is smooth, smooth is fast.
Fun as a goal
Writing code can be fun, but there are many obstacles to achieving the orgasmic dopamine hits possible when things are working well. When progress is being made, good times are ahead. More often than not, coding can be exceptionally frustrating. Write code, then compile, wait, wait some more, oh crap, and things are still broken. Maybe write this code here, refresh the page, it isn't working. Why not?
Adama takes the position that tooling should be mostly in your face and out of your way. Adama is being designed where productivity and diagnostics are not just add-ons, but central features. Fun comes from speed and no waiting.
- Adama's validator and code compiler must run in single digit milliseconds for moderately large game back-ends.
- Adama's deployment must run in a sub-second timeframe.
- Tests written within Adama run in a sub-millisecond timeframe.
With such speed, each keystroke can be validated, and if things are not working then real-time diagnostics will tell you why (with your text editor of choice via LSP). If validation worked, then a deployment will happen, tests are run and reported (via LSP), and results are visible within the product. Keep in mind, Adama is aiming to be competitive with Excel. Typing in Excel produces results!
The same must be true in Adama. However, going fast sometimes causes a new set of problems. For instance, after a deployment, human interaction in a game may be needed to test it. Well, this interaction can change the state in a bad way. Thus, Adama must enable time travel!
Since Adama takes care of all state management, it also provides coherent ways of rewinding state and snapshotting state. Tests can be written against snapshotted state, and the test results can be reported in real-time.
Going fast, in a fun way, enables products to achieve results that are beyond "good enough". So much so, Adama unlocks new ways of thinking about automation.
What is Adama?
Beyond an adorable Lamancha goat who was named after William Adama from the amazing Battlestar Galatica show, much of what Adama is from an accidental journey of discovery by building tools to build an online board game. There was no specific goal, and the only semblance of cohesion is from the craftsman sensibilities to polish and reduce. After the fact, the question became "Wait, what even is this thing?"
One idea that emerged was the concept of a Living Document, and the short version is a document that can modify itself based on external signals (i.e. messages) and time.
In the language of games, Adama also represents the Dungeon Master who has the job of telling a story and coordinating players.
A Hacker News comment (which I'm unable to find) from Carl Hewitt indicated that everyone invents the actor model sometime in their career, and Adama is my version of a partial actor model.
Since Microsoft Excel were Lotus 1-2-3 were an influece on how to think with computers (and because reactivity is just so cool), Adama is a reactive compute engine that stores everything in a document. However, instead of infinite grids, Adama embraces tables within documents.
A key problem that reactivity makes simple is privacy where what people see is computed based on them rather than the sender. This allows for next level privacy gurantees should regulations intensify.
As time moved on with using the tool, the idea of single file infrastructure emerged emerged where that single Adama file allowed me to define the backend for a complete product.
What is a Living Document?
Let's start by defining a living document as opposed to a dead document. Take a look at the following example JSON document:
{
"name": "Jeff",
"state": "Washington",
"title": "Dark Lord"
}
This example JSON is a representation of a person living in the great state of Washington with an awkward title (it's me, tee hee), but this JSON is dead. It requires external stimulus to change. If you put this document inside a typical document store without any additional updates, then it will remain that way for as long as that document store exists.
A living document is the opposite of a dead document. A living document can be put within a living document store, and the document will update and change on its own over time. Take for instance the following Adama code:
public int ticks;
@construct {
ticks = 0;
transition #tick in 1;
}
#tick {
ticks++;
transition #tick in 1;
}
This Adama code defines:
- a publicly visible integer field called ticks (a singleton value scoped to the document).
- a constructor which runs only once when the document is created to initialize ticks and kick off the state machine
- a state machine transition that runs every second and increments the ticks field
In effect, a living document is just a state machine on top of a JSON document that can transition in three ways: time, messages from people, or shared data changes between other living documents. The above example illustrates time. See Actors and Dungeon Master for more details about how messages come into the picture. Shared data changes are a work in progress, so ping me if you want more details.
Alternatively, a living document is a tiny persistent server.
Mental Model: Tiny Persistent Servers
An exceptionally tiny persistent server is an alternative view of this concept. This is what the merging of state and compute looks like with Adama. With Adama, you outline the shape of your state and then open up mechanisms for how that state changes. This is comparable to building a server in whatever language you want except the discipline to correctly persist state outside of the server is handled for you by the runtime.
For the target domain of board games, this is exceptionally useful because representing the state of board games is a difficult task within itself. With Adama, a single document represents the entirety of a single game's state via a singular definition.
Now, representing the state inside a single document provides an exceptional array of features: versioning, debugging via time travel, an imagination for androids, atomic and consistent boundaries, locality homing, and more. These features will be documented in the future.
Actors, Actors, Actors
The actor model is worth considering as it expresses many ideas core to computing. The living document that Adama defines is a limited actor of sorts. Namely, it can only receive messages from users (or devices) and make local decisions and updates based on those messages. Currently, it is unable to create more actors or send messages to other actors. However, this basic and reduced actor model enables the living document to be useful.
Adama allows developers to define messages:
message MyName {
string name;
}
This Adama code outlines a structure with just a name field. Messages are used exclusively for messaging between the users and the living document. The next step is then to ingest a single message on a named channel:
public string name;
channel my_channel(MyName msg) {
name = msg.name;
}
This Adama code defines:
- a publicly visible string field called name (a singleton value scoped to the document).
- a channel named my_channel that outlines a function
- a variable within the function called who which represents a connection with a user (via the client type)
- a variable containing the message (msg) sent by the user
- a block of code to execute when the message arrives, and this code will associate the singleton name field name with the value coming from the human msg.name
This is the primary way for the living document to learn about the outside world. Internally, the following JSON represents the message sent on a persistent connection from a device:
{
"name": "Cake Ninja"
}
This message, when sent to the living document via channel "my_channel", will run the handler code and change the top level field name to "Cake Ninja".
The most important property of messages is that they are atomically integrated. This means that if a message handler aborts (via the @abort statement), then all changes up to the abort are reverted. For instance:
public string name;
channel my_channel(MyName msg) {
name = msg.name;
if (name == "newbie") {
@abort;
}
}
The above code will temporarily set the top level name field to "n00b" which is visible only to the running code, but the @abort will roll back all changes encountered, and it will be as if the message never happened. This is super important for ensuring the document is never inconsistent or torn.
Mental Model: Old School Chat Room
The mental model for the document is a receiver of messages from clients connected via a persistent connection. This persistent connection has signals based on client connectivity, and these meta signals are exposed via @connected and @disconnected events which are exceptionally useful.
@connected {
// keep track of who
}
@disconnected {
// remove who
}
These signals enable the document to identify who is connected and provide the features found in classical old school chat rooms: "Jeff has entered the conversation" and "Jeff has left the conversation".
Dungeon Master
With time and messages driving changes to the living document, the next challenge is organizing messages from multiple clients. This is where we combine the state machine model with messaging to turn Adama code into a "dungeon master" (or, a workflow coordinator).
This is accomplished by creating "incomplete" channels that yield futures. First, you define a message:
message PickANumber {
int number;
}
Then, you define the incomplete channel:
channel<PickANumber> decide_number;
Here, we see an incomplete channel which has no code associated to it, so what good is it? Well, the idea is to delay message delivery until something else asks for it. That is, other code is able to fetch a value from this incomplete channel when it makes sense.
Let's imagine a simple game of "who can pick a bigger number?". Two people must contribute a number, those numbers are compared, and the winner is given a score point. Play continues forever as this game is a game with no end.
In just this trivial game, there is a need to build a state machine formed by product questions:
- When do player 1 and player 2 learn they need to provide a number?
- How do we ask players to contribute?
- Do we ask players to contribute in sequence, or in parallel?
- If parallel, then how do we handle the ordering of contributions from players?
- How do we deal with duplicates from players?
- How do players deal with failure of sending a message?
- What happens if a connection to a player is lost?
This all manifests from failures and the difficulty of network programming. Network programming is exceptionally hard, but this is where Adama comes in to save the day. This game can be implemented with following logic:
// somehow, the document learned of the two people playing the game
principal player1;
principal player2;
// scores for the players
int score_player1;
int score_player2;
// somehow, the document got into this state, but when this runs
#play {
// both players are asked for a number
future<PickANumber> a = decide_number.fetch(player1);
future<PickANumber> b = decide_number.fetch(player2);
// we then await the numbers to be able to compare and score them
if (a.await().number > b.await().number) {
score_player1++;
} else {
score_player2++;
}
// let's play again for all time.
transition #play;
}
The above Adama code performs several actions, so there are comments to explain the more mundane elements. Critically important for this discussion, there are two key elements to focus on. First, this code is responsible for asking players for their numbers:
future<PickANumber> a = decide_number.fetch(player1);
future<PickANumber> b = decide_number.fetch(player2);
The fetch method on a channel will reach out to the client and ask for a specific type of message for delivery on that channel. This fetch returns a future which can be awaited to return the message from the user. Notice, concurrency is built into this model and both players can contribute their number independently at the same time. A future represents a value which will arrive... in the future.
The second key element is found in the following code to get the contributions from the players:
if (a.await().number > b.await().number) {
The await invocation here will block execution until the value arrives from the associated clients. Now, this is nothing new in terms of programming languages. However, this is a fundamental game changer for data storage, and this is the key element that simplifies board game back-ends.
This allows the state machine of interaction between users to be constructed with the flow of code rather than modelling an explicit state machine. With Adama, this implicit-code-flow-based state machine is also durable such that the server running the code can change without users noticing.
The server is in control of who is responsible for producing data and when, and failures don't manifest in the experience (beyond elevated latency).
Mental Model: Restaurant Ordering System
The mental model for the document is to behave as a broker between parties.
For instance, if you order food online for delivery, then you really hope the chef gets the order. This requires the technology to monitor a transaction across human-scale timeframes. It may take minutes for the hostess or chef to commit to the execution of the order, or to provide feedback about the viability of the order.
This timeframe elevates the challenge as the reliability and latency of the signaling between these two parties is critical. Adama greatly simplifies this challenge with low cognitive load.
Mixed Storage and Compute Engine
Doing stuff based on time, reacting to messages, and coordinating human behavior brings compute to the table in a fun and almost complete way. Previously, we've mentioned global fields within the living document, but we need more. We need containers of data, and the best container of data ever is: the table.
In Praise of Databases
The way a table works is you first define a record
record MyRecord {
public string name;
}
and then define a table:
table<MyRecord> my_records;
Tables are not directly exported to people, and instead require a formula to yield data. We can do that via the "iterate" expression
public formula records_by_name = iterate my_records order by name asc;
We leverage the messaging abilities to ingest to the table. The "<-" operator ingests data into tables and free form records.
message AddRecord {
string name;
}
channel my_channel(AddRecord msg) {
my_records <- msg;
}
Mental Model: Tiny Personal Databases
The key idea here is that data within a living document is akin to a personal database within a single file. This allows developers to leverage an appropriately scaled database per user or game whilst using NoSQL scaling techniques. This eliminates cross-document data bleed, limiting inter-document communication, but that is a worthy limitation for building a new private world.
Privacy respecting storage
So, exposing data from a table opens up the challenge of "well, wait, who can see that data?". One solution is to ensure all queries are respectful of the board game rules, but this requires ensuring all leafs in a forest are doing the right job. It would be better if the actual data could be encoded with who can see it. We start by defining the simplest model. So, here, we define an Account:
record Account {
public string name;
private string bank_account;
}
table<Account> accounts;
Notice that the public and private modifiers have been hijacked to mean "which humans can see this data!", and this mirrors my understanding of field visibility when I was a kid.
This was born from how to represent board game state such that secrets do not flow incorrectly to the wrong people. After all, if I can see your hand in poker, then you lose.
Classical databases were built around security within an organization and the granularity within the database is too coarse-grained. It's up to application developers to protect data between people, and this is a heavy burden. This burden was inherited by NoSQL. Instead, Adama believes that a document should contain all access rules to data, and the language aims to simplify that process.
The end goal here is to have a language which prevents information leakage to unintended parties, so developers are not in a position to accidentally leak data as reading data is entirely controlled by the document. The document is the source of truth with regards to privacy.
Mental Model: VIP Club
The document is an exclusive club, and you have an id card. That id card is checked when entering the club via security, and it grants you access to parts of the club.
Single file infrastructure
The state of the world
Building a web product is a complete pain in the ass. First, you must build the UI and then have the UI be hosted on a server which is usually stateless. The server then must implement an API to expose data to the UI, so the UI can be useful to enable people to do stuff. The API then must coordinate state with a database or other data stores, and if you want any modern features you will need a queue or use a messaging stack. The messaging stack must inter-op with the API server, and that stack also will reach out to a variety of notification services. All this then requires some form of infrastructure orchestration because you will inevitably give up on building a monolith and get a microservice architecture, and then reliability becomes a hard task because you will rely on the network to behave. The network will mostly behave, but everyone will periodically be forced to (re)learn how to deal with queueing theory.
Shit will happen, and services will fail due to growth. Holy crap.
There are so many things behind most websites, that it is a crazy mess. It's MADNESS, and it sure isn't fine. Is it any wonder that I'm full of hate?
A bold new world
Adama enables a different way of thinking such that a single file can define an entire product infrastructure. The UI still exists as a separate build, but the UI only really needs to talk to a single piece of infrastructure. This greatly simplifies the process of building software, but there are no silver bullets. This power is available because scale has been scoped and traded for ergonomics, so let's talk about limits.
A single living document can only live authoritatively on a single host. This limits two things: the update rate (CPU) and size (memory). The update rate must be balanced with the replication cost, and Adama is designed such that small updates manifest in small replication changes and minimal ingestion. This implies durability can be affordable, and it also implies that the ability to consume a living document can scale infinitely. The key limits at play are the update-rate and size.
The big missing piece as of this writing is the inability for documents to connect together, so there is no glue or index between documents. This, however, is a solvable problem.
Mental Model: The Tiny-House for User Data
As a builder, both relational databases and NoSQL stores will shard user data across various machines. As a somewhat privacy concerned user, this terrifies me as all my data is potentially on hundreds of machines. With Adama, all the logic and data can exist within a singular conceptually atomic unit of a document. It's like a tiny house of all your data, and it moves with you. This container model of all your data makes it simpler to comply with emerging regulations since both developers and users can trust where data actually is.
Cheatsheet
Types
string, bool, int, double, complex, long, principal, maybe
Privacy
public, private, viewer_is<$variable>
Compute
(privacy)? formula name = foo();
bubble name = foo();
Deeper Tour
Language basics
Adama is yet another language with braces in the tradition of C
/** comments are for friends */
procedure code() -> int {
int x = 42;
for (int k = 0; k < 10; k++) { x++; }
while (x > 0) { x--; }
var y = (x + 1) * x;
if (x == y) { y++; } else { y--; }
return y;
}
Strange things
Unlike other static languages with legacy behavior like integer division, Adama applies the principal of least surprise yet maximal correctness.
In math classes, we were taught to call out division of zero; Adama forces your hand by having division escape out the expected types.
procedure portion(int x, int y) -> double {
maybe<double> m_norm = x / (x + y);
if (m_norm as norm) {
return norm;
} else {
return 0.0;
}
}
Complex numbers
Similarly, Adama embraces complex numbers because all languages should. Complex numbers are awesome!
function len(double x, double y) -> double {
complex sqr = Math.sqrt(x * x + y * y);
return sqr.re();
}
Document structure
As a developer, you will create an Adama specification file which is just a text file that outlines the state of a document.
At the root level you have fields which can be single values or records.
public string name;
public int x;
public int y;
private int bank_balance;
record Pv { int x; int y; }
public Pv pvalue1;
public Pv pvalue2;
Relational data and table queries
Records can also be kept in a table.
An interesting aspect of this is that this is the only way to create "new" data. The language does not expose a memory model that developers have to think about as everything is acccessible from the root document.
Adama embraces the existing legacy model with table queries as this not only makes code more expressive, but it also provides the compiler the ability to optimize and have static query planning.
record Card {
public int id;
public int value;
public principal owner;
public int ordering;
}
table<Card> deck;
procedure shuffle() {
int new_order = 0;
(iterate deck shuffle).ordering = new_order++;
}
procedure deal(principal player, int count) {
(iterate deck
where owner == @no_one
order by ordering asc
limit count).owner = player;
}
Constructor
Once you have structured your data, you can populate a document at the time of construction.
@construct {
for (int k = 0; k < 52; k++) {
deck <- {value:k, owner: @no_one};
}
shuffle();
}
Loading
Change is the only invariant in life, so once a document is constructed; changes may require us to upgrade the data.
There is a load event that allows us to gate off of state to upgrade or mutate the document based on new code.
@load {
if (deck.size() == 52) {
// upgrade the game by adding another deck
for (int k = 0; k < 52; k++) {
deck <- {value:k, owner: @no_one};
}
}
}
Message Handling
Once constructed, message handling is one mechanism for documentation mutation.
message Payload {
int value;
}
public int value;
channel set_value(Payload p) {
value = p.value;
}
Here, we provide a way for people to ask the document for some cards to be vended to them.
message DrawCard {
int count;
}
channel draw_card(DrawCard dc) {
(iterate deck
where owner == @no_one
order by ordering asc
limit dc.count).owner = @who;
}
Reactivity
As data fills the document, you want to expose that to people; this is done reactively via formulas.
So, here, we express the count for the number of cards and a boolean indicating if there are any cards available.
These fields update when the deck update.
public formula cards_left =
(iterate deck
where owner == @no_one).size();
public formula cards_available = cards_left > 0;
Privacy - policies
As you expose data to players, it's important to consider the privacy of that information. This is vital if you want to maintain secrets. Here, we have a custom use_policy on the super secret data field. The policy is evaluated when that data is being vended to people.
Protecting fields is not enough as we also want to limit side channels, so we require the policy to even know that the object exists.
In terms of privacy, this is a robust system for ensuring that people can only see what they are allowed.
record R {
public int id;
private principal owner;
// guard the field
use_policy<see> int super_secret_data;
// guard the existence of the entire record
require see;
policy see {
return @who == owner;
}
}
table<R> recs;
public formula all = iterate recs;
Privacy - bubbles
The privacy policies provide a security model to eliminate information disclosure; however, it is not the most efficient way to handle many scenarios.
This is where the privacy bubble comes into play where fields can be reactively computed with the viewer. These viewer dependent queries allow for efficiency in vending data.
bubble yours = iterate recs where owner == @who;
bubble hand = iterate deck where owner == @who;
State machine & time;
Another way to change the document is by using time via the state machine. Each document has one state machine label to run at any given time.
Here, the document starts with the countdown variable set to 10 and every minute that passes will decrement the countdown variable.
int countdown;
@construct {
countdown = 10;
transition #bump in 60;
}
#bump {
countdown--;
if (countdown > 0) {
transition #bump in 60;
}
}
Asynchronous dungeon master
We can invert the typical control from of message handing to message asking. Here, imagine the document is a dungeon master that is asking players to answer questions.
In the below example, the document is asking the current player to make a move.
message Move { int piece; int x; int y; }
channel<Move> ask_move;
public principal current_player;
#play {
let move = ask_move.fetch(current_player).await();
// apply the move to the state...
next_player();
transition #play;
}
Access control and presence
As we build up the document and make it do something useful, we will want to lock down who can read the document.
This is available via the connected event which must return true for the given user to establish a connection.
private principal owner;
public int active;
@construct {
owner = @who;
}
@connected {
if (@who == owner || @who.isAnonymous()) {
active++;
return true;
}
return false;
}
@disconnected {
active--;
}
Static policies
We can further lock down who can create a document via static policies within the Adama specification.
This document and language are the perfect place to stash configuration and access control policies for everything that isn't document related. The below create policy really locks down who can explicitly create a document.
Document invention is the process of creating a document on demand with zero arguments for a constructor. Combine document with a flag to delete the document when everyone closes is a great way create ephemeral experiences.
Philosophically, most behaviors and configuration belong in the adama specification to further simplify operations.
@static {
create {
return @context.ip == "127.0.0.1" &&
@context.origin == "https://localhost" ||
@who.isAdamaDeveloper();
}
invent {
return @who.isAnonymous();
}
maximum_history = 100;
delete_on_close = true;
}
Deletion
A document can, at any time delete itself.
#done {
Document.destroy();
}
An external API is available to delete, but this requires yet another policy
public bool finished;
@delete {
return finished && @who == owner;
}
Web? Web!
We can leverage the language as well to open more ways of talking to a document. Here, we allow read only queries via HTTP GET and a mutable HTTP put.
This allows Adama to speak via Ajax, but it also allows web hooks to communicate to a document.
public string name;
@web get / {
return {html:"Hello " + name};
}
message M { string name; }
@web put / (M m) {
name = m.name;
return {html: "OK"};
}
Attachments
asset latest_profile_picture;
@can_attach {
return @who == owner;
}
@attached (a) {
latest_profile_picture = a;
}
@web get /assets/$path* {
if ( (iterate _resources where resource.name() == path)[0] as found) {
return {asset:found.resource};
}
return {html:"Not Found"};
}
RxHTML
<div>
<tbody rx:iterate="rows">
<tr>
<td><lookup field="name"</td>
<td>
<div rx:if="active">Active</div>
<div rx:ifnot="active">Inactive</div>
</td>
</tr>
</tbody>
</div>
Building and Contributing
Building Adama requires
- Java SDK 17+
- Maven 3
- Python 3
- uglify-js ( npm install uglify-js -g )
build.py
Adama uses extensive code generation (however, there may be some platform unstable bugs), and code generation is required for:
- adding/updating APIs to saas
- building the error tables
- introducing new messages between web client (i.e. the load balancer) to the adama service
- regenerating and validating changes to the language and template (there are code generated tests that validate output is stable between check-ins)
- updating gossip codec
- enforcing copyright notice
- regen the platform version
core workflow
While developing, regenerating is done via
./build.py --jar --fast --generate
where tests are skipped and generation marches onward. Caveat: this introduces some platform-specific noise which is not desirable, and we need to eradicate those differences.
Prior to checking in:
./build.py --clean --jar
The binary will be release/adama.jar which you can copy to your home or project path.
Roadmap
This document is a living road map of the Adama Platform. As such, it contains the investment details for the entire vision and future products.
Developer relations & adoption
The current story for developers is "meh", so these items help improve and modernize the developer experience.
| project | IP | milestones/description |
|---|---|---|
| vs code extension | X | (1.) Syntax highlighting, (2.) Language server protocol (LSP) - local |
| sublime extension | Since sublime is so fast, try to get core Adama language support for syntax highlighting | |
| Android client | (1) Write a simplified web-socket interface, (2) implement interface with OkHttp, (3) update apikit code generator to produce a SDK talking to the web socket interface. | |
| iOS client | (1) Write a simplified web-socket interface, (2) implement interface with ?, (3) update apikit code generator to produce a SDK talking to the web socket interface. | |
| capacitor.js template | A template to turn an RxHTML project into a mobile app with deployment pipeline | |
| integrate-linter | integrate the linter to detect issues prior launch; address #62 | |
| lib-react | library to use Adama with React | |
| lib-vue | library to use Adama with Vue | |
| lib-svelte | library to use Adama with svelte |
Documentation
| project | IP | description |
|---|---|---|
| kickoff demos | X | See https://asciinema.org/ for more information |
| client-walk | A detailed walkthough about how to use the client library, the expectations, and core APIs | |
| improve overview | Make the overview easier to understand, more details, etc | |
| cheat-sheet | document the vital aspects of the language and provide copy-pasta examples | |
| micro-examples | a mini stack-overflow of sorts | |
| tutorial-app | walk through the basics of building an Adama with just Adama and RxHTML | |
| tutorial-twilio | build a twilio bot as an example with details on calling services | |
| tutorial-web | a HOWTO host a static website with Adama | |
| tutorial-domain | a HOWTO use Adama's domain hosting support | |
| zero-hero | a breakdown of using the bootstrap tooling to build a complete app | |
| feature-complex | Write about complex number support | |
| feature-maybe | (1) write about how maybes work, (2) write about maybe field deref, (3) write about math and maybe | |
| feature-lists | write more lists | |
| feature-map | write about map transforms | |
| feature-dynamic | write about dynamic types | |
| feature-viewer | write about @viewer | |
| feature-context | write about @context | |
| feature-web | write about @headers / @parameters | |
| map/reduce-love | X | reduce love along with maps |
| functions | procedure, aborts, functions, methods | |
| enumeration/dispatch | talk about dispatch | |
| feature-services | talk about services and linkage to first party along with third party http (and encryption of secrets) | |
| feature-async | talk about async await,decide,fetch, choose, and result | |
| result type | talk about the result type | |
| feature-sm | talk about the state machine, invoke, transition, transition-in | |
| web-put | talk about the web processing | |
| stdlib code-gen | generate documentation from the stdlib (i.e. embed docs in java as annotations) (embed documentation in type) | |
| document or kill rpc | The rpc helper is an interesting way of making channels, but it isn't used right now... kill or document | |
| assets | ||
| rxhtml auth stuff | ||
| auto ids in RxHTML |
Standard Library
| project | IP | description | |
|---|---|---|---|
| stats | build out a statistics package that is decent and correct (median isn't good right now) (sum, average, median, product, count_non_zero) | ||
| to/from Base64 | convert a string to and from Base64 with maybe<string> | ||
| substituteFirst | find the needle in a haystack and replace the first instance | ||
| substituteLast | find the needle in a haystack and replace the last instance | ||
| substituteAll | find the needle in a haystack and replace the every instance | ||
| substituteNth | find the needle in a haystack and replace the n'th instance | ||
| format | need var_args (just use a string[]) support, but the idea is to allow efficient string construction from many known finite pieces | ||
| split /w limit | only split a certain degree | ||
| find | find a string within a string | ||
| findAll | find a string within a string and produce a list if indicies | ||
| proper | take a string, split on spaces, normalize white space, turn every string into a camel case word, join together | ||
| initials | take a string, split on spaces, normalize white space, turn every string into a concat of just first letters capitalized | ||
| convex hull | a 2D version at first | ||
| matrix math | inverse, multiply, etc... | ||
| exact-math | math that doesn't overflow, and if it does, empty maybe | ||
| random+ | gaussian random + other statisitical random functions | ||
| even/odd | simple and fun functions | ||
| factorial | |||
| gamma factorial | https://en.wikipedia.org/wiki/Gamma_function | ||
| color | hsv/cmyk and a color typing library |
Web management
The online web portal needs a lot of work to be useful. The web portal should be upgraded to provide a manager view along with tools to get started along with steps to make progress.
| project | IP | milestones/description |
|---|---|---|
| render-plan | Render and explain the deployment plan | |
| render-routes | Render and explain the routing including both rxhtml and web instructions | |
| better-debugger | X | The debugger sucks |
| support fbauth | ||
| metrics | A metrics explorer | |
| service calls | A way to explore which documents are making which service calls and the results |
Contributer Experience
If your name isn't Jeff, then the current environment is not great.
| project | IP | milestones/description |
|---|---|---|
| shell script love | Improve the build experience outside of Ubuntu | |
| test MacOS | X | Work through issues with unit tests on MacOS and any productivity issues with the python build script |
| test Windows | X | Work through issues with unit tests on Windows and any productivity issues with the python build script |
| local mode | X | Adama should be able to run locally with a special version of Adama just for applications and local development |
| faster unit tests | Improve the testing to not leverage shared resources (stdout, cough) such that testing can be made parallel | |
| write documentation about structure | Write a document to outlining the high level mono-repo structure |
Performance/Capacity Issues
| project | IP | milestones/description |
|---|---|---|
| bubble view filtering | Bubbles should recompute only with related viewer changes happen rather than the viewer changed | |
| compressed tables | for tables that don't have deep subscriptions, let's compact records | |
| table-paging-{disk/db} | for tables that don't have deep subscription and stale data, let's introduce an offload database for caching | |
| java-compiler-service | instead of every adama instance compiling java, let's cache some byte code and maybe offload to an isolated service |
Language
The language is going to big with many features!
| project | IP | milestones/description |
|---|---|---|
| index-tensor | Tables should be indexable based on integer tuples. Beyond efficiency, language extensions can help work with tables in a more natural array style (think 2D grids) | |
| index-graph | Tables should be able to become hyper graphs for efficient navigation between records using a graph where edges can be annotated (this maps) | |
| full-text-naive | X | string =? string is a full text operator that is naive |
| full-text-index | introduce full indexing where records describe a rich query language | |
| dynamic-order | introduce a special command language for runtime ordering of lists | |
| dynamic-query | introduce a special language for queries to be dynamic | |
| math-matrix | The type system and math library should come with vectors and matrices out of the box | |
| 2d-primitives | circle, rectangle | |
| xml support | Convert messages to XML | |
| metrics emit $num; | X | The language should have first class support for metrics (counters, inflight, distributions) |
| metrics emit $string; | The language should support emitting tags with metrics to help shred and classifiy metrics | |
| auto-convert-msg | the binding of messages can be imprecise, need to simplify and automate @convert primarily for services | |
| bubble + privacy | X | Add a way to annotate a bubble with a privacy policy to simplify privacy logic |
| privacy-policy caching | X | instead of making privacy policies executable every single time, cache them by person and invalidate on data changes |
| table-protocol | introduce a way to expose a table protocol for reading and writing tables via a data-grid component | |
| sum/bag types | a sum type is going to be a special type of message | |
| auto-convert | auto convert messages to dynamic | |
| normalize messages | messages of the same structure should auto convert | |
| proper-lambdas | X | I should be able to accept functions as argruments to other functions |
| extension methods | Extend every message/record based on a structural pattern | |
| message filtering | Apply rules for parsing messages like "trim/lowercase" to help ensure only valid data enters system | |
| message aborts | Apply simple rules to reject messages that are invalid | |
| decimal type | for arbitray rationals |
Notes on bag type
enum E {Aa, Ab, B, C}
bag<E> B {
A* {
int x;
}
B {
int x;
int y;
}
C { }
}
The bag creates a record with the union of all fields along with various along with a virtual type for each instance which maps to the appropriate subset. We can derefence it via a match
B my_bag;
#sm {
match B as o {
A* {
o.x = 123;
}
B {
o.x = 42;
o.y = 7;
}
C {
}
}
}
Implicitly a bag has a type of the enumeration, and ingestion would be the way to set the type along with parameters.
my_bag <- {type: E::Aa, x: 42};
This will typecheck that the bag has everything needed and will clear other fields out. This is all sketch work, but the key design goal is to provide some degree of compact representation of data based on the kind of a thng.
Infrastructure - Protocols
For integration across different ecosystems, there are more protocols to bridge gaps.
| project | IP | milestones/description |
|---|---|---|
| mqtt | X | (1) Write design document how to adapt Adama to MQTT, (2) Build it with TLS, (3) Built it with plain-text |
| sse | (1) Write design document how to adapt Adama to Server-Sent Events, (2) Build it with TLS |
Infrastructure - Enterprise data
| project | IP | milestones/description |
|---|---|---|
| smaller deltas | (1) Define a log format that leverages binary serialization and compacts field definitions, (2) convert JSON deltas to binary in the logger to measure impact (throughput and latency), (3) leverage format upstream to minimize future network | |
| healing log | Implement a log data structure that can heal (anti entropy) across machines using Adama's network stack | |
| raft | Implement raft leader election and log append using Adama's network stack | |
| control plane | (1) Manual definition of raft shards definitions, (2) automatic machine management |
Infrastructure - Multi-region & massive scale
At some point, Adama is going to be at the edge with hundreds of nodes across the world.
| project | IP | milestones |
|---|---|---|
| diagram | X | diagram the usage of the database in the adama service |
| billing | X | have billing route partial metering records to billing document ( and globalize ) |
| proxy-mode | X | proxy the WS API from region A to region B (or global important services ) |
| remote-finder | X | extend WS API to implement a Finder for region A to do core tasks (or globalize) |
| finder in adama | X | Turn core service into a finder cache for web tier |
| region-isolate | Allow regions to have storage for local documents | |
| capacity-global | globalize capacity management | |
| test-heat-cap | validate when an adama host heats up that traffic sheds | |
| test-cold-cap | validate when an adama host cools off that traffic returns for density | |
| cap-config | make high/low vectors dynamic configurable | |
| ro-replica | (1) introduce new observe command which is a read-only version of connect, (2) have web routes go to an in-region replica | |
| reconcile | X | every adama host should be lazy with unknown spaces and also reconcile capacity if it should redeploy (due to missed deployment message) |
| space-delete-bot | make run only in the global region | |
| dead-detector | only run in global region | |
| leader-election-overlord | instead of a single host, get leader election in place and have one adama assign work to other adama instances | |
| all-make-target | instead of overlord making targets, have every adama instance expose a targets file | |
| monitoring | instead of using a local prometheus, let's use a service | |
| gc-2.0 | garbage collection should probably run on adama | |
| finish global CP | X | Adama is going to have a primary region with a control plane proxy to DB |
| write clients for global CP | X | wrap SelfClient to talk to Adama control region |
| e2e region tests | rethink the testing strategy to create a global multi-region foot print in unit tests (maybe with a customized runner) |
Infrastructure - Core Service
Adama is a service.
| project | IP | milestones/description |
|---|---|---|
| env-bootstrap | automatic the memory and other JVM args | |
| third-party replication | X | the language should allow specification of a endpoint to replace a piece of data to on data changes. This requires maintaining a local copy in the document along with a state machine about status. The tricky bit requires a delete notification. There is also the need to load every document on a deployment. |
| replication-search | provide a "between document" search using replication tech | |
| replication-graph | similar to search, replicate part of the document into a graph database | |
| metrics | X | documents should able to emit metrics |
| fix-keys | X | document keys are stored with both private and public keys, and this is really bad; we should only store the public key and version the keys along with an expiry (core work done, need to remove old code) |
| op-query-engine | X | a tool to debug the status of a document live |
| portlets | maybe part of replication, but a subdocument that can emit messages that are independent subscriptions (for SSE/MQTT) and for Adama to consume | |
| adama-actor | X | implement Adama as a special first class service |
| twilio-service | implement twilio as a first party service | |
| stripe-service | X | implement stripe as a first party service |
| discord-service | implement discord as a first party service | |
| slack-service | implement slack as a first party service | |
| http-service | study postman and design a generic HTTP service for third party integration | |
| results-stream | figure out how to ensure deliveries can overwrite prior entries | |
| portlets - passive net | if we express the desigre for a result to hold the stream results for a foreign document's portlet then this creates a graph such that documents need to be reloaded. that is, we need a persistent subscription | |
| firebase - notifications | we should be able to send notifications | |
| document filter | X | instead of relying on privacy and wasting compute, a viewer should be able to opt into which fields to view. |
Infrastructure - Web
Adama is a web host provider of sorts!
| project | IP | milestones/description |
|---|---|---|
| web-async delete | X | allow DELETEs to contain async calls |
| web-async get | X | allow GETs to contain async calls |
| request caching | X | respect the cache_ttl_ms |
| doc auth - expiry | infer cache_ttl_ms as an expiry for doc auth | |
| asset transforms | implement some basic asset transforms | |
| web-abort put/delete | X | web calls that write should support abort |
| @context | X | ensure web operations can access context |
| web-metrics | add an API for the client to emit metrics | |
| add auth for web | the principal for web* is currently @no_one; it should be a valid user | |
| build delta accumulator | slow clients may be get overwhelmed, the edge should buffer deltas and merge them together |
Infrastructure - Overlord
Overlord is how the fleet is managed and aggregator.
| project | IP | milestones/description |
|---|---|---|
| canary | for testing the service health and correctness; overlord should maintain a constant state of various high-value API calls | |
| operationalize-super | the "super" service needs a secure environment | |
| ui for query | dynamic queries | |
| billing-send | X | Simplify the billing engine and remove the overlord need |
| ntp | look into time sync |
RxHTML
RxHTML is a small set of extensions to allow HTML to be dynamic on the fly. The spiritual question is "what minimal number of things does HTML need to build apps?"
| project | IP | milestones/description |
|---|---|---|
| headwindcss | Port tailwindcss to Java for vertical control | |
| components | X | Bring clarity for single javascript extentions for new controls |
| time | X | Custom component for selecting a time of day (Blocked on components model) |
| date | X | Custom component for selecting a date or a date range (Blocked on components model) |
| color | X | Custom component for selecting a color (Blocked on components model) |
| graph | Custom component with rich config to visualize graphs | |
| server-side | Create a customized shell for each page such that server side rendering allows faster presence | |
| convert-react | Convert the RxHTML forest into a complete React app | |
| gc | figure out if there is still a bug with "rxhtml fire delete" isn't cleaning up pubsub | |
| remove-col | remove the rxhtml column from the spaces column and move into document; #127 | |
| auto-ids | A big pain point in HTML is the pair bonding of label to input via id. | |
| typechecker | A tool to validate an RxHTML forest doesn't have issues | |
| ai-tester | A browser extension to walk and validate a site is working and collecting tracking tokens |
RxHTML - Mobile
| project | IP | milestones/description |
|---|---|---|
| capacitor | X | should be able to convert an RxHTML SPA to a mobile app |
| notification support |
Roslin (RxImage)
The vision is for a runtime just for games. See this post for more information
| project | IP | milestones/description |
|---|---|---|
| design document | Write a design document from Jeff's notes | |
| runtime-android | Implement a starting runtime for web using android | |
| gameboard demo(s) | Write a game board demo of various games | |
| runtime-web | Implement runtime for web using rust | |
| rxhtml-integ | Integrate runtime-web into RxHTML as a new component |
Saul (RxApp)
Similar to RxHTML, the question is how to build a minimal runtime for iOS and Android applications. Tactically speaking, we can use RxHTML with capacitor.
| project | IP | milestones |
|---|---|---|
| design document | design a simple XML only way to build Android applications using reactive data binding similar to RxHTML |
Future of Adama Documentation
I want to revamp both the main site and this book in one cohensive product rather than two distinct entities. Eventually, the book will simply be a set of redirects to the main site as they achieve glorious unity.
However, it's easy to get into the mode of building yet another engine blah-blah-blah, and instead I want to try something rather radical. Well, it's not that radical, but I want a great experience for developers.
Since I'm the inventor or RxHTML, I can extend it to do documentation and then make RxHTML better in one go as well. This document then is a plan for the engineering investments since I'm also trying to move away from quip. I want all my design documents in one place, and I want design documents linkable with documentation.
I also need to improve the content which I'll start here with a glorious outline.
Engine Improvements for RxHTML
The first thing is that instead of markdown, all content is going to be .rx.html and this summons many problems like: navigation, bandwidth, search, markdown. Finally, I want to support Adama as a first class citizen.
All this means I need a few higher level primitives and some new stuff, so let's talk about the pain points of using RxHTML for a large amount of content.
Navigation
Currently, navigation is a PITA in RxHTML because it's very low level at the moment which works for complex systems, but with a large volume of content...
<forest>
<template name="some-template-make-it-look-good">
<div class="some common css [group=g1]active[#]inactive[/]">
<b>Group 1</b>
<div rx:if="view:show_g1">
<a href="/some/path/to/content"
class="link clazz [current=this-content]active[#]inactive[/]">
Link to that content</a>
</div>
</div>
</template>
<page uri="/some/path/to/content">
<div rx:template="some-template-make-it-look-good"
rx:load="set:group=g1 set:current=this-content raise:show_g1">
... content ...
</div>
</page>
</forest>
At core, the above is how to build products that are very customizable, but it does get repetitive and I do like this core idea of content describing itself. So, if I can provide some new higher level primitives to simplify the above, then that's great.
Idea #1. Common templates by uri
<forest>
<template name="some-template-make-it-look-good">
<div class="some common css [group=g1]active[#]inactive[/]">
<b>Group 1</b>
<div rx:if="view:show_g1">
<a href="/some/path/to/more/content"
class="link clazz [current=this-content]active[#]inactive[/]">
Link to that content</a>
<a href="/some/path/to/content"
class="link clazz [current=more-content]active[#]inactive[/]">
Link to more content</a>
</div>
</div>
</template>
<common-page uri:prefix="/some/path"
template:use="some-template-make-it-look-good"
template:tag="div"
init:show_g1="true"
init:group="g1" />
<page uri="/some/path/to/content"
init:current="this-content">
... content ...
</page>
<page uri="/some/path/to/more/content"
init:current="more-content">
... more content ...
</page>
</forest>
This allows a way for the page to describe just the content, save a level of tabbing, and let the repetitive nature of group variables be made depend entirely on the uri. I like this, and it's a good feature! The emergent engineering work is:
- task: introduce init:$var="$constant" as part of the <page> element
- task: introduce <common-page> as a root element, update <page> to (1) wrap the children with a template (if template:use is present) with a div (or whatever template:tag is), (2) merge the init:$var="$constant"
Idea #2. Runtime explicit static objects
As of now, RxHTML has two "stream" of information:
- "data:" to pull information from the server
- "view:" to pull information from the view state
The repetitive nature is the current navigation structure is good for fine-tuning behavior, but it is a recipe for small mistakes and duplicate code. Instead, what if I introduce a third channel called static which contains a giant object of globally static data (which, maybe mutated?). Or, I could use the view channel to have a pre-populated object "view:static" which is then never sent to the server. The pros of introducing a new "stream" is a clean slate which can then be optimized around differently, but it's a lot of work which is con and will require touching a bunch of code. I'll think upon this matter more!
- Task: think about "new stream" versus "abusing view stream".
Idea #3. Compile time static objects with static templates
So, here, I add a preprocessor to the entire forest.
<forest>
<template name="some-template-make-it-look-good">
<div class="some common css [group=g1]active[#]inactive[/]">
<b>Group 1</b>
<div rx:if="view:show_g1" static:iterate="nav/g1/children">
<a href="%%{uri}%%"
class="link clazz [current=%%{id}%%]active[#]inactive[/]">
%%{name}%%</a>
</div>
</div>
</template>
<common-page uri:prefix="/some/path"
template:use="some-template-make-it-look-good"
template:tag="div"
init:show_g1="true"
init:group="g1" />
<page uri="/some/path/to/content"
static:path="nav/g1/children+"
static:set:name="Link to some content"
static:ordering="1"
static:invent:id
static:copy:uri
>
... content ...
</page>
<page uri="/some/path/to/more/content"
static:path="nav/g1/children+"
static:set:name="Link to more content"
static:ordering="2"
static:invent:id="current"
static:copy:uri
>
... more content ...
</page>
</forest>
Here, the goal is that each page describes itself and the construction of the object is done by pre-processing all the pages to build the static object which can be mutated by various attributes. I like this as it reduces the repetitiveness of building the navigation tree and also provides a better control over the entire produce experience. Now, at this time, navigation is the primary PITA where this repetitive behavior manifests, so I'm happy to strike a balance between niche and generic functionality.
This body of work has:
- introduce static:path=$object-path for single object introduction
- consider static[$label]:* for multi-object introduction
- introduce static:set:$name=$value for adding data into an object
- introduce static:copy:$name for copying an existing attribute into an object
- introduce static:invent:id=$name for inventing a viewstate id that is then set on rx:load
- introduce static:iterate for iterating over a path
- introduce static:scope for scoping into an object
- introduce static:if for testing a static value is true/false
The core body of work here is the idea of introducing a preprocessor which sounds fun!
Bandwidth
Since ultimately the documentation is a bunch of static content, expecting users to download ALL content in one bundle is insane! (Or an amazing benefit since it would work offline especially if all images were data:base64 encoded... food for thought) Worse yet, the way RxHTML constructs the DOM assumes a lot of reactivity, so it's downloading mostly static content to then construct the DOM in Javascript. It works, but it's not great.
The body of work here is to start optimizing for bandwidth ruthlessly!
Idea 4.
For existing applications, there is a body of work to identify static chunks that the DOM never touches, and then marks the children as static. This requires a preprocessor to see
<forest>
<page uri="/blah">
<div> BUNCH of HTML </div>
</page>
</forest>
and then annotate the div with
<forest>
<page uri="/blah">
<div static:content> BUNCH of HTML </div>
</page>
</forest>
such that once the div is created to use innerHTML. As an isolated experiment, this is useful to build an test with current products to measure bandwidth reduction. In the context of a tremendous volume of static context, this isn't sufficient.
Idea 5. Ultimately, a major refactor is to make page loading dynamic. Fortunately, this was designed by nature of having templates and pages as the only top level primitives with static names.
The core algorithm is to do a dependency analysis on pages and templates to identify which templates are unique to a page and which templates are shared between pages. A naive approach would be to send all common templates on initial page and then hydrate pages as needed. Alternatively, pages could be bundled together in various ways for performance reasons. The core task however is to delineate between an initial page load versus a patch update, and then the initial page load would have an index of which pages are immediately available and indexes versus pages that need a request.
Now, care must be taken such that a version change in the forest (due to a deployment) would trigger an appropriate refresh of the entire page.
Thus, the initial page refresh would load the system, and then a special call (GET /~rxhtml) would have a special API such that the system would send (a) the uri to resolve, (b) the version of the system, (c) the relevant templates to the page that are already loaded. This new fetch would then check the version, and if a deployment happened would immediately return
This body of work has task working such as:
- build a dependency closure of all templates per page
- introduce a new way to pull a partial set of pages and templates on the fly
- allow developers to mark pages as together to bundle together (manual/nieve bundling)
- update rxhtml.js to support deferred pages to invoke the new pull methodology
Idea 6. Instead of having fancy-pants SPA, I simply disable page linking entirely and use RxHTML as a static generator. Frankly, this is the best short term option and the easiest to pull off.
This body of work has the task work:
- introduce a way to generate all pages statically similar Idea 5's dynamic initial page.
- write tooling in the CLI to spit it out
- add a way to annotate assets to have special Content-Type
Search
At core, I need to understand how Elasticlunr works and how to precompile indexing information.
Markdown
As part of the emergent pre-processing, I want to support a <static:markdown> tag which converts the markdown into HTML.
<forest>
<page uri="/blah">
<static:markdown>
# Title
## Subtitle
</static:markdown>
</page>
</forest>
Now, this poses some interesting thoughts about how this can feed the metadata for a side nav or the title of the document. We can leverage existing template behavior such the body is the default case and we expose rx:cases for title and outline. This is a fruitful experiment!
The body of work here is:
- introduce static:markdown to compile markdown into HTML during pre-process phase
- play with rx:case to allow extraction of a simple nav scheme, title, and maybe some tags?
- think about how to convert some jekyll aspects of the blog like header image, etc...
Adama Support
Now, the piece de resistance of why I want to improve RxHTML to power my documentation (beyond the potential of making it interactive), I want to leverage the Adama parser to type check my documentation so nothing is ever a mistake. Furthermore, I want to have documentation produce test cases for the test generator.
The trivial thing at play is to simply introduce a <static:adama> and then validate that it parsers.
<forest>
<page uri="/blah">
<static:adama>
#state {
// blah
}
</static:adama>
</page>
</forest>
However, an alternative mode is to ensure that all <static:adama> combine together to parse and type collectively. This allow a linear narrative, but narrative can be deception as I may also want to provide an outline and update code to tell a story and encourage patching. This is where the job becomes more intense, so I think about introducing a <fragment> tag with a name attribute.
<forest>
<page uri="/blah">
<static:adama>
#state {
<fragment name="foo">// blah</fragment>
}
</static:adama>
</page>
</forest>
This requires thought, but the spirit is that later chunk could fill that in
<forest>
<page uri="/blah">
<static:adama>
#state {
<fragment name="foo">// blah</fragment>
}
</static:adama>
<static:adama replace="foo">
t++;
</static:adama>
</page>
</forest>
This allows me to parse and type the entire assuming I linearize the <static:adama> into a stream A[0], A[1], ..., A[N].
I can then confirm that parse and type A[0], then A[0] + A[1] (where A[1] either appends or replaces a fragment), and so on. This would give me clarity on the user experience and if there are stupid errors.
Content Refactored
Now, beyond improving the engine, I also want to improve the documentation to give the best developer experience I can.
Major Sections and new outline (Draft)
- Documentation
- Introduction
- Start here
- How does Adama work?
- Core concepts
- Commercial licensing
- Starting on the cloud
- Download the tooling
- Setting up an account
- Creating a sample application
- Deploying and making changes
- Engineering team integration
- The developer sandbox
- #yolo mode
- Change management
- Executive team integration
- Metrics
- Access control policies
- Approvals
- Back up auditing
- Introduction
- Language Reference
- Access control
- Static policies
- Document access control
- Authentication
- Data, types, and privacy
- Privacy Policy
- Types
- (all types)
- Formulas
- Bubbles
- Message handling
- Defining
- Channels
- Internal Queue
- Workflow
- State Machine
- Single Workflow
- Cron Jobs
- Code to compute
- Control
- Assignment
- Native tables
- Procedures, functions
- Methods
- Language Integrated Query
- (more)
- Access control
- Standard Library
- Strings
- Math
- Statistics
- Principals
- Dates and times
- Platform API & SDK Usage
- Authentication
- Identities
- Default Policies
- Documents
- Web server
- Domain hosting
- Security
- Operations
- API
- (each method)
- Authentication
- Guides
- RxHTML
- Elements
- Attributes
- Recipes
- Examples and Recipes
- Showcase app
- Games
- Internet of Things
- Web sites recipes
- Pagination
Design Documents
Projection Map
Problem Statement
For developers, it is very convenient to create tables with many fields. However, fields have different mutation and read load which creates an imbalance since record changes propigate reactively as an atomic unit. That is, if you have a profile picture or name intermixed with a presence/last-activity flag, then invalidations will cause all profile picture/names lookups to happen excessively. The problem here is to provide developers an easy tool to cache and reduce the reactive pressure from fast-moving changes invalidating slow-moving changes.
Ultimately Solution
The ultimate solution would be to increase the memory demands on subscription and augment with some notion of which fields a thing depends on. However, this is exceptionally difficult with static analysis reactivity. The next version of the reactive system should rely entirely on runtime analysis which can exploit bloom filters which has a new set of trade-offs.
Candidate Solution 1
Here, we are going to introduce a "projection map" which allows slow moving data to be replicated out of a table into a map. We will assume the domain is a integer for the row id, so we propose this syntax for a new reactive type
record R {
public int id;
public string name;
public datetime last_activity;
}
table<R> tbl;
message Rslow {
string name;
}
function r_to_rslow (R row) -> Rslow {
return { name: row.name }
}
projection<tbl via r_to_rslow> tbl_slow;
Rules
- Private by default; since this is a conversion from a record to a message, we will not expose this to users by default to prevent an information leak scenario.
- Readonly by default; since this is the output image of a table and a function, the readonly keyword isn't needed nor welcome.
- The given table (i.e. tbl) must exist and have a record type compatible with the domain of the given function (i.e. r_to_rslow)
- The given function must exist and be pure (i.e. using 'function')
- The resulting type is then a map of integers to the range of the function
Invalidation Flow
The trick conversation is the invalidation flow as it is tricky. Ultimately, the spirit of the design is nice but we need to see how we actually save compute/reactive-pressure.
Hash as a Shield
The first path requires hashing to shield downward changes. Here, all primary key changes from a table to the projection map be unfiltered (i.e. duplicate signals) such that each table change results in evaluating the result. This result is then cached and hash, and if the hash changes, then invalidate associated subscriptions for the primary key. The big cost here is the unfiltered subscription flow combined with re-executions and then a hash (which currently uses sha384). The hashing alone makes this path not ideal, and the only plus is that compute would be minimal while the cached was used and invalidated.
New Settle Phase
Currently, settlement is a single pass which means invalidations generated during a settlement are not captured. Relying on the settlement phase would be unfortunate as the downchain consumers wouldn't be invalidated during execution (which almost suggests the need for a "soft invalidation" phase). That is, in the reactive chain of table --> map -> formula, if the invalidation signal stops at map until settlement, then using the formula is going to be a problem
OK, maybe the design is bad.
The introduction of the function requires a lot of work, so what if we simplify and use the existing reactivity all together!
Candidate Solution
Here, the projection map concept from one is going to leverage existing reactivity and table invalidations to shield down chain invalidation.
record R {
public int id;
public string name;
public string photo;
public datetime last_activity;
private formula simple = {name:name, photo:photo};
}
table<R> tbl;
projection<tbl.simple> tbl_slow;
Rules
- Private by default; since this is a conversion from a record to a message, we will not expose this to users by default to prevent an information leak scenario.
- Readonly by default; since this is the output image of a table and a function, the readonly keyword isn't needed nor welcome.
- The given table (i.e. tbl) must exist and have a record type compatible with the domain of the given function (i.e. r_to_rslow)
- The field (i.e. simple) must exist within the record
This new design is nicer in that it has less stuff and is more powerful (as it can leverage readonly procedures), so let's look at the important aspect!
Invalidation Flow
When the projection map learns of a row changes, it will simply provide a proxy of the id to the given field (which may be a formula). Here is where we can leverage the reactivity of the field to service us as we have to contend with three types of events:
- when a record is created -> send invalidation
- when a record is deleted -> send invalidation
- when the field is changed -> send invalidation
In the case of the simple field, the last_activity will only invalidate that the record changes which does nothing to name which then in terms does nothing to simple. So, simple will only change when name or photo changes. The map here is a way to skip the entire record changing allowing read/invalidation pressure to only be on the map.
Replication
The design of replication is such that some message needs to be replicated to another service which is expressed via the syntax within the document or a record definition.
replication<$service:$replicationMethod> $statusVariable = $expression;
This signals that the given expression should be replicated to the intended service on the given method. It is the responsibility of the service to define how replication is made idempotent as replication ought to happen every time the expression changes (with some operational knobs to limit and regulate replication, of course). This feature requires careful design such that the third party service is kept in sync. However, an element that will not be discussed is the operational side around changing either $service or $replicationMethod. Those will be considered out of scope for now.
As an example service, consider a search service to provide cross-document indexing. This service implementation can pull information from $expression along with the space and key name to define an idempotent key. That is, whenever the $expression changes, we will need recompute the idempotent key.
idempotentKey = deriveIK($expressionValue, $space, $key)
This key is then used against the service to ensure retries don't recreate new entries as we expect failures to happen for a multitude of reasons. The service then has two primary async interfaces to implement: PUT($idempotentKey, $expressionValue) and DELETE($idempotentKey). A tricky element at hand is handling idempotent key change, and the way to handle it is to issue a delete against the old $oldIdempotentKey prior to putting a new $newIdempotentKey
As such, this requires a persistent state machine which will embed within the document to keep track of the state. We will call this RxReplicationStatus.
Deriving the state machine
We have to model the state machine such that:
- the key may change at any time
- the value may change at any time
- we expect and respect the other service may be unreliable (non-zero failure rates) and non-performant (high latency)
- we only want one operation outstanding at any time for any single replication task
- failures may happen within and across hosts (i.e. a request is issued, machine failures, another request starts on another machine)
So, we start by defining an intention (or plan) of what needs to happen based on the current state. The operations at hand are PUT and DELETE, so part of the state machine is going to be (1) a copy of the key that is being interacted with remotely and (2) the hash of the compute expression. We are going to use a simple poll() model such that we can write a function to poll the state machine.
public void poll(...) {
// inspect the state of the world to create a new intention
// compare that intention to the the current action taking place
}
This is sufficient to create an intention as we will compute (newKey and newHash) to compare against the existing key and hash.
| key | hash | intention |
|---|---|---|
| null | - | PUT |
| != null && newKey == null | - | DELETE |
| == newKey | != newHash | PUT |
| != newKey | - | DELETE |
| == newKey | == newHash | NOTHING |
This intention is a goal, but due to high latency we need to model what is happening concurrently as either (1) nothing is happening against the remote service, (2) a PUT is inflight, (3) a DELETE is inflight. Thus, we model what is currently happening via a finite state machine.
| state | description | suspect remote key is alive | serialized as |
|---|---|---|---|
| Nothing | Nothing is happening at the moment | key != null | Nothing |
| PutRequested | A PUT has been requested | true | PutRequested |
| PutInflight | A PUT is executing at this moment on the current machine | true | PutRequested |
| PutFailed | A PUT attempted execution but failed | true | PutRequested |
| DeleteRequested | A DELETE has been requested | true | DeleteRequested |
| DeleteInflight | A DELETE is executed at this moment on the current machine | true | DeleteRequested |
| DeleteFailed | A DELETE attempted execution but failed | true | DeleteRequested |
Each state has a serialized state which requires modelling disaster recovery since the transient network operation will be lost during a machine failure. It is unknown if the network operation completed, so we need to try again on the new machine. This will require bringing $time as part of the state machine such that we can ensure the PUT and DELETE time out for a retry. At this point, the state machine has (1) state, (2) key, (3) hash, (4) time.
There is also a need for a transient boolean executeRequest to convert PutRequested to PutInflight and DeleteRequested to DeleteInflight. This boolean is responsible for executing the intended network call and allows us to implement the timeout. The service then must define a timeout such that a stale PutRequested can be converted to PutInflight This does require a new state machine operation called committed which we examine here.
public void poll(){
//..
if(state==State.PutRequested){
if(!executeRequest&&time+TIMEOUT<now()){
executeRequest=true;
}
}
}
public void commited() {
// ..
if(state==State.PutRequested && executeRequest) {
executeRequest = false;
state = State.PutInflight();
put(...);
}
}
This committed() phase is executed once the document's state is durable. Breaking up the PutRequested and PutInflight allows for the intention against the remote service to be durably persisted to allow recovery. We must do this so leaks don't happen.
The emergent state machine of what is happening right now is:
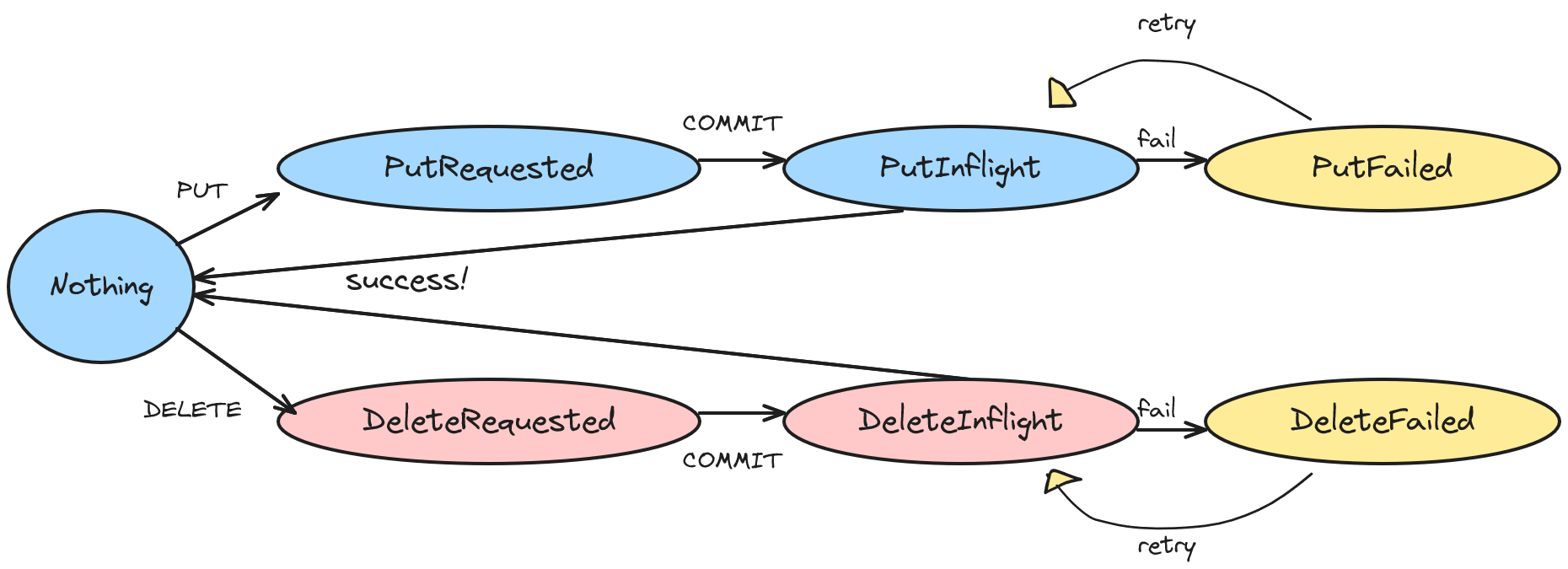
Finally, the goal is to cross the intention with the state.
| state | intention | behavior |
|---|---|---|
| Nothing | PUT | transition to PutRequested and capture the key, hash, time |
| PutRequested | PUT | do nothing |
| PutInflight | PUT | do nothing |
| PutFailed | PUT | do nothing, if key == newKey, capture hash and the new value |
| DeleteRequested | PUT | do nothing |
| DeleteInflight | PUT | do nothing |
| Nothing | DELETE | transition to DeleteRequested and capture the key, time |
| PutRequested | DELETE | do nothing |
| PutInflight | DELETE | do nothing |
| PutFailed | DELETE | do nothing |
| DeleteRequested | DELETE | do nothing |
| DeleteInflight | DELETE | do nothing |
| DeleteFailed | DELETE | do nothing |
Handling PutFailed and DeletedFailed
In both instances, these are bad but DeletedFailed is potentially catastrophic.
Ultimately, we are going to embrace a philosophy of infinite retry with a relaxed exponential backoff curve. That is, we want a reasonable and aggressive expontential backoff for the first few seconds, then it gets slower and slower faster and faster to reach a terminal window of 30 minutes to an hour.
Since the time between attempts during a failure may be intense, we ask if we can short-circuit the process when the $expression changes. If the key is stable, then we augment the above table to pull a new value during PutFailed.
Scenarios handling
Key Changed
When a key changes, a delete will be issued which when successful will transition to Nothing. The Nothing state will trigger a PUT.
Value Changes
When the value changes, this will be detected and trigger a new PUT
Poor Service Reliability
Infinite retry and expontential backoff will provide eventual synchronization assuming no poison pills. The platform will monitor for poison pills.
Poor Service Latency
Rapid changes will change only the intention while the remote service is working. The state machine ensures only one action happens against the remote service.
Machine failure
If a machine failures, then the document will be resumed on a new machine. The timeout value is used to create a period of time to not touch the remote service. As such, the old machine, if it comes back to life then there is a problem. However, future data service will require Raft thus ensuring the committed() signal is never generated on an old machine for old documents.
Maximizing Availability and Durability
Purpose
Adama currently suffers from single host failures and potential windows (5 to 10 minutes) of data loss due to the design. Single host failures will result in documents being unavailable until operator intervention (12+ hours at the moment). This document outlines applying the established literature https://raft.github.io/raft.pdf to the Adama Platform.
Design Goals
The primary goal is to introduce replication to the data model used by Adama such that single host failures within a partition (1) do not impact availability, (2) allow near instant recovery from host failure (under 30 seconds), and (3) cause zero data loss.
Furthermore, we will assume that we wish to be able to split and join partitions to handle chaotic traffic; this speaks to partition design being rainbow striped such that a machine may be part of many partitions and data is bound to partitions rather than machines.
Non Goals
Partition management is a non-goal and we will assume a static config that is polled. This allows us to start with a generated one-time config at cluster stand-up. By using polling to determine membership, this allows operators to change the config and be adjusted live. This allows us to skip how partitions are managed for now.
50,000 foot view
The essential design is that we are going to preserve the monolithic design of Adama such that data is colocated on the existing adama compute node. The macro change is the introduction of partitions which form a durable state machine via RaFT. We rainbow stripe the partitions across machines as this allows heat to dissipate when heat induces a failure instead of a cascading fall over.
Each partition forms a sub-mesh within the fleet, so care must be taken to minimize the number of meshes a host is a member of; since this falls under partition management, we will ignore this and make the mesh construction lazy.
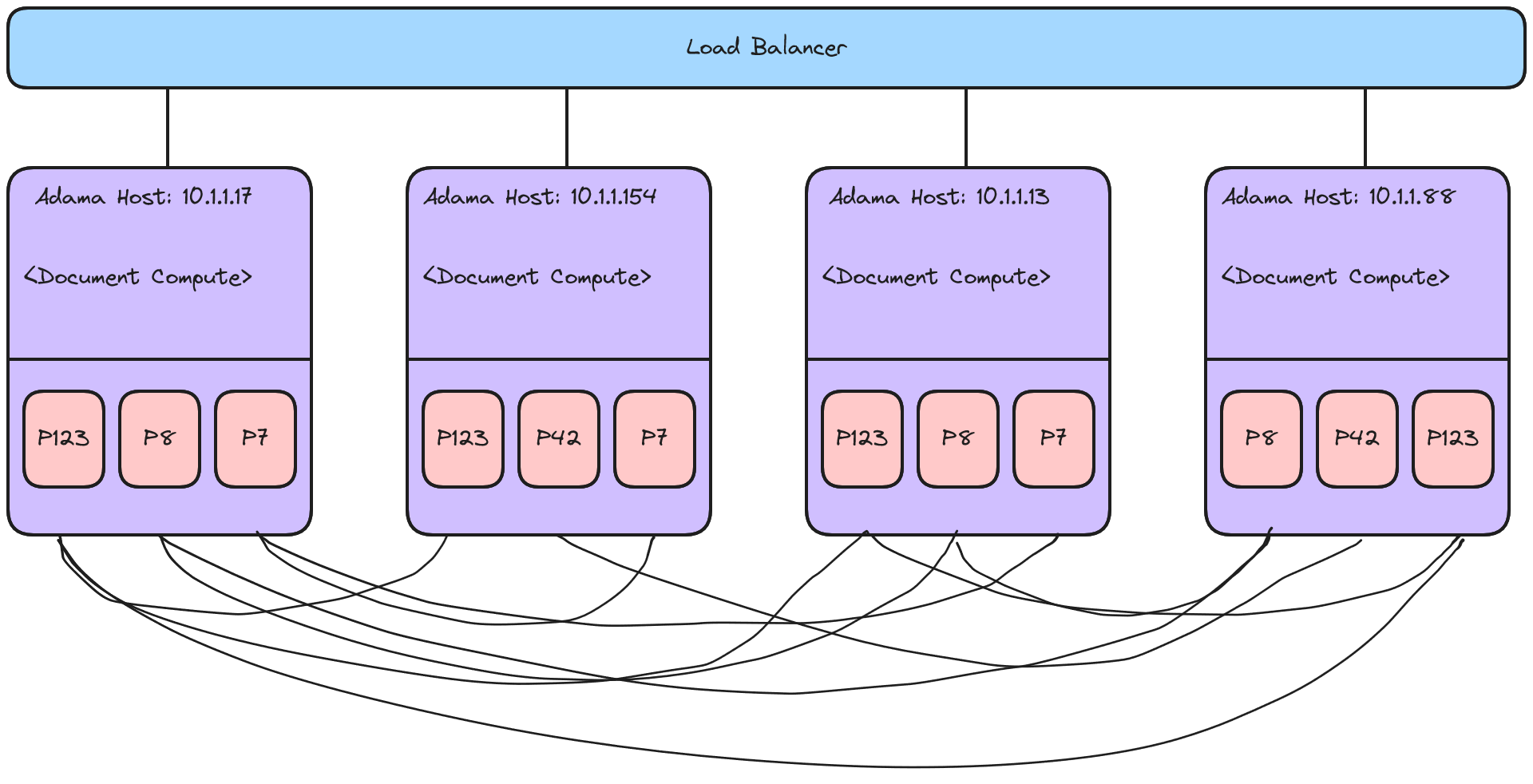
Diving into this requires addressing these questions: (1) What is the data model of each partition, (2) What novel aspects and implementation details are beyond the existing literature, (3) How will hosts react to leadership failures in both the load balancer and non-leaders, and (4) Preventing zombie leadership behavior.
Details
Data model with anti-entropy
We are going to exploit the co-location of Adama's compute with storage to infer that the storage burden per host is going to be substantially less than traditional storage engines and databases. The proof is simply noting that Adama's primary bottleneck is memory which is six orders of magnitude less than storage (32 GB vs 2 TB). If the average document size is 4KB, then this means 8.4 million documents will reside on a host at maximum. If each document key and metadata is bound by 512 bytes, then the maximum size of an index is 4GB.
Gossiping the entire index is not acceptable as it would take 32 seconds at 1 gbps. Instead, we utilize 64 partitions to segment the 4GB into 64 MB chunks. This allows us to smear the workload over time, but it doesn't reduce the total workload.
We reduce the workload by introducing a merkle tree per partition. Each partition at maximum would have 131K documents in it, so if we use 256 buckets then 512 documents are in a bucket. If each document has 512B of gossip metadata, then each bucket gossip results in 262KB of data exchange assuming no compression. At 1gbps, this means gossip of a single bucket would take 1 ms. Instead of a traditional hash tree, we can simply send all 256 buckets and their hashes for a rough cost of 8KB. The purpose of the merkle tree is that when nothing bad has happened, then repair is effectively free. And, should a repair be interrupted, the merkle tree allows resumption.
Gossip and the buckets allows the machine to determine when a document's log is either not present or behind. When a host detects a document is behind, it will pick a random peer and pull committed entries for the documents detected using the local sequencer to the peer's sequencer.
The burden of repair can then be studied operationally. For example, when a new host is introduced to the fleet then we can use the rainbow striped partitions to bring a partition online one at a time at 262KB overhead to detect new work. Since this is a new host, the entire partition needs to be rehydrated. If the average document size preserves 1,000 deltas and each delta is roughly the square-root of the document then we can guess the work load for a bucket is 32 MB at most. A full recovery of a bucket will take be roughly 250ms, and the recovery is tolerant of partial failures. Full partition recovery will take 16 seconds. Full machine recovery will take 17 minutes (32MB * 8.4 million) due to the logs, but here is where we can observe an interesting gotcha.
If each machine permits only 1 TB for log storage, then that permits only 32K (@ 32 MB/document) documents instead of 8.3M documents.
FUCK...
Thus, each partition would have 512 documents in it. And the merkle tree would have 2 documents in a bucket. This makes everything better, but the open question now is how does the overhead balance out.... hrmm
Novel aspects and implementation details
The big departure from traditional RAfT designs is breaking out the leadership write to healthy members (followers that are caught up) versus repairing a sick member (followers not up to speed) via anti-entropy. The primary reason to do this is simplifying the repair mechanism when leader writes start to fail and enable peers to contribute to recovery, and the repair mechicniams can leverage multiple machines easily.
Therefore, the role of RAfT is reduced to simply a durability buffer which ensures a consistent write to the gossip'd data structure. This means that when everything is going well, the write is spread to the follows perfectly and committed. When a leader detects a failure, it will revert and issue a catastrophic failure to the document. We want to minimize catastrophic failures
Leadership failures and recovery
Preventing Zombies
Maximizing Throughput
Purpose
Adama's ability to execute many concurrent network calls is impaired due to the transactional boundary (and the historical roots in board games). This means a high latency third party service will dramatically block progress on a document, and large delays can introduce quadratic workloads (which is expensive for customers and slow).
Design Goals
The primary goal is to introduce a new way of modelling service invocations that are high performance enabling many concurrent invocations and operate at transaction-line-rate (the maximum commit rate to disk).
This induces a requirement that this new mechanism is going to live across two transactions: (i) the transaction that initiates a service method, and (ii) the transaction that represents the completion of the service method. Therefore, we take the burden that this will run at no more than half the transaction line rate.
Non Goals
The existing async system can be improved in a few ways, but these are considered nice to haves since asynchronous transactional memory is an extremely difficult problem. This document is focused purely on introducing a new way to do async calls.
7,500 foot view
We will introduce a new language primitive called "pipeline". The key idea is to create a queue of pending work that operates outside the document's main thread. The queue fundamentally needs to contain (1) the service name, (2) the method to invoke, (3) the calling principal, (4) the input message, (5) some closure context, and (6) a handler.
The closure context is important, so we will have a message type be used. For example,
message MyContext {
int user_id;
int invoice_id;
}
represents some context that is relevant the asynchronus call but not in the call. This context is useful for back pointers and connective ids that are passed from the caller to the handler. We will extend every existing service method to be a pipeline-capable invocation, and then the missing language primitive pipeline has a syntax of
pipeline<service::method> pipeline_name (MyContext context) {
// @request and @response are available
// @who is also available
}
This basic syntax provides the handler code such that:
(1) the bound service is identified to be extended,
(2) the method to invoke is identified,
(3) the calling principal is represented idiomatically as @who,
(4) the input message is available via the new @request constant,
(5) the output of the response is available via the new response constant,
and (6) the handler is the associated code.
Invocation then happens as an extension to the given service. For example,
pipeline<myphpservice::write> myownpipe (MyContext context) {
// do stuff
}
channel foo(SomeMessage m) {
myphpservice.myownpipe(
@who,
/* input */ {id:m.id},
/* context */ {user_id:m.user_id, invoice_id:42}});
}
Furthermore, this invocation provides sufficient information to enqueue the work.
However, this work is limited to a linear topology:
So, we will some clarity on this may extend into more (a) complex call chain hierarchies. We also need to contend with (b) handling failures in a responsible way. (c) Operational safety is a prime concern since Adama plus a queue can be a denial of service attack provider if we don't handle this well.
Details
Complex call chains and rich topologies
I suspect that the pareto-major case is introducing batching to allow for scatter and collect pattern ala:
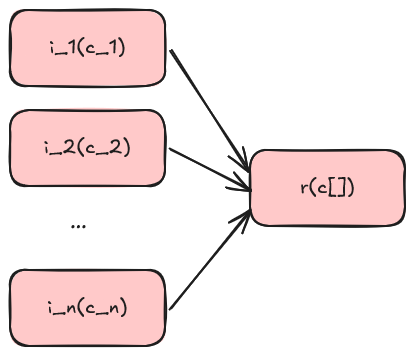
This happens when N requests are queued and then after those N things have processed, some code is ran. The pareto-minor case is also worth considering as it may be desirable to do some weaving where results feed into other methods.
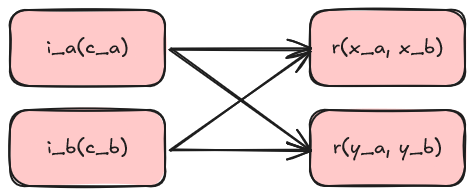
This speaks to the need that the return from the pipeline invocation is some kind of future and work on futures can be queued up as well using a compute graph. Perhaps, we can introduce a new type of pipeline that doesn't operate on services.
pipeline<future<Response1>, future<Response2>[]>
future_pipe_method(MyContext c, Response1 r1, Response2[] r2) -> BatchResponse {
// do stuff on the futures
}
The invocation of future_pipe_method is then a traditional method invocation:
channel foo(Yo y) {
var f1 = service1.foo1(...)
var f2 = service2.foo2(...);
var fr = future_pipe_method({/*context*/}, f1, [f2]);
}
This code then is 100% synchronous in defining a computational graph of various transactions that (1) mutate the document, (2) build complex call chain hierarchies which execute in a predictable manner.
Handling failures
The proper way to contend with failures would be to make @response a maybe and introduce @failure constant.
Operational excellence
Since Adama owns the queue, it can coordinate with the service implementation to define the maximum number of inflight operations per machine and this can be further controlled using cross-machine gossip to rate limit service. This is, however, a broad topic.